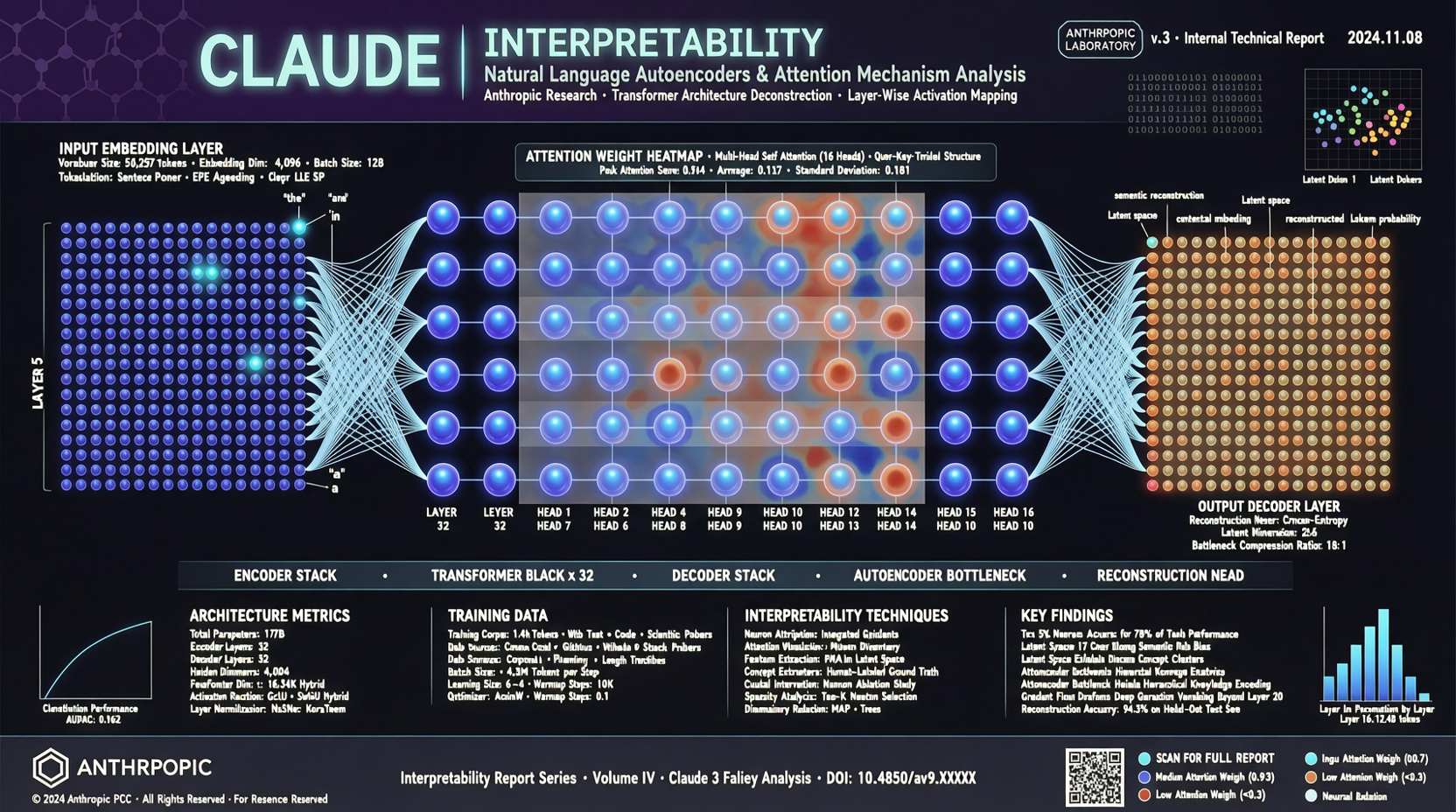
Claudeは言葉で話し、数字で考える。Anthropicは今、この両者を合わせたいと考えている。
5月7日、Anthropicの解釈可能性チームが少し「SF」風味の論文を発表した。Claudeの内部活性化状態——それらの高次元ベクトル、重み行列の数値——を人間可读の自然言語に直接翻訳するオートエンコーダーを訓練したのだ。
要約ではない。近似でもない。直接翻訳だ。
なぜこれをやるのか
大規模言語モデルの最大のブラックボックス問題は「何を言ったか」ではなく「なぜそう言ったか」だ。
Anthropicのアプローチは直接的だ。Claudeに「翻訳レイヤー」を取り付ける。このレイヤーはモデルの内部活性化シグナルを読み、対応する自然言語の説明を出力する。
技術詳細
核心はsparse autoencoder(スパースオートエンコーダー)。
重要な設計ポイント:
- 辞書サイズは数百万レベル。各次元が人間が理解できる概念に対応
- スパース性制約により、各活性化は少数の概念のみをトリガー
- トレーニングデータはClaudeの多くの内部層をカバー
論文は多くの意味のある概念を学習したと主張している。
信頼できるか
良いニュース:内部活性化をテキストに信頼して翻訳できれば、モデルデバッグとセーフティリサーチにとって巨大なツールになる。
ただし注意点もある:
第一に、「テキストへの翻訳」プロセス自体に情報損失がある。高次元活性化を自然言語に圧縮するのは100%忠実にはできない。
第二に、これらの「概念」はモデルが自動発見したものだ。自動発見された概念が本当に人間が理解するセマンティクスに対応するかどうか、さらなる検証が必要だ。
実践的な意味
一般ユーザーにとって、この論文に直接の製品価値はない。Claudeの次のバージョンで「思考プロセスを表示」ボタンを見ることはないだろう。
だがAIセーフティ研究コミュニティにとって、これは今年最も重要なツールの一つになりうる。
Claudeの「脳波」を翻訳する——とてもサイバーパンクに聞こえる。だがサイバーパンクなことは、たいていまず研究室で起きる。
主要ソース:Anthropic Research Blog (2026年5月7日), "Natural Language Autoencoders: Turning Claude's thoughts into text"