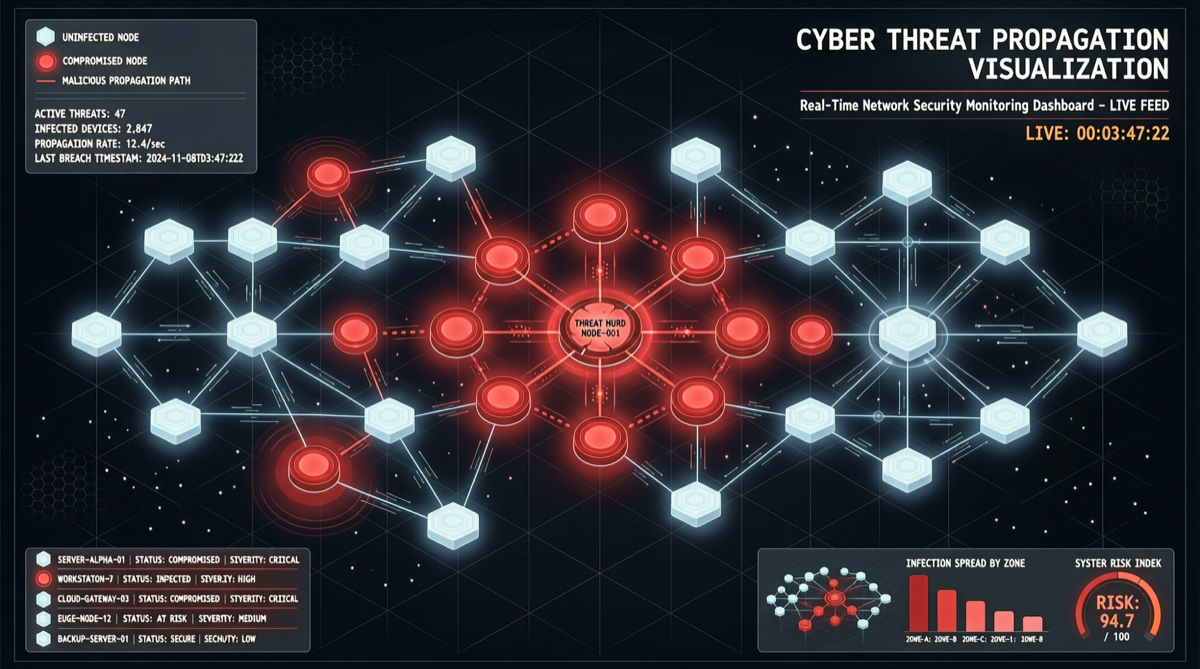
核心発見
マイクロソフトセキュリティ研究チームは今週、マルチエージェントシステムに関する全く新しい攻撃ベクトルを開示した:単一の悪意あるメッセージがマルチエージェントネットワークでジャンプ式に伝播する。
具体的なプロセス:
- 攻撃者がエージェントAに巧妙に構成された悪意あるメッセージを送信
- エージェントAがメッセージを処理する際、隠し指令を含む出力を生成するよう誘導される
- エージェントBがエージェントAの出力を入力として受け取り、隠し指令を無意識に継承
- エージェントBが隠し指令を実行、プライベートデータを抽出し、新しい悪意ある出力を生成
- エージェントCがエージェントBの出力を受信……感染チェーンが継続
重要な洞察:これは1つのエージェントがハッキングされる問題ではない。エージェントネットワーク全体が1つのメッセージで徐々に感染される可能性がある。
業界の対応
マイクロソフトの研究開示後、複数のAIセキュリティチームとフレームワークメンテナーが行動を開始:
- CISA / ファイブアイズ:5月初旬にリリースした「Agentic AIセキュリティガイド」にマルチエージェントのセキュリティ分離の提案を含む
- LangGraph:エージェント間入力検証ミドルウェアの開発中
- Hermes Agent:コミュニティでマルチエージェントオーケストレーションに信頼境界を追加する議論が開始
- Anthropic:Claude Coworkの設計でエージェント間の信頼隔離を考慮
防御アドバイス
マルチエージェントシステム設計者向け
- 入力検証層の実装:各エージェントの出力が次のエージェントに入る前に独立した検証を受けるべき
- 信頼境界の確立:異なるセキュリティレベルのエージェントは隔離された環境で実行
- エージェント間通信の監査:すべてのエージェント間のメッセージ传递を記録、事後追跡を可能に
- エージェント権限の制限:各エージェントはタスク完了に必要な最小権限のみを持つべき
企業エージェント導入者向け
- エージェントトポロジー図の作成:エージェントネットワークの各ノードの役割と接続関係を明確に把握
- 重要パスの特定:感染するとネットワーク全体に影響するエージェントを特定
- 異常検知の導入:エージェントの行動パターンを監視、異常な出力や操作を検出
- 应急响应計画の策定:エージェントの感染を発見した場合、迅速に隔離・回復する方法を準備
まとめ
マイクロソフトのマルチエージェント交差感染研究とUC Santa Cruzのエージェント投毒論文は、同じ結論を指し示している:AIエージェントの能力が強いほど、セキュリティリスクも大きい。複数のエージェントが協力する時、リスクは線形に累積するのではなく指数関数的に増幅する。
これはマルチエージェントシステムの開発を停止すべきという意味ではない——開発の第一天からセキュリティを考慮しなければならないということだ。