結論ファースト
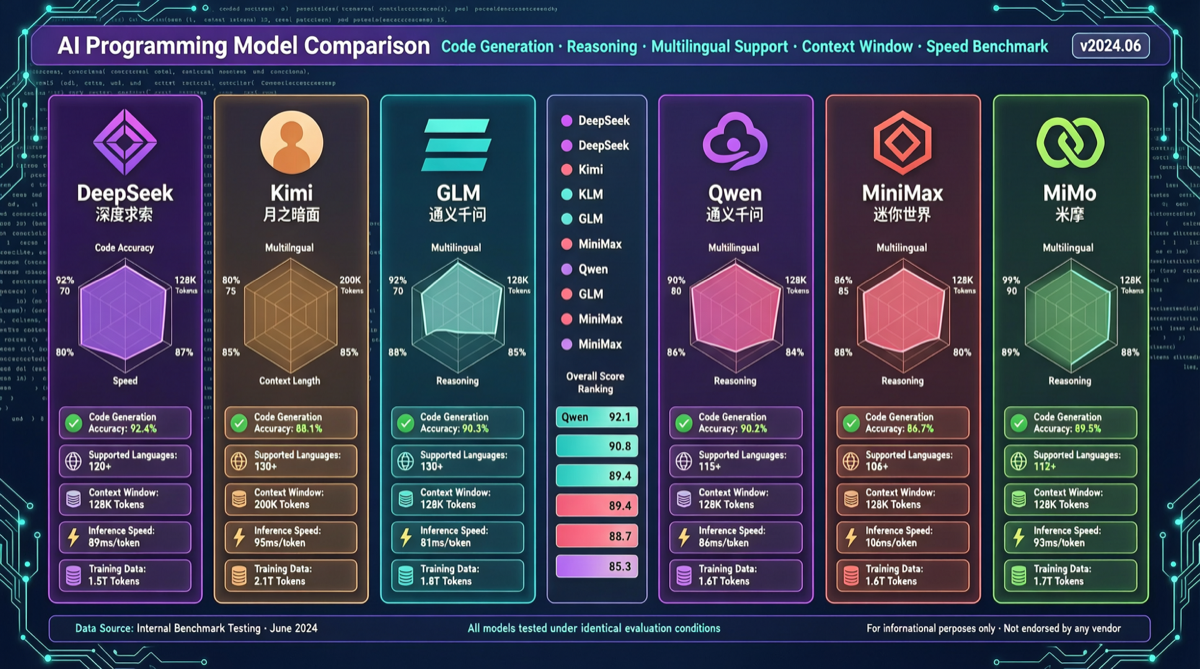
大多数の人がまだGPTとClaudeを見守っている間、6つの中国AIモデルはすでにプログラミング能力においてキラーポジショニングを確立している。最新のクロスモデルコーディングテストは、中国モデルがもはや「GPTの代替品」ではなく、推論スタイル、コード構造、実行効率の次元で差別化された道を切り開いていることを示している。
主要な発見:
| モデル | 最強次元 | スタイル | 最適なシーン |
|---|---|---|---|
| DeepSeek | 複雑な推論 | 推論エンジン、段階的に問題を分解 | アルゴリズム、アーキテクチャ設計 |
| Kimi K2.6 | コード教育 | 教師のように、すべての決定理由を説明 | 学習、コードレビュー |
| 智譜 GLM 5.1 | コード構造 | 最もクリーンな開発者スタイル構造 | エンジニアリングプロジェクト、チームコラボレーション |
| Qwen 3.6 | 実行効率 | 効率的で簡潔、本題に直行 | 迅速なプロトタイピング、スクリプト生成 |
| MiniMax | 創造的コーディング | 非伝統的なソリューション | クリエイティブプロジェクト、UI/UX |
| 小米 MiMo | マルチモーダルコーディング | 音声+ビジョン+コードフルスタック | IoT、エッジデプロイ |
テスト背景
テストは完全に同一のコーディングプロンプトを6つのモデルで実行し、出力品質、コード構造、推論プロセス、実際の執行効果を比較した。これはベンチマークスコアの比較ではなく、実场景での「同一問題、6つの解法」の比較だ。
テスト次元
- コード正確性:コンパイルが通るか?ロジックは正しいか?
