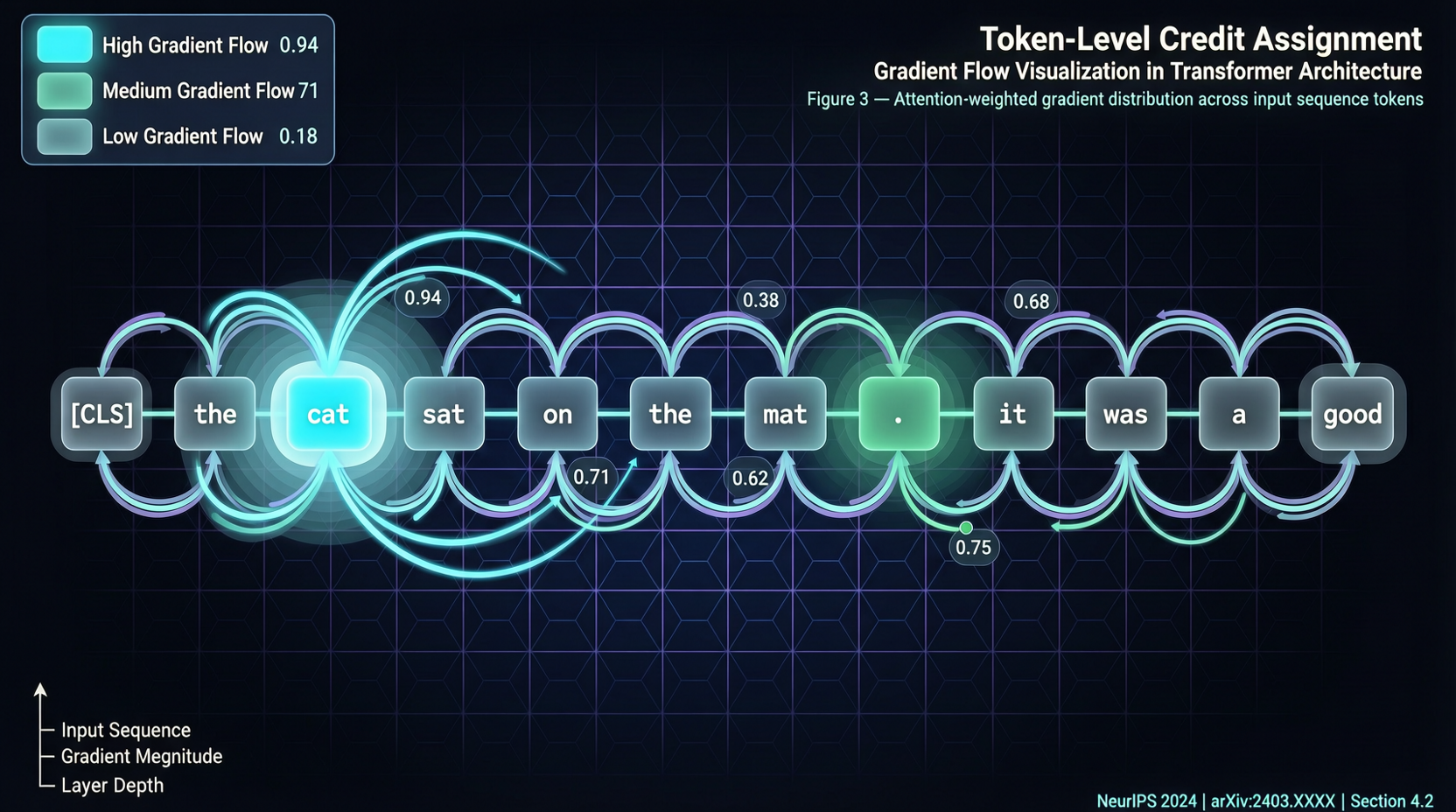
GRPOは軌道レベルの報酬をすべてのトークンに均等に分配する——個人の貢献にかかわらずチームボーナスを均等に分けるようなものだ。重要な洞察を書くトークンも、ピリオドを打つトークンも同じクレジットを得る。
DelTA(arXiv:2605.21467、Zhang Kaiyi他、中国人民大学/智源研究院、2026年5月20日)は、RLVRのポリシー勾配更新方向を線形識別器として再解釈するという、振り返ればシンプルだが本質的なことをやっている。
識別器視点
RLVR訓練中、モデルは同じ問題に対して複数の回答を生成する——高スコアのものもあれば低スコアのものもある。標準的なアプローチは、アドバンテージで重み付けされたすべてのトークン勾配を平均化し、「正のcentroid」と「負のcentroid」を計算し、更新方向をこれらを引き離すベクトルとする。
問題は、これらのcentroidが高頻度の共有トークン(フォーマット文字、一般的な接続詞)に支配されてしまうこと。良い推論と悪い推論を実際に区別できる少数のトークン——それらはかき消されてしまう。
DelTAは各トークンの「判別係数」を推定する:ポジティブとネガティブの回答を区別できるトークンには高い重みを、共有または判別力の弱いトークンには低い重みを与える。本質的に信号対雑音比を向上させている。
結果
Qwen3-8B-Baseでは、DelTAは7つの数学ベンチマークで最強の同規模ベースラインを平均3.26点上回った。Qwen3-14B-Baseでは2.62点。コード生成タスクとドメイン外評価でも汎化性が確認された。
正直に言うと、現在の数学推論ベンチマークでの2-3点の向上は「圧倒的」とは言えない——しかし、この論文の意義はスコアそのものにあるのではない。RLVR訓練メカニズムを理解するための新しいフレームワークを提供している:ポリシー勾配は暗黙的に判別を行っているということだ。
OPPOとの並行登場
興味深いことに、同じ問題に取り組む別の論文OPPO(arXiv:2605.21851)が同日に登場した。OPPOはオラクル信号を用いたベイズアプローチ、DelTAは識別器アプローチ。どちらも訓練されたバリューネットワークを必要としない。
このトレンドは注目すべきだ:フィールドが「GRPOは動くから次に進もう」から「なぜ動くのか、どこで失敗するのか」を問い始めるとき、RLVR研究はより深い段階に入る。
主要ソース:
- arXiv:2605.21467, DelTA: Discriminative Token Credit Assignment for Reinforcement Learning from Verifiable Rewards, Kaiyi Zhang et al., 2026-05-20