結論
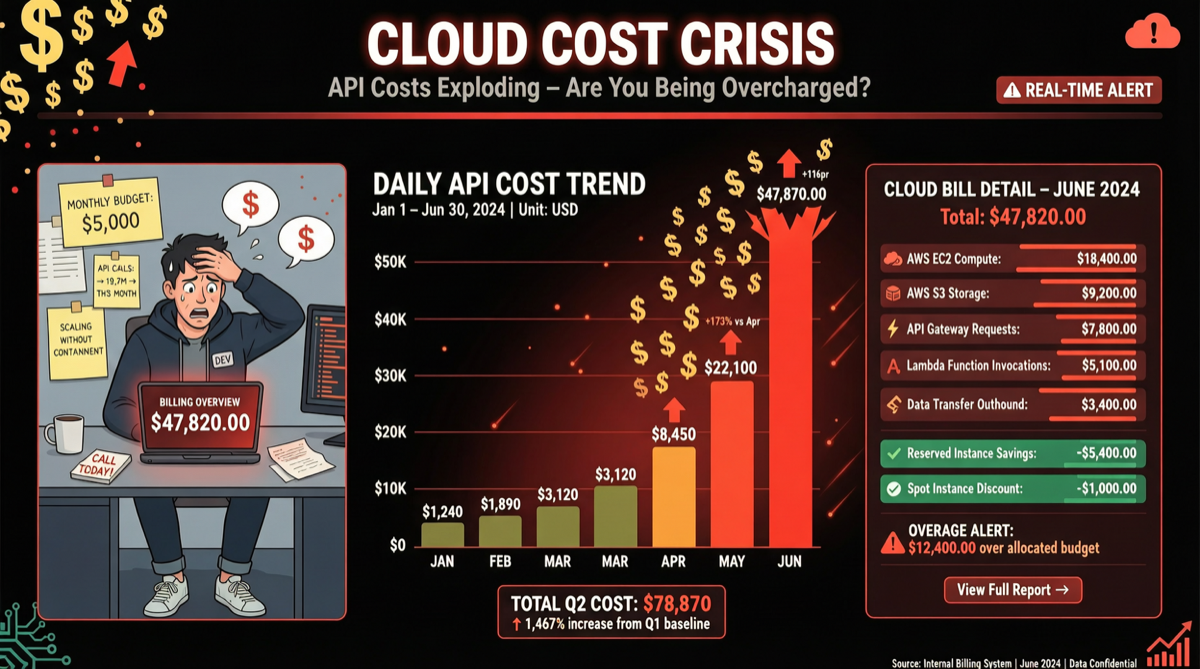
OpenAIはGPT-5.5 InstantをChatGPTのデフォルトモデルとしてリリースしましたが、API側の隠れたコストが表面化し始めています。OpenRouterの実測データによると:GPT-5.4と比較して、GPT-5.5のAPIコストは49-92%上昇しました。ただし、モデルは長いプロンプトシナリオで19-34%少ないcompletionトークンを生成し、値上げを部分的に相殺しています。
何があったか
GPT-5.5 Instantがオンラインに
OpenAIはGPT-5.5 InstantをChatGPTのデフォルトモデルとし、主要な更新内容は以下の通り:
- よりスマートで明確なレスポンス
- より温かみのある自然なトーン
- より簡潔なレスポンス(ついに!)
- 医学、法律、金融分野での事実性の強化
- より良いメモリとパーソナライゼーション
コストデータ:OpenRouter分析
OpenRouterはGPT-5.5とGPT-5.4のコスト比較分析を行いました:
| 指標 | データ |
|---|---|
| APIコスト上昇 | 49-92% |
| Completionトークン減少 | 19-34%(長いプロンプトシナリオ) |
| 実際の純コスト増加 | ワークロードによる |
コスト上昇とトークン効率のバランス
重要な発見:コスト上昇の幅がトークン減少の幅を上回っています。
具体的なプロンプトシナリオの例:
- GPT-5.4:コスト$1.00、出力1000トークンと仮定
- GPT-5.5:コストは$1.49-$1.92に上昇、出力は660-810トークンになる
正味効果:
- 最小上昇:$1.49 × 0.66 = $0.98(ほぼ横ばい、ただし出力品質は向上)
- 最大上昇:$1.92 × 0.81 = $1.55(実際のコスト増加55%)
結論:一部のシナリオでは、GPT-5.5の実際のコストはほぼ横ばいになる可能性があります(出力がより簡潔なため)。他のシナリオでは、コスト増加は依然として顕著です。
他のモデルとのAPI価格比較
| モデル | 入力価格 (/100万トークン) | 出力価格 (/100万トークン) | 定位 |
|---|---|---|---|
| GPT-5.5 | ~$10-15(推定) | ~$60-80(推定) | フラッグシップ、最高価 |
| Grok 4.3 | $1.25 | $2.50 | コスパの王 |
| Claude Opus 4.7 | 未公開 | 未公開 | フラッグシップ |
| Qwen3.6-Max | 低め | 低め | オープンソース高コスパ |
なぜ重要か
1. 「よりスマート」の隠れたコスト
AIモデルの能力向上には往々にしてコスト上昇が伴います。GPT-5.5の事実性と推論の改善は確かに価値がありますが、企業は定量化する必要があります:これらの改善は50-90%のコスト増加に見合う価値があるか?
2. 簡潔な出力の経済的価値
GPT-5.5は「つにより簡潔になった」——これはUXの改善だけでなく、コストの最適化でもあります。モデルがより少ないトークンで同じタスクを達成できれば、ユーザーは実際により少ない費用を支払います。
3. APIコストがモデル選択の重要な要素になりつつある
Grok 4.3が入力100万トークンあたり$1.25でトップクラスのパフォーマンスを提供している中、GPT-5.5の高価格は圧力に直面しています。市場は「パフォーマンス-コスト」の2次元意思決定モデルへ移行しています。
アクションアドバイス
現在GPT-5.4 APIを使用している場合
- 移行コストのテスト:代表的なプロンプトセットでGPT-5.5をテストし、実際のトークン消費と出力品質を比較
- 簡潔性に注目:GPT-5.5の出力が実際に短ければ、実際のコスト増加は予想より低い可能性があります
- ハイブリッド戦略の検討:単純なタスクにはGrok 4.3またはGPT-5.4を使用し、複雑な推論タスクにはGPT-5.5を使用
APIプロバイダーを選択している場合
- コスパ首选:Grok 4.3(入力100万トークンあたり$1.25)が現在最高のパフォーマンス-価格比を提供
- 品質首选:GPT-5.5は医学、法律、金融分野での事実性が最も強い
- オープンソース代替:Qwen3.6シリーズはローカルデプロイでゼロAPIコストを実現可能
コスト最適化戦略
- プロンプトエンジニアリング:GPT-5.5は簡潔なプロンプトによりよく応答します。プロンプトを最適化することでトークンを節約できます
- キャッシング:繰り返しリクエストにレスポンスキャッシングを使用
- モデルルーティング:タスクの複雑さに基づいて動的にモデルを選択