- 推論透明性:自分の考えを明確に説明できるか?
- コード標準性:命名、構造、コメントがエンジニアリング基準に合致しているか
- 実行効率:トークン消費と出力品質の比率
- スタイル差異:異なるモデルが同一問題にどうアプローチするか
モデル別パフォーマンス分析
DeepSeek:推論エンジン型選手
DeepSeekはテストにおいて強い「思考連鎖」の特徴を示した。複雑な問題に直面すると:
- まず問題を複数のサブタスクに分解
- 各サブタスクの制約条件を個別に分析
- 段階的にソリューションを構築
- 最後に統合して検証
このスタイルは深度な推論を必要とするプログラミングシーンに特に適している——アルゴリズム設計、システムアーキテクチャ、パフォーマンス最適化。
Kimi K2.6:教育型選手
Kimiの突出した特徴は「説明力」だ。正しいコードを書くだけでなく:
- なぜあるデータ構造を別のものより選んだかを説明
- エッジケースの処理方法を記述
- 潜在的な最適化スペースを指摘
- 複雑な概念を理解するためにアナロジーを使用
GPT 5.4レベルのコーディング能力でありながら、価格はOpus 4.7の7分の1。
智譜 GLM 5.1:アーキテクト型選手
GLMの出力は構造標準性において最高のパフォーマンスを示した:
- 関数名は業界の慣習に従う
- モジュール分割が明確
- エラー処理が完全
- コメントの配置が適切
Qwen 3.6:効率型選手
Qwenの差別化優位性は「無駄を省いて本質に」:
- トークン消費が最低
- 出力は本題に直行
- コンシューマー級ハードウェアで最高の推論パフォーマンス
- 同サイズモデル中最強のマルチモーダル能力
MiniMax:創造型選手
MiniMaxはテストにおいて他のモデルとは異なる問題解決アプローチを示した。他のモデルが標準的な答えを出す時、MiniMaxは:
- 非伝統的なアルゴリズムを試す
- UI/UX面で追加の提案を提供
- マルチメディアインタラクション要素を組み込む
小米 MiMo:万能型選手
最新の参入者として、MiMoの特徴は「何でも少しできる」:
- 音声対話コーディング
- ビジョン支援プログラミング
- オープンソース方言ASRサポート
- エッジデプロイに親和的
価格比較:中国モデルが価格を再定義
| モデル | Opus 4.7比価格 | コンテキストウィンドウ | オープンソース |
|---|---|---|---|
| Kimi K2.6 | ~14% | 200K | ✅ |
| GLM 5.1 | ~19% | 128K | ✅ |
| DeepSeek V4 | ~5% | 1M | ✅ |
| Qwen 3.6 | ~8% | 256K | ✅ |
市場構造判断
- 差別化競争は既定の事実:中国モデルはもはや「GPTを全面的に超える」を追求しておらず、それぞれニッチな優位性を見つけた
- オープンソースがデフォルトに:6つのモデルのうち5つがオープンソースまたはオープンウェイト版を提供
- 推論速度が依然としてボトルネック:ほとんどのユーザーが中国モデルの推論速度は依然としてクローズドソースモデルより遅いと報告
- マルチモーダルが次の戦場:MiMoの参入はマルチモーダルコーディングが新たな競争次元になりつつあることを示唆
アクション推奨
| あなたのニーズ | 推奨モデル |
|---|---|
| 複雑なアルゴリズム/アーキテクチャ設計 | DeepSeek V4 |
| プログラミング学習/コードレビュー | Kimi K2.6 |
| エンジニアリングプロジェクト/チームコラボレーション | GLM 5.1 |
| 迅速なプロトタイピング/ローカルデプロイ | Qwen 3.6 |
| クリエイティブプロジェクト/UIデザイン | MiniMax |
| IoT/エッジマルチモーダル | MiMo |
核心的推奨:1つのモデルに固執するのはやめよう。タスクタイプに応じてモデルを切り替える——これが現在、最適なコーディング体験とコストコントロールを実現する戦略である。