Bottom Line
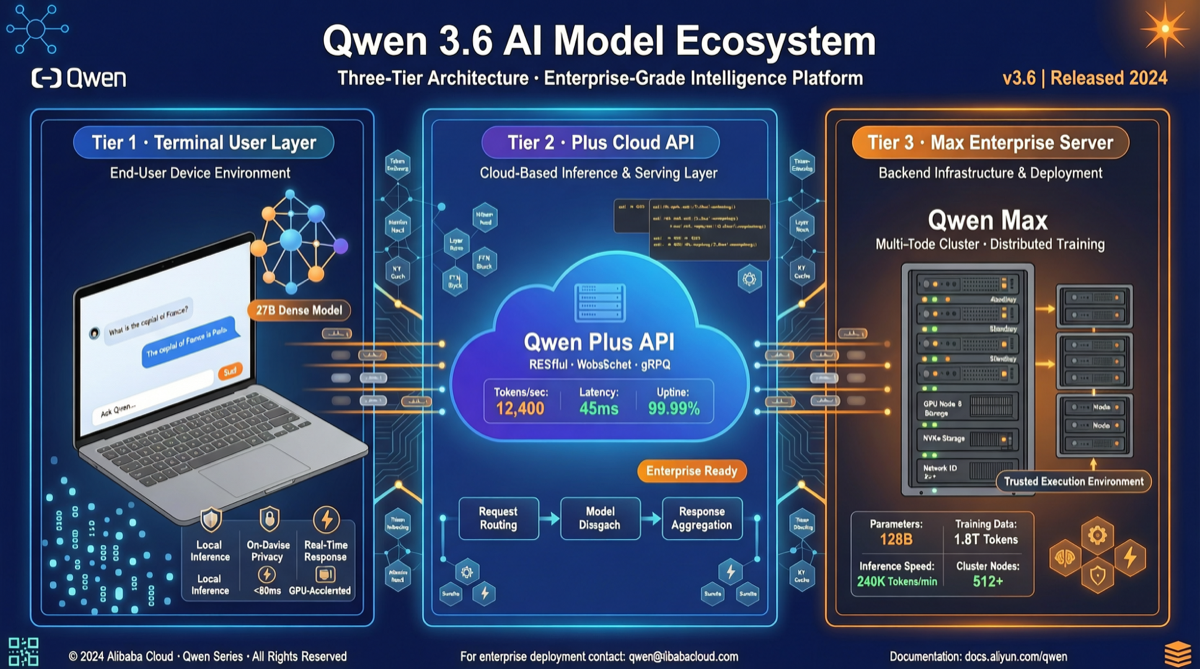
The Qwen 3.6 series is not a single model, but a three-tier product matrix: the 27B dense model targets local deployment and consumer-grade hardware, Plus serves cost-conscious cloud users, and Max tackles the most complex coding and reasoning tasks. The three tiers complement each other, forming complete coverage from edge to cloud.
More interestingly, Alibaba Cloud prices the 27B API ($0.6/$3.6 per M tokens) higher than Plus ($0.5/$3), which seems counterintuitive but reflects the 27B model’s unique positioning — it’s not a “lite version,” but an independent product line.
Three-Tier Product Matrix Breakdown
Tier 1: Qwen3.6-27B — The Edge “Powerhouse”
The 27B uses a dense architecture (not MoE), meaning all 27 billion parameters are activated for every token generated. This design brings several key advantages:
| Dimension | Data | Meaning |
|---|---|---|
| Parameter Scale | 27B Dense | All parameters participate in every computation |
| Minimum Hardware | 18GB RAM | MacBook Pro / RTX 4090 can run it |
| Native Context | 262K | Extensible to 1M via YaRN |
| SWE-bench | ~77% | Near Claude Opus 4.6 level |
| Terminal-Bench | Matches Opus 4.5 | Terminal operation at flagship level |
Quantized versions have already achieved 95 tps, 92 tps, and 73 tps on DGX-Spark, outperforming gpt-oss-120B and gemma4-26B. This means enterprises can deploy near-flagship coding assistants on their own hardware without relying on cloud APIs.
Tier 2: Qwen 3.6 Plus — The Cost-Effective “Workhorse”
Plus positions itself between 27B and Max, serving as the optimal choice for most daily scenarios:
- Lower API pricing: $0.5/$3 per M tokens, 17%-20% cheaper than the 27B API
- Faster inference: MoE architecture activates fewer parameters, yielding higher throughput
- Optimized tool calling: Significantly improved stability and accuracy compared to Qwen 3.5
- Scientific coding leap: Major improvements in math and scientific programming
Plus’s core value proposition is clear: solve 80% of daily coding and reasoning needs at the lowest cost.
Tier 3: Qwen 3.6 Max — The Complex Task “Specialist”
Max is the most capable version in the Qwen 3.6 series, targeting scenarios requiring extreme performance:
- 256K tokens native context
- Strong performance on SWE-bench Verified
- Significantly improved front-end UI generation
- Ideal for large codebase refactoring and complex system architecture design
The Pricing Paradox: Why Is the 27B API More Expensive Than Plus?
This is a counterintuitive pricing strategy. Conventionally, models with fewer parameters should be cheaper. But Alibaba Cloud chose the opposite.
The logic behind this may be:
- Scarcity pricing: The 27B’s unique value lies in its ability to “run on consumer-grade hardware.” The API version offers the convenience of no local deployment — this convenience itself commands a premium.
- Differentiated positioning: 27B and Plus are not “high-low” variants, but two different technical routes (dense vs. MoE), each with independent user bases.
- Ecosystem strategy: API pricing guides users to choose based on actual needs — go Plus for cheap, go 27B for specific capabilities.
Landscape Assessment
Qwen 3.6’s three-tier matrix strategy is more mature than the single “strongest model” narrative. It recognizes:
- Not every user needs the strongest model — Plus is sufficient for most daily tasks
- Local deployment is a real need — the 27B gives consumers and SMBs an option independent of the cloud
- API pricing can guide behavior — price signals steer users to the right model
Compared to OpenAI’s “one model rules all” and Anthropic’s “few but refined” strategies, Alibaba’s Qwen 3.6 is more like the Android approach — using a product matrix to cover as many scenarios and budget ranges as possible.
Actionable Recommendations
| Your Scenario | Recommendation | Reason |
|---|---|---|
| Local coding assistance, offline inference | Qwen3.6-27B | Runs on 18GB RAM, SWE-bench 77% |
| Daily API calls, cost-sensitive | Qwen 3.6 Plus | Best price-performance, stable tool calling |
| Large codebases, complex reasoning | Qwen 3.6 Max | Extreme performance, 256K context |
| Enterprise private deployment | Qwen3.6-27B Quantized | DGX-Spark verified, 95 tps throughput |
The core competitiveness of the Qwen 3.6 series lies not in any single benchmark being #1, but in providing complete choice from edge to cloud, from low-cost to high-performance. In an era of rapidly iterating AI models and user decision fatigue, this product strategy is itself a competitive advantage.