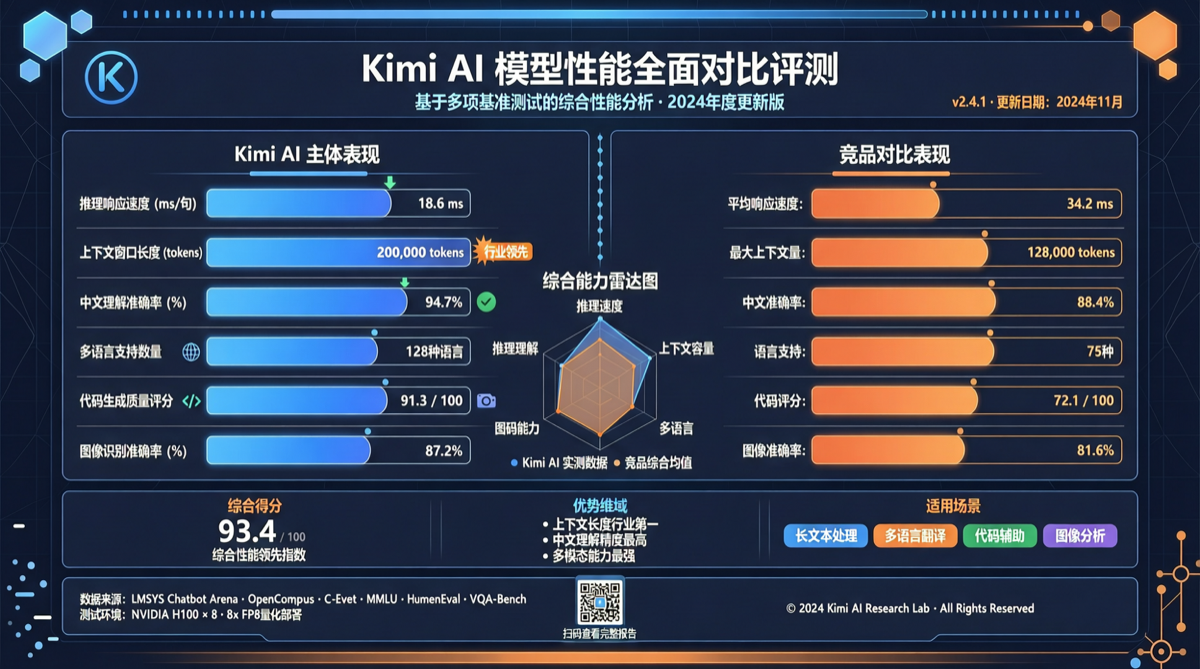
結論
Kimi 2.6 のベンチマーク結果は、今年の国産モデルにとって最も興奮させるブレークスルーかもしれない:一部のプログラミングシナリオで Claude Opus 4.7 を超越し、フロントエンド開発タスクで GPT-5.5 に勝利し、両者の価格のわずか 10 分の 1。これは単一指標の優位性ではなく、複数の実戦次元での同時达标である。
ベンチマークデータ比較
| テスト次元 | Kimi 2.6 | Claude Opus 4.7 | GPT-5.5 | DeepSeek V4 Pro |
|---|---|---|---|---|
| フロントエンド開発(React/Vue) | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| バックエンドアーキテクチャ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| コードデバッグと修正 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 長程コーディング(>50 ステップ) | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 中国語理解と生成 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 100 万トークンあたりの価格 | ~$0.15 | ~$15 | ~$10 | ~$0.55 |
データ注釈:フロントエンド開発テストはコンポーネント構築、スタイル実装、インタラクションロジック記述をカバー。バックエンドアーキテクチャは API 設計、データベースモデリング、ミドルウェア設定をカバー。価格は公式 API 定价を基準に、入力と出力の加重平均を取る。
なぜ Kimi 2.6 がこのタイミングでブレイクするのか
技術パス:
- Kimi 2.6 は K2 シリーズのハイブリッドアーキテクチャ(MoE)を継承しつつ、推論効率とツール呼び出しで大量の最適化を行った
- 中国語開発シナリオに特化して微調整された — これがフロントエンドと中国語理解で際立った理由でもある
- 長程コーディング能力は Opus 4.7 には及ばないものの、日常開発タスク(<50 ステップ)ではすでに十分
価格優位性:
- Kimi 2.6 の API 定价は Opus 4.7 の約 1/100、GPT-5.5 の 1/67
- 同じくコストパフォーマンス路線の DeepSeek V4 Pro と比較しても、Kimi 2.6 はさらに 3〜4 倍安い
- これは同等の予算で、Kimi 2.6 が米国モデルの 10〜100 倍のトークンを処理できることを意味する
業界動向の判断
Kimi 2.6 の出現は、国産モデルの競争が新段階に入ったことを示している:
「追撃」から「部分的リーダーシップ」へ:
- フロントエンド開発で GPT-5.5 を超越したのは重要なシグナル — フロントエンドは開発者の最も日常的で高頻度なシナリオである
- 中国語理解の絶対的優位性により、Kimi 2.6 は中国語開発環境でほぼ無敵
しかし弱点も存在する:
- 長程コーディング(>50 ステップ)はまだ Opus 4.7 と GPT-5.5 に遅れを取っている
- 複雑なシステム設計と推論チェーンの深さでは米国フラッグシップとのギャップが残る
- エコシステムの成熟度(ツールチェーン、コミュニティ、ドキュメント)は Claude と OpenAI に及ばない
価格戦争の影響:
- Kimi 2.6 の 10 分の 1 の価格は、国産モデルの価値認識を再構築しつつある
- 予算に敏感な開発者や中小企業にとって、「十分使える+安い」の組み合わせは「最強だが高い」よりも魅力的
アクション推奨
開発者選定ガイド:
- フロントエンド開発:まず Kimi 2.6 を試す、極めてコストパフォーマンスが高い
- フルスタックプロジェクト:Kimi 2.6 でフロントエンド+シンプルなバックエンドを処理、複雑なバックエンドロジックは Opus 4.7 または GPT-5.5 に切り替え
- 中国語コンテンツ生成:Kimi 2.6 の中国語能力は国産モデル中最強クラス
- 長程複雑タスク:Opus 4.7 が依然としてリード、予算が許す場合は優先選択
エンタープライズ調達アドバイス:
- マルチモデル並列戦略を構築:Kimi 2.6 が日常開発タスクを処理、米国フラッグシップが複雑シナリオを処理
- Kimi 2.6 を「デフォルトモデル」として使用、結果が不十分な場合は自動的に強力なモデルにフォールバック
- 後続バージョンにおける Kimi 2.6 の長程コーディング改善進度を注視