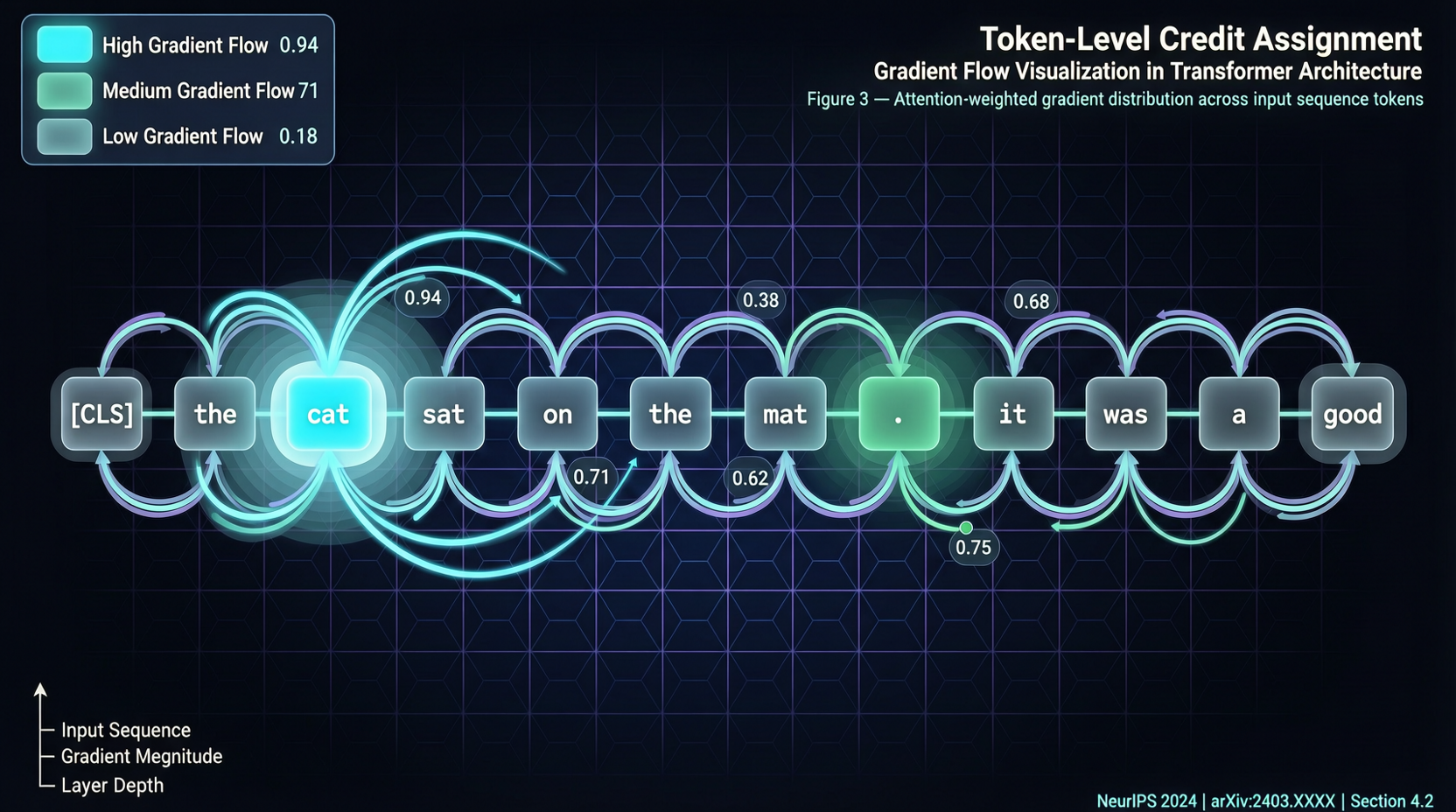
GRPO распределяет вознаграждение уровня траектории поровну между всеми токенами — как командный бонус, разделённый независимо от индивидуального вклада. Токен, пишущий ключевое озарение, получает тот же кредит, что и токен, ставящий точку.
DelTA (arXiv:2605.21467, Kaiyi Zhang и др., Пекинский университет народа / BAAI, 20 мая 2026) делает нечто простое по сути, но важное: переосмысливает направление обновления градиента политики RLVR как линейный дискриминатор.
Взгляд дискриминатора
Во время обучения RLVR модель генерирует несколько ответов на одну задачу — некоторые получают высокий балл, некоторые низкий. Стандартный подход усредняет все градиенты токенов, взвешенные по преимуществу, вычисляя «положительный центроид» и «отрицательный центроид», а направление обновления — это вектор, который их раздвигает.
Проблема в том, что эти центроиды доминируются высокочастотными общими токенами (символы форматирования,常见的связки). Те немногие токены, которые действительно отличают хорошие шаги рассуждения от плохих, — они заглушены.
DelTA оценивает «дискриминативный коэффициент» для каждого токена: токены, различающие положительные и отрицательные ответы, получают больший вес, общие или слабо дискриминативные токены — меньший. По сути, это повышение отношения сигнал/шум.
Результаты
На Qwen3-8B-Base DelTA превосходит сильнейшие базовые модели того же масштаба в среднем на 3,26 балла по 7 математическим бенчмаркам. На Qwen3-14B-Base — на 2,62 балла. Генерация кода и оценки за пределами домена подтверждают обобщаемость.
Честно говоря, прирост в 2-3 балла на текущих бенчмарках математических рассуждений — это не «сокрушительно» — но значимость статьи не в баллах. Она предоставляет новую структуру для понимания механики обучения RLVR: градиент политики неявно выполняет дискриминацию.
Параллельно с OPPO
Интересно, что другая статья — OPPO (arXiv:2605.21851) — появилась в тот же день, решая ту же проблему. OPPO использует байесовский подход с сигналом оракула для обновления убеждений; DelTA использует подход дискриминатора, усиливая контрастные направления градиентов. Оба обходят необходимость обучённой сети ценности.
Эту тенденцию стоит отслеживать: когда сообщество перестаёт принимать «GRPO работает, идём дальше» и начинает спрашивать «почему работает, где fails», исследование RLVR вступает в более глубокую фазу.
Основные источники:
- arXiv:2605.21467, DelTA: Discriminative Token Credit Assignment for Reinforcement Learning from Verifiable Rewards, Kaiyi Zhang et al., 2026-05-20