AI agents have a stupid problem right now.
You spend half an hour talking to an agent, teaching it your preferences, your project structure, your code style. Then you open a new session — the agent forgets everything.
Every conversation is a first meeting.
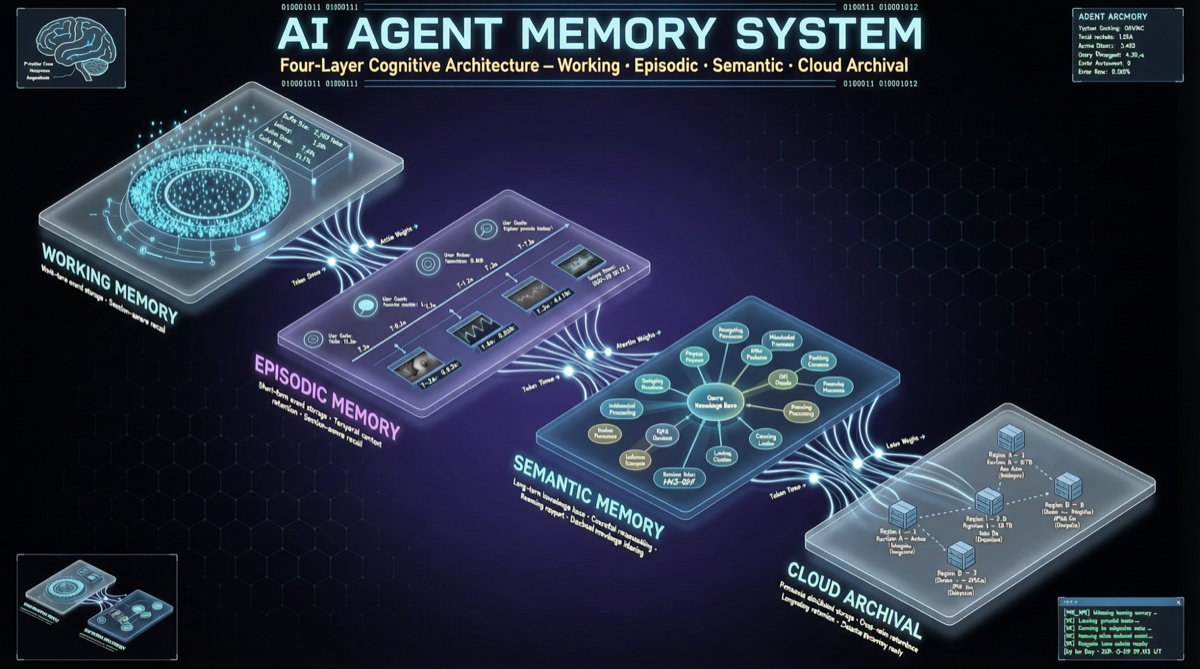
Four-Layer Memory Architecture
Someone is trying to solve this, with an approach that mimics human memory layering:
L1 Working Memory (<5ms): Equivalent to your short-term memory. Information needed for the current task, read and write in real-time, extremely fast. Like "which file is the user editing right now."
L2 Episodic Memory (Event Graphs): Records what happened. Not raw logs, but structured event graphs — "the user modified the auth module yesterday because they found a token expiration bug."
L3 Semantic Memory (Compressed HNSW): Compresses experience into retrievable knowledge. Like your "common sense" — you don't need to remember exactly when something happened, but you know "this project uses JWT for auth."
L4 Cloud Archival + Identity Persistence: Long-term storage. Like your diary — rarely consulted, but available when needed.
The core challenge isn't storage, it's adaptive retrieval. The agent needs to automatically determine "where to find this information" between L1 and L4, rather than you specifying it manually every time.
Why This Is a Key Piece of Agent Infrastructure
Current agent frameworks (LangChain, CrewAI, OpenClaw) solve "how to make agents call tools and execute tasks." But no one has solved "how to make agents remember what happened before."
The result is that agent capability is limited to a single session. An agent might be great at writing code, querying data, analyzing — but it doesn't remember what you had it do last week.
If an agent can't remember context across sessions, it's essentially just an advanced chatbot, not a real "staff member."
Competitive Landscape
This direction already has people working on it:
rohitg00/agentmemory(3.4K stars) — Focused on persistent memory for coding agents, ranked by benchmarks- Cloudflare's Agent Memory technical docs — Solving memory storage at the edge layer
- This four-layer Memory OS approach is more systematic, designing the entire memory pipeline at the architectural level
But all are still in early stages. None is a "ready-to-use" production-grade solution.
A Realistic Assessment
Adding persistent memory to agents — technically not hard. The hard part is deciding what to remember and what to forget.
If an agent remembers everything, retrieval slows down, storage costs skyrocket, and most memories are noise. If it remembers too little, we're back to "goldfish memory."
The four-layer architecture approach is correct — using different storage strategies matched to different memory types. But the key parameters (what goes into L2 vs L3, compression ratios, retrieval thresholds) are currently all guessed.
This direction is worth following. Next time a project makes memory strategy configurable, I'll try it immediately.
→ Further reading: Persistent Coding Agent Memory | Agent Context Persistence
Primary sources: