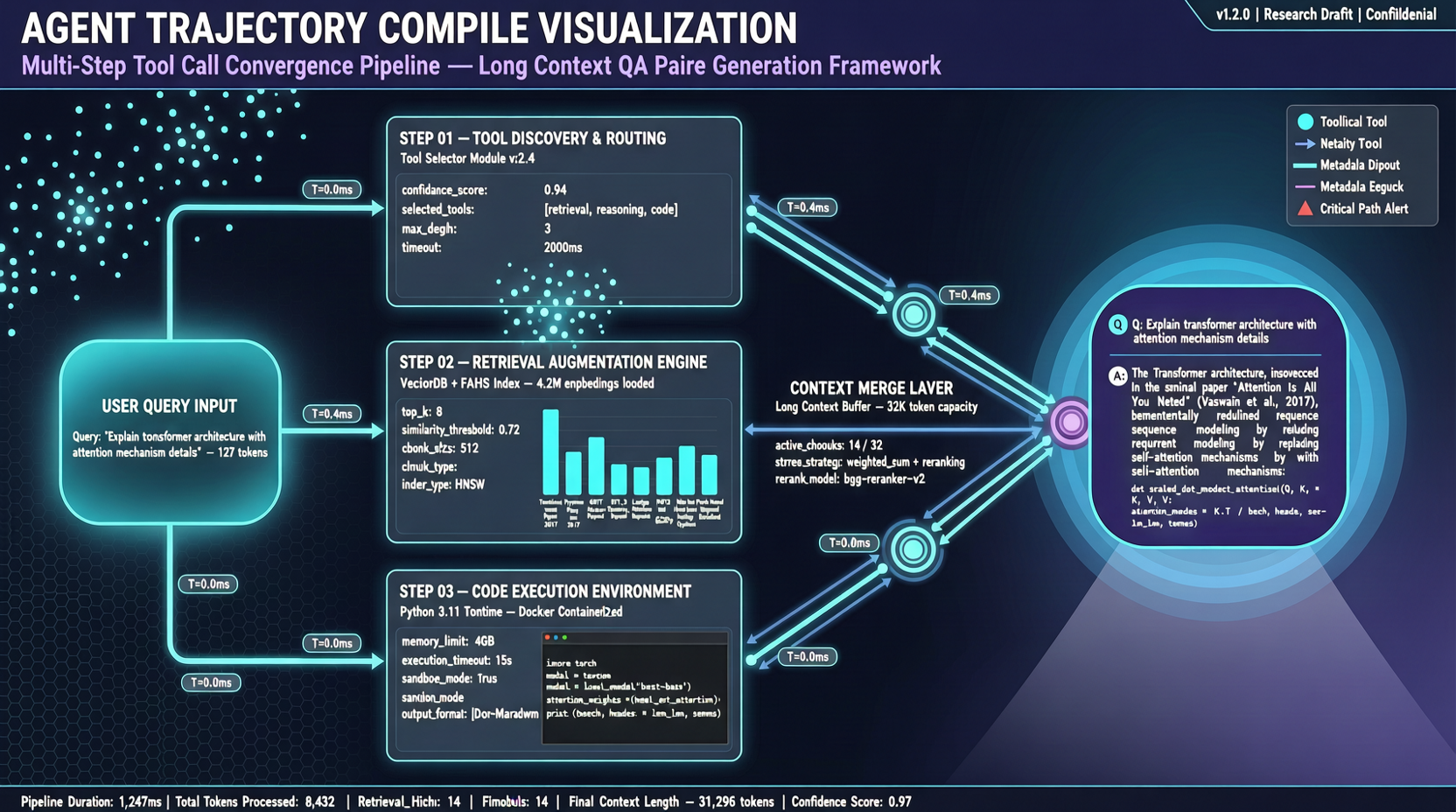
エージェントが問題を解決する方法:ユーザーが質問し、モデルがツールを呼び出してデータを取得、また別のツールを呼び出す……十数回のやり取りの後、ようやく十分な情報が揃って答えを出す。
しかし標準SFT訓練には盲点がある:各ターン内のツール選択のみを訓練し、ツールの応答をマスクして勾配更新から除外する。这意味着数十ターンにわたって蓄積されたすべての証拠——訓練時にすべて捨てられる。
ACC(arXiv:2605.21850、蘇启晟他、2026年5月21日)のアイデアは直接的:これらの軌道をQA対に「コンパイル」する。
コンパイルプロセス
生の軌道では、質問と答えの間に十数回のツール呼び出しと環境観察が挟まっている。ACCは元の質問 + すべてのツール応答 + 環境観察を結合して1つの長文脈QA対を作り、ツールなしで直接答えを見つけることをモデルに訓練する。
結果
Qwen3-30B-A3BでACC訓練後:
- MRCR(跨ターン共参照解決):68.3、ベースラインより**+18.1**
- GraphWalks(グラフトラバーサル):77.5、ベースラインより**+7.6**
この結果はQwen3-235B-A22Bレベルに迫る。30Bのパラメータ規模で、データコンパイル手法により長文脈推論で7倍大きなモデルに追いついた。
主要ソース:
- arXiv:2605.21850, ACC: Compiling Agent Trajectories for Long-Context Training, Qisheng Su et al., 2026-05-21