Core Judgment
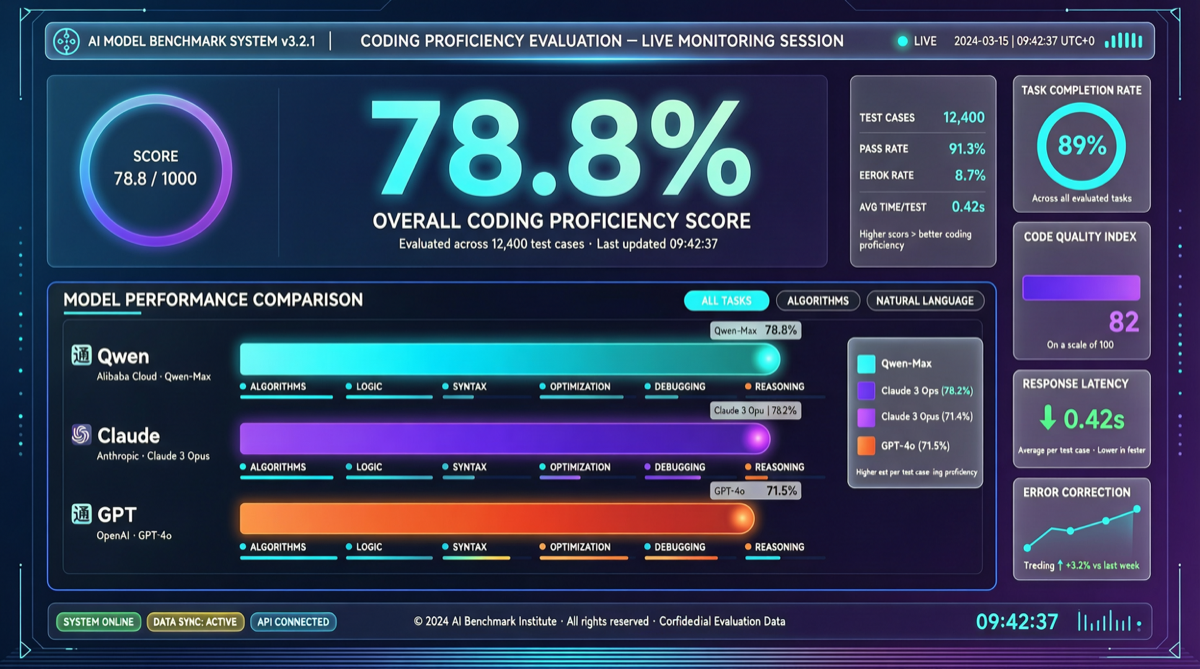
Qwen3.6-Max-Preview scored 78.8% on SWE-bench with a 1M token context window — what does this number mean? It means the "underlying model moats" for coding tools like Claude Code, Cursor, and GitHub Copilot are rapidly evaporating.
Someone on X put it bluntly: "Next differentiation won't be raw capability — it'll be reliability, how gracefully it fails, and how well it handles edge cases under load."
This isn't Qwen's solo act. During the same period, GPT-5.5 scored 58.6% on SWE-bench Pro, Claude Opus 4.7 scored 64.3%. Qwen3.6-Max-Preview leads with a significant margin.
Data Comparison
| Model | SWE-bench | SWE-bench Pro | Context Window | Pricing |
|---|---|---|---|---|
| Qwen3.6-Max-Preview | 78.8% | — | 1M tokens | China cloud vendors |
| Claude Opus 4.7 | — | 64.3% | 200K | $15/$75 per 1M |
| GPT-5.5 | — | 58.6% | 1M | $180/M (Pro) |
| Gemini 3.1 Pro | — | — | 1M | $12/M |
| Qwen3.6-Plus | 78.8% | — | 1M | Alibaba Cloud |
Sources: X/Twitter community summaries, official model announcements
Note: Both Qwen3.6-Max-Preview and Qwen3.6-Plus reported 78.8% on SWE-bench. This may reflect the same benchmark under different naming, or indicate that the 3.6 series has achieved a uniformly high coding capability floor.
Three Key Signals
1. Coding Models Enter "Oversaturation" Zone
When SWE-bench scores approach 80%, the value of marginal improvement drops sharply. Going from 50% to 70% is a qualitative leap — the model can finally solve real repository bugs. But from 70% to 80%, it's mostly about covering long-tail cases, with far less impact on developers' daily experience than going from 30% to 50%.
In other words, the coding model capability race is entering a zone of diminishing returns.
2. 1M Context Becomes Standard
Qwen3.6-Max-Preview's 1M context window is no longer an "experimental feature" — it's a production-grade capability. This means:
- Entire large codebases can fit into context at once
- Agents can simultaneously view dependencies, test files, docs, and PR history
- Traditional "file-level" coding assistance will comprehensively upgrade to "repository-level" assistance
3. Chinese Models Enter the Top Tier
Qwen3.6 series (including the 27B local version and Max-Preview cloud version) uses a clear full-stack strategy:
- 27B: Runs on consumer hardware, local coding assistance, deploys with just 18GB RAM
- Plus: API cost-performance route, 78.8% SWE-bench
- Max-Preview: Flagship capability showcase, stronger tool use and Agent workflow reliability
This "full coverage" strategy makes Qwen competitive across different budgets and scenarios, not just leading in one niche.
Landscape Judgment
Future Differentiation Directions for Coding Tools
When underlying model capabilities converge, coding tool competition shifts to:
| Dimension | Description |
|---|---|
| Reliability | How the model behaves when it fails — silently outputting wrong code, or clearly communicating uncertainty? |
| Edge Cases | Handling niche languages, legacy codebases, non-standard build systems |
| Integration Depth | Seamless connection with IDE, CI/CD, code review workflows |
| Multi-Agent Collaboration | Not how strong a single model is, but how multiple Agents divide labor on complex tasks |
| Cost Control | 1M context isn't cheap — dynamic balance between quality and cost |
Actionable Advice for Developers
- Don't lock into a single coding tool — Qwen3.6-Max-Preview means you can switch between tools without losing much coding capability
- Learn practical 1M context usage — prompt strategy and token budgeting after putting an entire repo into context is a new skill
- Evaluate Agent workflow reliability — performance under load matters more than single benchmark scores
- Consider hybrid approaches — local 27B for daily assistance + cloud Max for complex tasks, optimal cost efficiency
What to Watch
Qwen3.6 series capability improvements don't exist in isolation. During the same period:
- Qwen Image 2.0 Pro ranked #9 in Text-to-Image Arena
- Community rumors of Qwen3.6-122B-A10B (MoE architecture) upcoming
- Alibaba continues investing in Agent infrastructure (Qwen Code Terminal Agent already released)
The 2026 AI competition has shifted from "who can make the best model" to "who can best integrate models into workflows." Qwen3.6-Max-Preview's 78.8% is a significant milestone — it declares that the coding model "arms race" is winding down, and the next phase of competition has already begun.