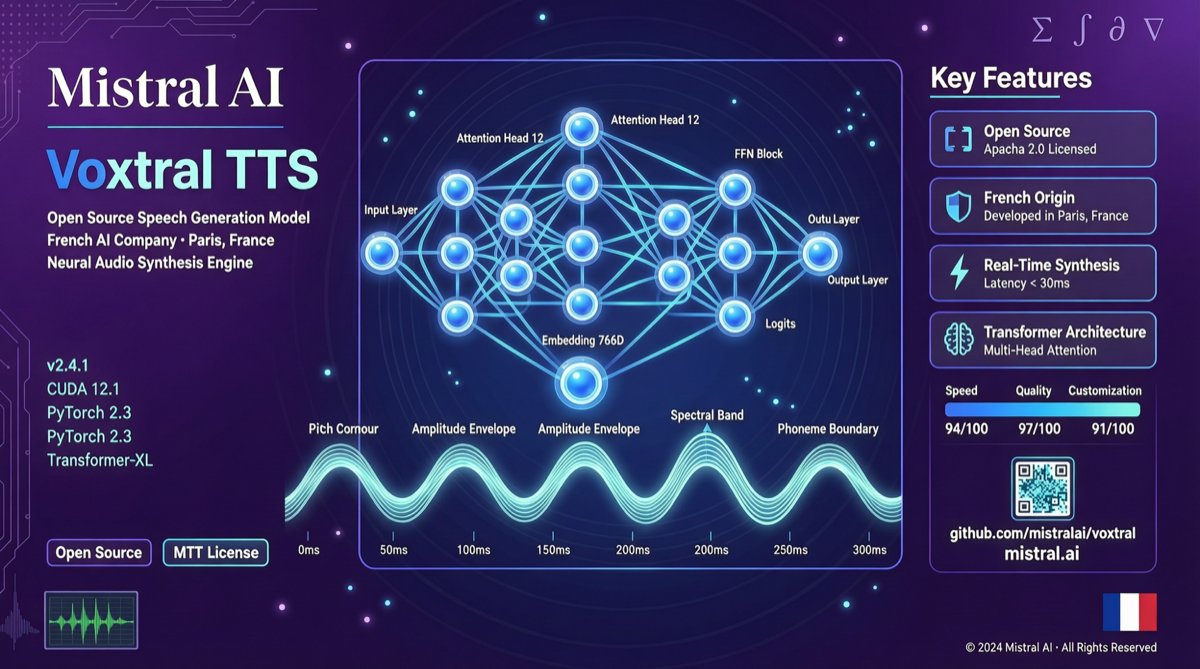
Mistralの音声AIスイートがついに完成した。
3月26日、フランスのAI企業Mistral AIがオープンソースのテキスト音声変換モデルVoxtral TTSを発表した。バッチ文字起こしと低遅延リアルタイム文字起こしモデルに続く、Mistralの音声赛道における第三のピースだ。「聴く」から「話す」まで、完全なエンドツーエンド音声処理プラットフォームがオープンソース化された。
90ミリ秒の意味
初音遅延90ミリ秒。これはどのレベルか?
ElevenLabsの遅延は約200〜300ミリ秒の範囲にある。使えないわけではないが、リアル会話のシナリオでは200ミリ秒の間隔ですでに「相手が考えている」感じがする。90ミリ秒は人間の自然な会話の反応速度にほぼ近い。
もちろん、遅延は一つの指標に過ぎない。音質、感情表現、多言語対応、カスタム音色——これらがTTSモデルの実際の採用を決定する鍵だ。
コミュニティのフィードバックによると、Voxtral TTSの音質はオープンソースモデルの中で第一梯队に属するが、感情の繊細さと音色の多様性ではElevenLabsに差がある。ただし差は縮まっており、しかもオープンソースだ。
主な情報源:
- Mistral AI公式発表
- TechCrunch報道
- Hugging Faceモデルページ