出来事
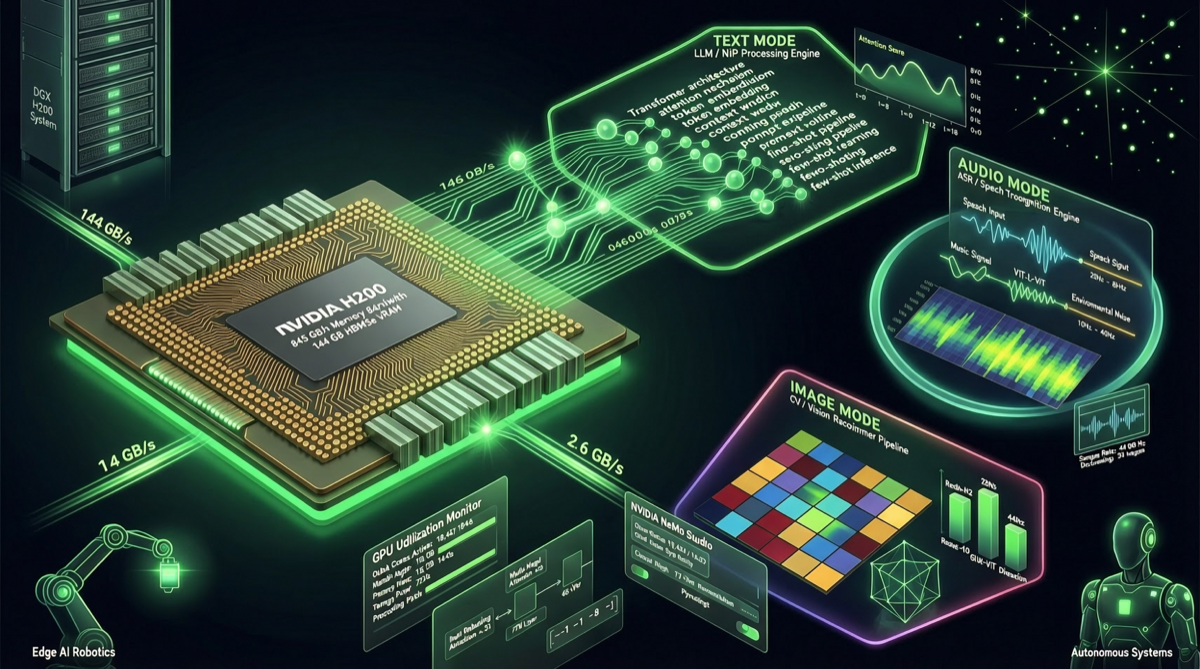
NVIDIA は 4 月 29 日に次世代オープン全モダリティモデル Nemotron 3 Nano Omni を正式に発表しました。本モデルは効率と精度を重視し、Hopper および Blackwell アーキテクチャの FP8 推論を深度最適化すると同時に、RTX 5090 などのコンシューマー向け GPU や Jetson Thor ロボティクスプラットフォームとの互換性を維持しています。
さらに重要なのは、新モデルがエージェントアプリケーションシナリオにおいて最大 9 倍の効率向上を実現したことであり、大規模モデル競争の焦点が「能力の上限」から「アプリケーション効率」へと正式に移行したことを示しています。
注目すべき理由
競争パラダイムの変化
過去 1 年の大規模モデル競争は、本質的に能力の上限をめぐる競争でした。誰のベンチマークスコアが高いか、誰のコンテキストウィンドウが長いか、誰のコード生成が強いか。
2026 年に入ると、競争ロジックは根本的に変化しました。最低のコスト、最高の効率、最小限のリソースで実際のタスクを完了できるかが、新たな勝負の基準となりました。
Nemotron 3 Nano Omni のリリースは、このパラダイム転換の象徴的な出来事です。NVIDIA はもはやモデル規模の拡大のみを追求するのではなく、単位計算あたりの出力効率に焦点を当てています。
画期的なハードウェア互換性
Nemotron 3 Nano Omni のハードウェア互換性戦略には深い意味があります:
- コンシューマー向け GPU(RTX 5090):個人開発者や小規模チームがエンタープライズ向け GPU を購入することなく、高品質の全モダリティモデルを実行可能
- Jetson Thor ロボティクスプラットフォーム:クラウド推論からエッジデプロイメントまでの完全なパイプラインを橋渡しし、AI ロボティクスや IoT シナリオへの道を開く
- Hopper/Blackwell アーキテクチャの深度最適化:エンタープライズシナリオで NVIDIA ハードウェアの計算能力を最大限に活用
この「フルスタックカバレッジ」戦略は、個人開発者のローカルエージェントであろうと、工場ラインの品質検査システムであろうと、データセンターのマルチエージェントオーケストレーションであろうと、誰もが適切なデプロイメントオプションを見つけられることを意味します。
技術ハイライト
全モダリティ能力
Nano Omni の核心的なブレークスルーは全モダリティにあります。単一モデルでテキスト、画像、音声など複数の入力タイプを処理できます。これはエージェント開発における一つの痛点を直接解決します。マルチモーダルタスクは通常、複数の専用モデルを連結する必要があり、高遅延、高コスト、複雑なデバッグにつながっていました。
Nano Omni の全モダリティ能力により、エージェントは単一モデルで以下を完了できます:
- ユーザー入力分析(テキスト/音声/画像)
- マルチモーダル理解と推論
- マルチモーダル出力生成
FP8 推論最適化
深度最適化された FP8 推論は、9 倍の効率向上を支える核心的な技術です。従来の FP16 推論と比較して:
- VRAM 使用量が約 50% 削減:同じ GPU でより大きなモデルを実行したり、より長いコンテキストを処理したり可能
- 推論速度が 2〜3 倍向上:FP8 の計算スループットは FP16 より著しく高い
- 精度損失を制御可能:NVIDIA の特定の量子化戦略により、精度損失を許容範囲内に収めている
エージェントネイティブ設計
Nano Omni の設計目標は AI エージェントのアプリケーション開発に直接焦点を当てています。モデルは以下の面で特化された最適化を行っています:
- ツール呼び出し能力:MCP プロトコルと関数呼び出しに対するネイティブサポートを強化
- マルチステップ推論:最適化された Chain-of-Thought 推論パスにより、複雑なタスクにおけるエージェントの「回り道」を削減
- 状態保持:改良されたコンテキスト管理メカニズムにより、エージェントがマルチターン対話中でタスク状態をより適切に保持可能
業界への影響
オープンソースモデルの「ツルハシ売り」戦略
NVIDIA が Nemotron 3 シリーズをリリースしたことで、「ツルハシ売り」の戦略的位置づけを継続しています。最終的にどのモデルが市場を制するかに関わらず、すべて NVIDIA ハードウェア上で実行する必要があります。高性能なリファレンスモデルをオープンソース化することで、NVIDIA は実質的に以下を行っています:
- ハードウェア能力の上限を実演:開発者に NVIDIA チップ上でどれほど速く、どれだけ良くモデルが実行できるかを示す
- 技術ベンチマークを確立:業界全体に効率と精度の参照系を設定
- エコシステムの繁栄を推進:オープンソースモデルが開発の敷居を下げ、より多くの開発者をエージェントエコシステムに引き込む
Edge AI の加速
Nano Omni がコンシューマー向け GPU と Jetson プラットフォームをサポートすることは、Edge AI の普及を大幅に加速します。これまで、AI エージェントをデプロイするにはクラウド GPU サーバーが必要でしたが、今では RTX 5090 を搭載したワークステーションや Jetson 組込みデバイスで十分です。
これは以下を意味します:
- プライバシーに敏感なシナリオ(医療、金融)はデータをクラウドに送信することなくローカルでデプロイ可能
- オフラインシナリオ(工場、鉱山、野外)でも完全な AI エージェントを実行可能
- レイテンシに敏感なシナリオ(リアルタイム制御、自動運転)でミリ秒レベルの応答を実現可能
シグナルと検証
- NVIDIA 公式発表であり、信頼性が高い
- 9 倍の効率向上データは NVIDIA 自身のベンチマークに基づいており、独立した環境での検証が必要
- オープンソース戦略は技術的敷居を下げるが、FP8 最適化は NVIDIA ハードウェアエコシステムに高度に依存
- 全モダリティ能力は実際のエージェントシナリオで評価する必要がある
アクションアイテム
- Edge AI ニーズを評価:ローカルデプロイメントや低レイテンシの要件がある場合、Nano Omni は重点的に評価する価値がある
- FP8 推論をテスト:ターゲットハードウェアで実際にベンチマークを実行し、効率向上データを検証
- オープンソースコミュニティを注視:Nano Omni のオープンソース属性により、コミュニティは迅速に適応方案とベストプラクティスを生み出す
- マルチエージェントアーキテクチャを計画:推論コストの低減は、単一の汎用モデルに依存するのではなく、より多くの専用エージェントをデプロイできることを意味する