Google меняет структуру API Gemini. Изменение не огромное, но направление ясное.
Ранее модель взаимодействия Gemini API была стандартно-диалоговой: user отправляет сообщение, model отвечает. Раунд за раундом, роли чётко разделены.
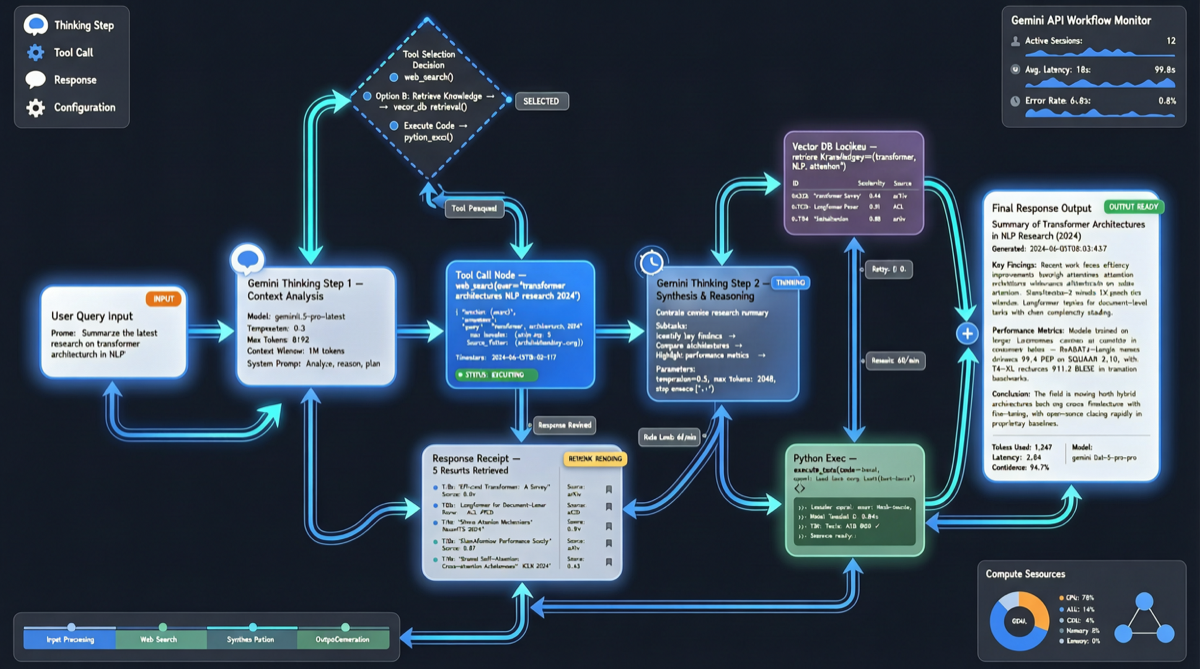
Теперь Google демонтировала эту модель. В новом Gemini Interactions API больше нет строгого разделения ролей user и model. Каждая мысль, каждый вызов инструмента, каждый вывод представлен как независимый шаг.
Что это значит?
От «диалога» к «воркфлоу»
Стандартный диалоговый API хорош для Q&A. Вы спрашиваете, я отвечаю. Чисто и просто.
Но агентные сценарии другие. Когда Агент выполняет сложную задачу, внутренние шаги хаотичны: он может сначала подумать, затем вызвать инструмент A, получить результат и снова подумать, потом вызвать инструмент B, понять, что нужен ввод пользователя, и приостановиться.
Старая модель ролей user/model в этом сценарии неудобна. Приходилось маскировать внутреннее мышление Агента как user-сообщения API или упаковывать результаты вызова инструментов как model-ответы. Интерфейс и реальное поведение не совпадают.
Новая модель шагов напрямую раскрывает эту сложность. Каждое действие — полноправный гражданин; API больше не пытается впихнуть их в оболочку диалога.
Что конкретно меняется
Официальный блог Google дал ключевое описание:
«Вместо строгих ролей 'user' и 'model' каждое действие (от мышления до вызовов инструментов) теперь представлено как собственный шаг.»
Это значит разработчики могут:
- Видеть полную цепочку мышления Агента, а не только финальный ответ
- Вмешиваться в конкретные шаги во время выполнения Агента, а не ждать конца раунда
- Сериализовать, сохранять и воспроизводить процессы многошагового выполнения Агента
Очень практично для enterprise-сценариев, требующих аудита и отладки.
Сравнение с конкурентами
API Claude от Anthropic уже имеет подобные возможности — его message API поддерживает tool_use и tool_result как независимые типы сообщений. Responses API от OpenAI тоже движется в этом направлении.
Особенность изменения Google в том, что оно не патчило существующий API, а перепроектировало модель взаимодействия. Это подразумевает, что Google готовится к более сложным сценариям мульти-агентной коллаборации.
Если каждый шаг независимо адресуем, теоретически несколько Агентов могут чередовать свои шаги в рамках одного Interaction, не мешая друг другу.
Когда будет доступно
Google сказала, что это «evolving» — всё ещё в процессе. GA-таймлайн не указан.
Но учитывая, что Google Cloud Next 2026 уже демонстрировал подобные агентные воркфлоу, это изменение API, вероятно, скоро выйдет в GA.
Моё мнение
Это изменение, которое «разработчики не почувствуют, но которое архитектурно значительно». Обычные пользователи ничего не заметят, но люди, строящие поверх Gemini, обнаружат, что разработка Агентов стала намного удобнее.
За чем следить: выпустит ли Google сопутствующие инструменты агентной оркестрации вокруг этой новой модели шагов, аналогичные MCP от Anthropic или ADK от Google. Если да, порог разработки Агентов для экосистемы Gemini заметно снизится.
Основные источники: