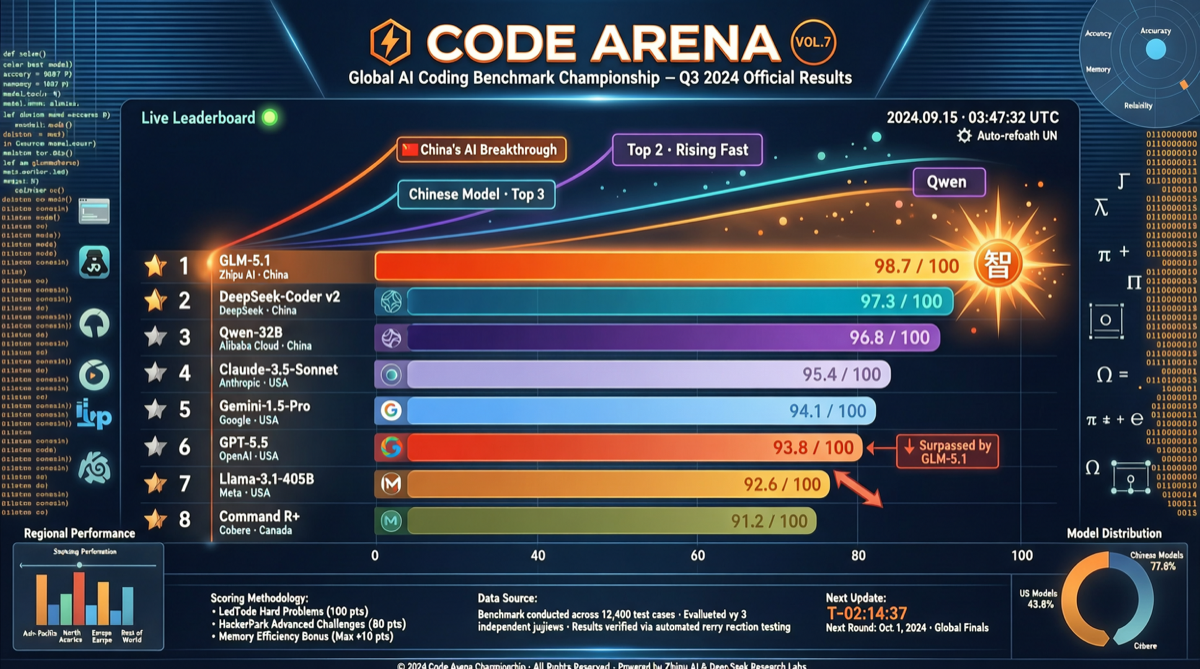
核心データ
Code Arena の最新ランキングが公開され、コーディング分野の勢力図に大きな変化が起きている。評価対象の46のエージェント・コーディングモデルの中で、中国モデルが最も注目すべきポジションを占めている:
| ランク | モデル | Code Arena スコア |
|---|---|---|
| 1 | GLM-5.1 | ~1535+ |
| 2 | Kimi K2.6 | ~1520+ |
| 3 | MiMo-V2.5-Pro | ~1510+ |
| … | … | … |
| 5 | GLM-5.1(確認済み) | 1535 |
| 9 | GPT-5.5 High | 1500 |
重要事実:GLM-5.1 の Code Arena スコア(1535)は GPT-5.5 High(1500)を明確に上回っており、エージェント・コーディングおよび Web 開発タスクで特に優れたパフォーマンスを示している。
中国コーディング3強構造
多次元のデータを統合すると、中国モデルはコーディング分野で「三強+追撃者」の構造を形成している:
GLM-5.1:智譜AIの最新モデルで、Code Arena で際立った活躍を見せている。以前、智譜は GLM-5 のトレーニング中に遭遇したスケーリングの苦悩をレビューするブログ記事を公開し、文字化け出力、繰り返し、稀な文字の問題のデバッグ過程を率直に開示した。これは業界では稀な透明性である。GLM-5.1 はこれらの問題修正後のバージョンであり、コーディング能力が大幅に向上している。
Kimi K2.6:月之暗面(Moonshot AI)のフラッグシップモデル。SWE-Bench Pro で58.6点を獲得し、オープンソースモデルのトップに立ち、GPT-5.4 と Claude 4.6 を凌駕した。K2.6 はエージェントスワームアーキテクチャを採用し、300の並列サブエージェントと4000ステップの深層推論をサポートし、エージェントスケールの天井を再定義した。
MiMo-V2.5-Pro:小米(Xiaomi)大モデルチームの責任者である羅福莉氏主導で開発されたモデル。最近の3.5時間にわたる深度インタビューで、羅氏は事前トレーニングの格差が解消された後の小米の技術的方向性——エージェント強化学習への転換——を明らかにした。MiMo の急浮上はこのアプローチの有効性を証明している。
意外な低迷者:DeepSeek V4 Pro
最も劇的だったのは DeepSeek V4 Pro のパフォーマンスである。かつて中国モデルの王者と目されていた V4 Pro は、今回のコーディングランキングで意外にも最下位に沈んだ。これは以下の傾向を反映している可能性がある:
- V4 Pro の最適化は一般推論に偏っており、エージェント・コーディングの専門シナリオでは不利
- 競合のイテレーションが加速——GLM-5.1 と K2.6 のコーディング特化の最適化効果が顕著
- DeepSeek の API キャッシュ価格戦略は利用コストを下げたが、コーディング能力の向上にはつながらなかった
業界における意義
このランキングの変化はいくつかの重要なシグナルを送っている:
- 中国モデルはコーディング分野でもはや追撃しているわけではない——GLM-5.1 が GPT-5.5 High を突破したのは画期的な出来事
- 透明な事後検証の文化が形成されつつある:智譜のスケーリングの苦悩の公開、Anthropic の品質低下の事後検証、OpenAI の「ゴブリン」出力事件のレビュー——大モデル企業のエンジニアリング透明性が向上している
- エージェントアーキテクチャが決定的な差別化要因になりつつある:K2.6 の300並列サブエージェントと GLM-5.1 の自己評価(自己評価のために完全な Three.js レーシングゲームを構築)は、エージェントネイティブアーキテクチャが純粋なモデル規模競争に取って代わろうとしていることを示している
開発者や企業にとって、これはエージェント・コーディングシナリオにおいて、中国モデルが「使える」から「良い」へ移行したことを意味し、場合によっては第一の選択肢になりつつある。