There is a long-standing paradox in AI: these models can write polished papers, pass the bar exam, and help you debug code, but nobody truly knows what is happening inside them.
You feed text into Claude, it passes through hundreds of neural network layers and hundreds of billions of parameters, and spits out a response. What happened in between? No one can say. It is like locking a genius in a black box and only caring about the answer they give, without asking about their reasoning process.
Anthropic's research, published on May 7, attempts to break this black box.
What They Did
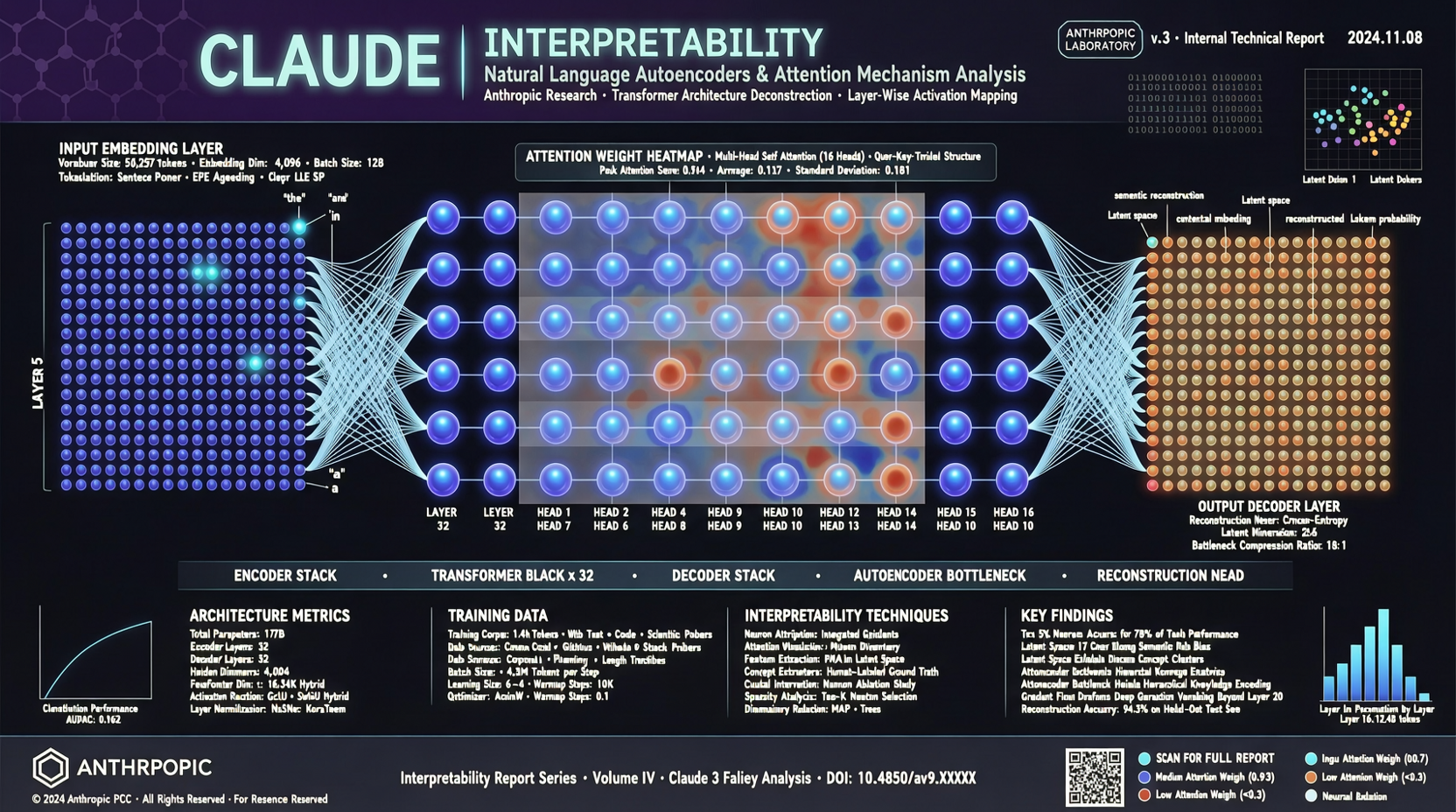
The paper's title is straightforward: "Natural Language Autoencoders: Turning Claude's thoughts into text."
In simple terms: AI models "think" in numbers—activation values, vectors, weight matrices—all of which are completely unintelligible to humans. Anthropic trained an autoencoder that lets Claude translate its internal activation values into natural language.
Not post-hoc explanation (the "I answered this way because..." kind of敷衍 at the prompt level), but directly extracting readable semantic information from the model's internal state. What the model is "thinking" gets translated into what it "means."
Analogy: previously you could only see someone's EEG readout; now you can directly read the sentences in their head.
Why This Matters More Than It Appears
Interpretability research has always been a "politically correct but slow-progressing" direction in the AI community. Everyone acknowledges its importance, but in practice it is extremely difficult. Neural network internal representations are high-dimensional, non-linear, and entangled—a single neuron may encode multiple concepts simultaneously, and a single concept may be distributed across thousands of neurons.
Anthropic's approach sidesteps this complexity. Instead of trying to map a complete "thought map," they train an intermediate layer that lets the model compress its activation values into natural language fragments, then reconstruct them. If reconstruction quality is high enough, it means the compressed language fragments genuinely captured the key information of the original activations.
The cleverness of this methodology: it does not require humans to a priori define "which concepts are worth tracking." The model itself decides which internal states matter, then expresses them in language.
Points Worth Thinking About
First, this does not equal full interpretability. The autoencoder outputs are discrete and fragmented—they show "thought fragments," not complete reasoning chains. Like being able to read someone's diary entries but not being able to reconstruct their entire mental journey.
Second, this creates a new attack surface. If you can translate a model's internal state into text, what about the reverse? Can you manipulate text to guide the model's internal state? This is a double-edged sword for security.
Third, the cost issue. Running the autoencoder means additional computational overhead. Adding a "self-translation" layer to Claude during inference increases both token consumption and latency. This is a hard constraint for real-world deployment.
My Take
Anthropic's direction is right. Interpretability is not an optional feature of AI safety—it is mandatory. As models become more capable, an uninterpretable superintelligent system is like an airplane flying without a black box or real-time monitoring—no matter how high it flies, when something goes wrong, you cannot even find the cause.
The natural language autoencoder may not be the final solution, but it proves that "letting the model explain itself" is a feasible path. Rather than waiting for some silver-bullet interpretability theory, this incremental, engineering-feasible approach may be more realistic.
An interesting contrast: OpenAI takes the capability-first route—make the model powerful first. Anthropic takes the safety-first route—understand the model first. Will these two paths eventually converge? Maybe. But until then, Anthropic's approach at least turns "what is AI thinking" from a philosophical question into an engineering problem.
Engineering problems can be solved.
Primary source: