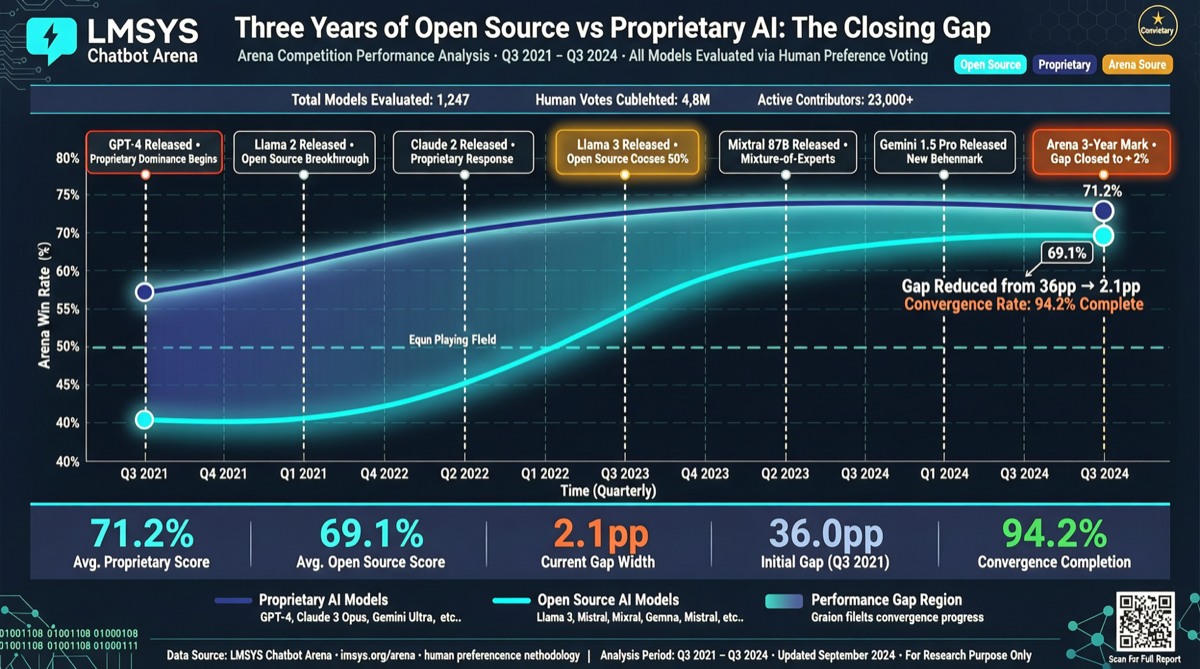
In early 2023, proprietary models led open source by 250 points in Chatbot Arena Text Arena. That was a nearly insurmountable gap.
By early 2026, that number dropped to single digits.
LMSYS published a dataset yesterday spanning three years across three Arenas (Text, Code, Expert Prompt), answering a question many people have been asking: Have open source models caught up?
The answer is basically yes. But not equally across all domains.
Text Arena: From +250 to Single Digits
The most intuitive curve. Early 2023: proprietary +250. Early 2025: compressed to "low double digits." Then—note this timing—DeepSeek R1 briefly overtook in early 2025, giving open source a historic Arena lead.
That lead didn't last. Proprietary models quickly reclaimed #1, but the gap is no longer an order of magnitude difference.
Code Arena: Compression Even Faster
Code Arena has a shorter history but the gap closed more aggressively. Proprietary lead peaked at +100, then compressed through spring 2026 to around +40 today.
+40 means proprietary still has a perceptible advantage, but it's no longer "once you try it you can't go back" territory.
Expert Prompt: +40 Still Held by Proprietary
Expert Prompt is the hardest Arena. Proprietary models still maintain a +40 lead here.
LMSYS's own words: "Expert prompts are the toughest challenge for open models."
Who's Driving This
DeepSeek R1's overtake in early 2025 wasn't accidental—MoE architecture and dramatically lower inference costs pushed open source性价比 to a new level. Qwen 3.6's performance on the Intelligence Index and Kimi K2.6's SWE-bench results are further proof.
My Take
If you're doing model selection, this data says one thing: open source models' position as the default option is forming.
Main sources: