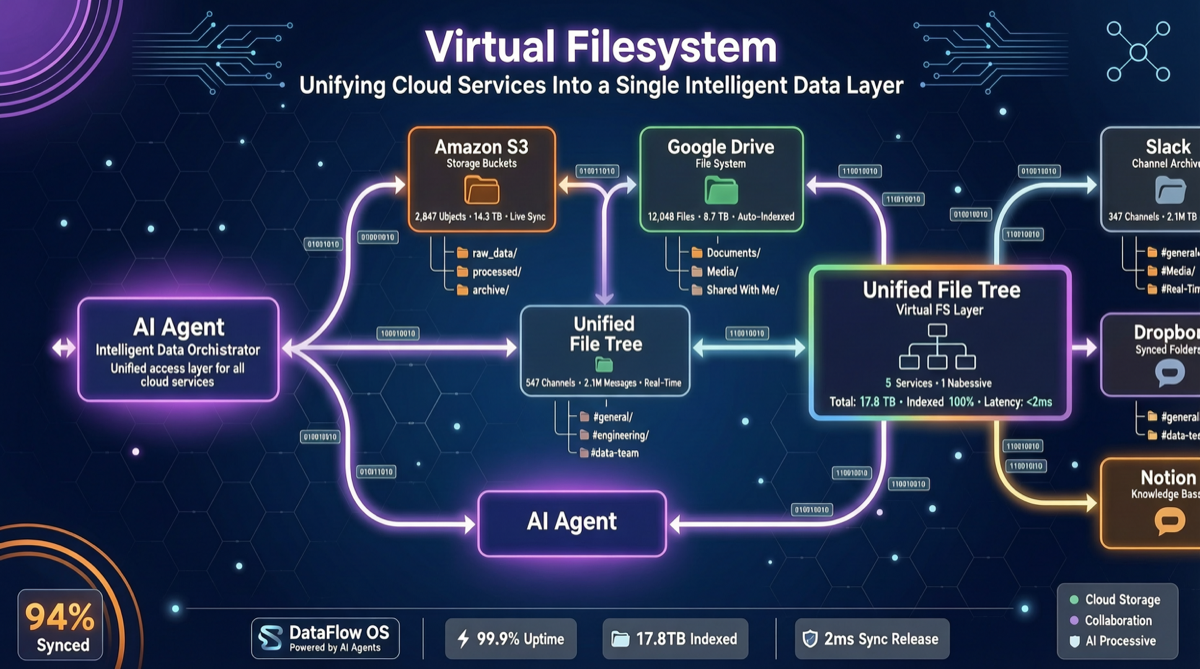
エージェント向け仮想ファイルシステムは最近次々出てきているが、Mirageのアプローチは少し違う。
これらのプロジェクトのほとんどは、エージェントに専用のAPIやツールを封装する — 「S3にアクセスするにはこの関数を呼べ、Google Driveを読み取るにはあれを呼べ」。Mirageは逆:全てのバックエンドを一つの仮想ファイルツリーにマウントし、エージェントはls、cat、grep、cpなどのbashコマンドを使えれば良い。
どう実現するか
MirageはFUSE(ユーザースペースファイルシステム)を通じてローカルに仮想ファイルシステムをマウントする。このファイルシステム下で、S3バケットのファイル、Google Driveのドキュメント、Slackチャンネルのメッセージ、Redisのキーバリュー — 全てファイルとして表示される。
エージェントにとって、データソース間の違いは消失する。「このファイルはS3にある」还是「このメッセージはSlackにある」を知る必要がない — ローカルファイルを操作するのと同じように操作すれば良い。
サポートするマウントターゲット:
- S3
- Google Drive
- Slack
- Gmail
- Redis
- その他更多
このアプローチが面白い理由
エージェント最大の弱点の一つはツール呼び出しの学習コスト。新しいデータソースを接続するたびに、新しいツールスキーマを定義し、新しいpromptを書いてエージェントに使い方を教え、新しいエラーケースを処理する必要がある。
Mirageはこのコストをゼロに押し下げる — マウントすれば、エージェントは使い方が分かる。なぜならbashコマンドはエージェントが既に持っている汎用スキルだから。
これが中国コミュニティで「思路が開けた、ファイルシステムがリソースセンターになった」と評価された理由。
でもまだ非常に初期段階
プロジェクトは昨日v0.0.1-alpha.1をリリースしたばかりで、コミットは4つ、1k stars。PythonとTypeScriptの両SDKも初期段階。
alphaバージョンは何を意味するか?本番環境では使うべきではない。しかしフォローする価値のある方向性を検証している:エージェントが最も馴染みのある方法で最も馴染みのないデータソースを操作させる。
他のVFSプロジェクトとの比較
同時に類似の仮想ファイルシステムプロジェクトがいくつか出てきている。Mirageの差別化ポイントはサポートするマウントターゲットが较多く、PythonとTypeScriptの両実装を提供していること。
エージェントのデータアクセス層を設計しているなら、Mirageの思路は参考になる — 更多のAPIを封装するのではなく、エージェントが学習が必要なインターフェースの種類を減らす。
主要ソース: