Claude Code writes 500 lines for you. You close the terminal. Two hours later, you open Codex to continue—it knows nothing about your previous work.
This is the biggest pain point of current AI coding tools. Every agent has goldfish memory—everything resets after a conversation window closes.
agentmemory, which gained 6,467 stars this week (total: 9k), does one simple thing: gives AI coding agents persistent memory. But simple things done right are massively valuable.
Not Just Claude, Now Codex Too
Two weeks ago, agentmemory was a Claude Code exclusive. Two days ago, it shipped Codex plugin support (PR #311), overnight becoming cross-agent infrastructure.
What does this mean? The project analysis, technical decisions, and architecture notes you made in Claude Code—Codex can read them directly the next time you open the same project.
This isn't simple tool compatibility. It's the雏形 of a unified memory layer.
How the Memory Layer Works
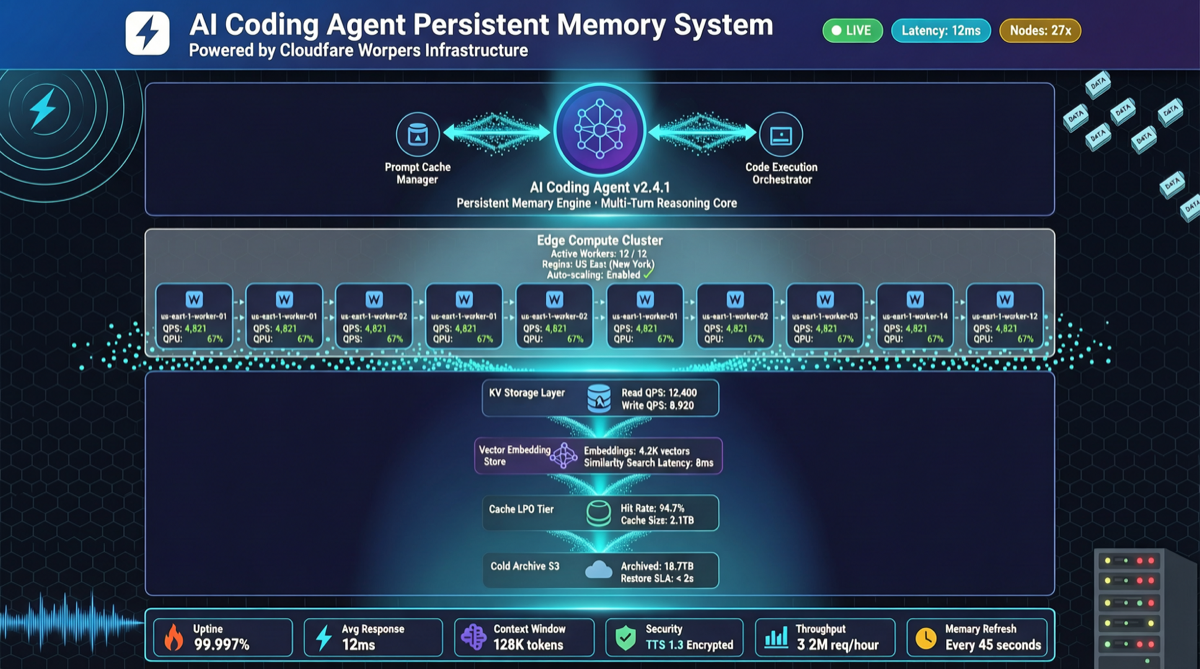
agentmemory's core idea: strip agent memory from the conversation window and store it in an independent, persistent storage layer.
The workflow:
- Agent makes decisions and records key info during conversation
- This info is automatically written to agentmemory via the plugin
- Next time any agentmemory-compatible agent starts, it loads relevant memory
- Agent starts work with "where we left off" context
Yesterday's v0.4 release added a heavy feature: 100k memory load benchmark (PR #363). p50 latency 120ms, p99 under 500ms. Even with massive accumulated memory, load speed stays imperceptible.
Three Moments That Made Me Think "This Is Actually Useful"
First moment: I spent half an hour in Claude Code mapping out microservice dependencies and had it generate an architecture doc. Closed Claude Code, opened Codex and asked "what's the inter-service call chain here?" Codex read the previous analysis directly from agentmemory and answered in a second.
Second moment: A colleague used Codex to add a new feature to the same project. I opened it with Claude Code the next day, and the Agent told me "your colleague added X module yesterday, involving Y changes, watch out for Z." It didn't read git log—it read the change summary the colleague's Codex automatically wrote to shared memory.
Third moment: I deliberately cleared conversation history and reopened the project. The Agent's first sentence: "Last time we discussed switching auth from JWT to OAuth2, want to continue?" Not magic—it just read the last decision record in agentmemory.
Deployment
agentmemory now supports one-click deploy to Fly.io, Railway, and Render (PR #361). For personal use, running a local instance is enough. For teams, deploy to cloud so all agents point to the same memory backend.
Limitations
agentmemory isn't a silver bullet. Clear boundaries:
- Memory quality depends on the agent's recording ability. If the agent doesn't proactively write key info, the memory layer stays empty
- Cross-project isolation isn't fine-grained enough. Currently isolated by project, but some scenarios need finer permission control
- No auto-summarization. Memory is raw records, not auto-compressed. With lots of info, agents spend extra tokens digesting it
But it solves the 0-to-1 problem—agents no longer forget. The rest, the community is rapidly iterating.
Verdict
If your daily work involves switching between multiple AI coding tools, or your team shares a codebase but uses different agents, agentmemory is currently the best memory infrastructure choice.
It's not perfect, but it turned "agents with memory" from concept into an operable workflow.
Sources: