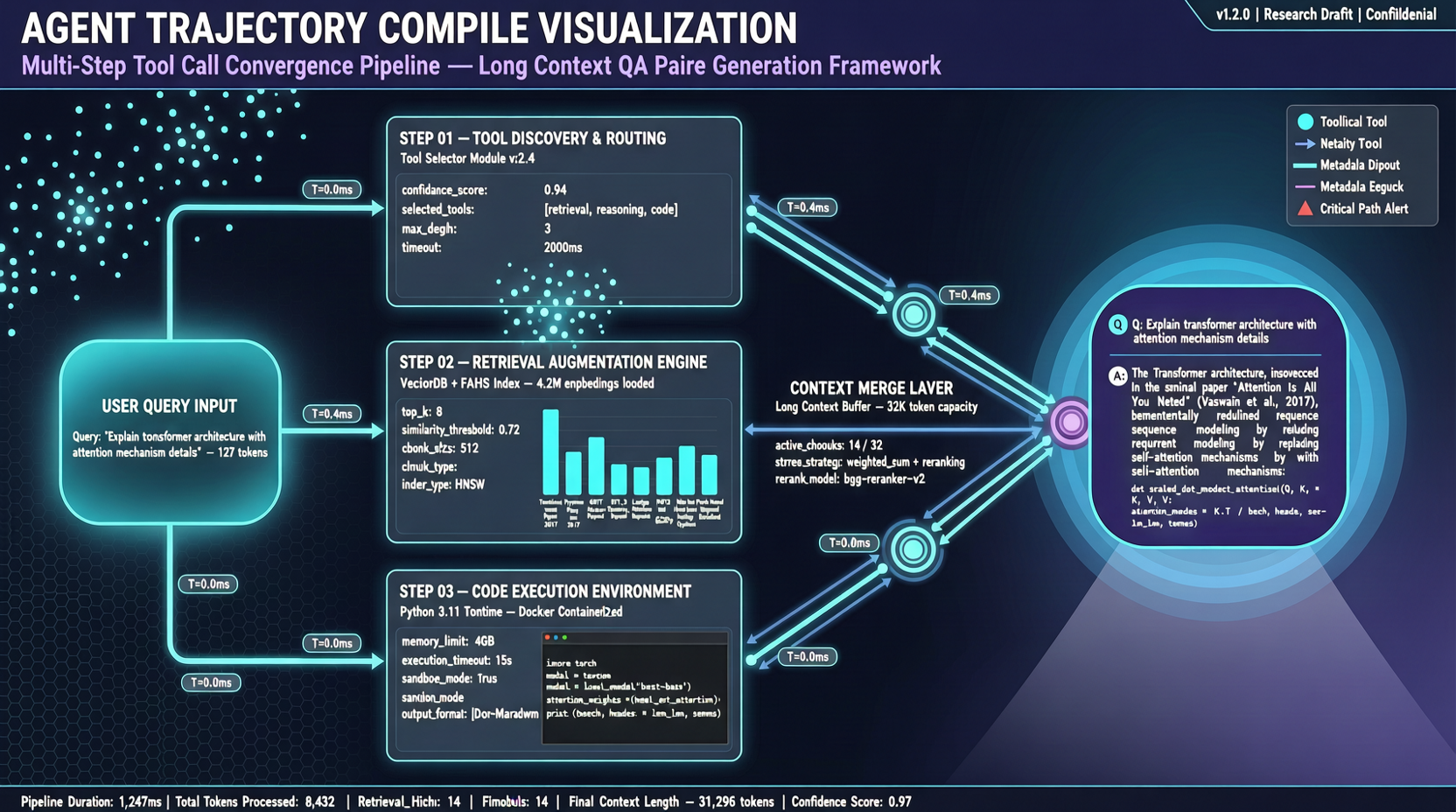
Agent 解决问题的方式是这样的:用户问一个问题,模型调一次工具拿到一堆数据,再调一次,再调一次……十几次交互之后终于凑够了信息,给出答案。
但标准 SFT 训练有一个盲区:它只在每一轮内训练工具选择,把工具返回的内容 mask 掉,不参与梯度更新。这意味着 Agent 积累的几十轮环境观察和工具结果——所有这些散落的证据——在训练时全被扔掉了。
ACC(Agent Context Compilation,arXiv:2605.21850,苏启晟等,2026年5月21日)的想法很直接:把这些轨迹"编译"成 QA 对。
编译过程
原始轨迹里,问题和答案之间隔着十几轮工具调用和环境观察。ACC 做的是把原始问题 + 所有工具响应 + 环境观察拼接在一起,形成一个长上下文 QA 对,目标是让模型在没有工具可用的情况下,直接从这个长上下文中找到答案。
这不是简单地把对话拼起来。工具返回的内容往往是非结构化的、带有噪音的,关键信息散落在不同轮次。模型需要学会跨轮次的指代消解和信息整合——这恰恰是长上下文推理最核心也最难的能力。
数据是白嫖的
最妙的部分是:这些数据不需要额外标注。Agent 在运行过程中自然产生的轨迹,经过 ACC 的编译流程就变成了高质量的长上下文训练样本。搜索 Agent、软件工程 Agent、数据库查询 Agent——只要有工具调用和观察,就能编译。
效果
在 Qwen3-30B-A3B 上,经过 ACC 训练:
- MRCR(跨轮次指代消解基准):68.3 分,比基线高 18.1 分
- GraphWalks(图遍历基准):77.5 分,比基线高 7.6 分
这个结果已经接近 Qwen3-235B-A22B 的水平。30B 的参数规模,通过一种数据编译方法,在长上下文推理上追上了大 7 倍的模型。
同时,GPQA、MMLU-Pro、AIME、IFEval 等通用能力保持不变——ACC 没有损害模型的泛化能力。
机制分析
论文还做了一些有意思的机制分析。ACC 训练后的模型展现出"任务自适应的注意力重组"和"专家特化"——也就是说,模型学会了在长上下文中动态调整注意力分布,不同 MoE 专家对不同位置的信息产生了专门化处理。
为什么值得关注
长上下文训练一直有两个路线:一是用长文档做预训练延续(成本高),二是用启发式方法合成上下文(质量不稳定)。ACC 提供了一个第三条路:利用 Agent 运行过程中自然积累的多轮交互数据,既丰富又真实,还免费。
如果你在做 Agent 开发,你的生产环境里可能已经积累了大量可编译的轨迹数据。ACC 的方法论让这些沉睡数据变成了长上下文训练的最佳素材。
这个方法可以叠加到任何现有的长上下文扩展或训练方法上——它不是替代方案,是增强方案。
主要来源:
- arXiv:2605.21850, ACC: Compiling Agent Trajectories for Long-Context Training, Qisheng Su et al., 2026-05-21