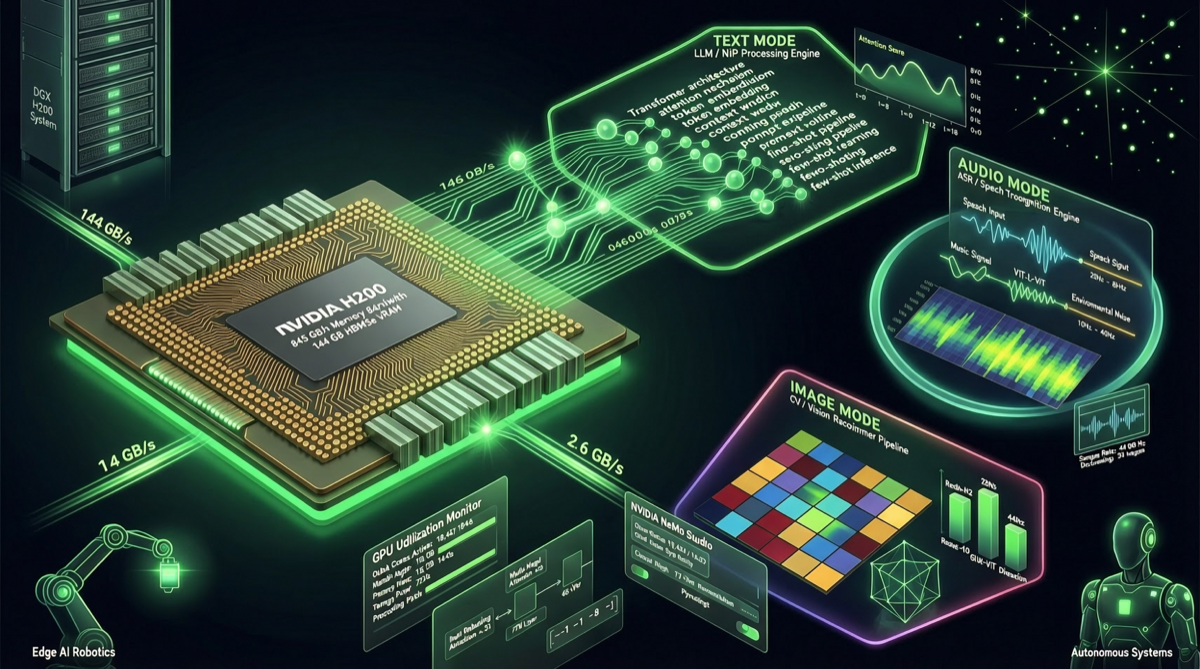
Событие
NVIDIA официально выпустила новое поколение открытой омни-модели Nemotron 3 Nano Omni 29 апреля. Модель делает акцент на эффективности и точности, с глубокой оптимизацией FP8-инференса на архитектурах Hopper и Blackwell, оставаясь при этом совместимой с потребительскими видеокартами уровня RTX 5090 и робототехнической платформой Jetson Thor.
Что ещё важнее, новая модель обеспечивает до 9-кратного повышения эффективности в сценариях агентных приложений, что официально сместило фокус конкуренции больших моделей с «потолка возможностей» на «эффективность применения».
Почему это важно
Сдвиг парадигмы конкуренции
За последний год конкуренция больших моделей по сути была гонкой за потолок возможностей: чьи результаты на бенчмарках выше, чьё окно контекста длиннее, чья генерация кода мощнее.
Вступая в 2026 год, логика конкуренции фундаментально изменилась: кто способен выполнять реальные задачи с наименьшими затратами, наивысшей эффективностью и минимальными ресурсами — стал новым критерием победы.
Выпуск Nemotron 3 Nano Omni — знаковое событие этого парадигмального сдвига. NVIDIA больше не стремится исключительно к расширению масштаба модели, а фокусируется на эффективности отдачи на единицу вычислений.
Революционная совместимость с оборудованием
Стратегия совместимости Nemotron 3 Nano Omni с оборудованием имеет глубокий смысл:
- Потребительские видеокарты (RTX 5090): индивидуальные разработчики и небольшие команды могут запускать высококачественные омни-модели без покупки корпоративных GPU
- Робототехническая платформа Jetson Thor: обеспечивает полный конвейер от облачного инференса до развёртывания на краю, прокладывая путь для AI-робототехники и IoT-сценариев
- Глубокая оптимизация под архитектуры Hopper/Blackwell: максимально использует вычислительную мощность оборудования NVIDIA в корпоративных сценариях
Эта стратегия «полностекового покрытия» означает, что будь то локальный агент индивидуального разработчика, система контроля качества на заводской линии или мультиагентная оркестрация в дата-центре — каждый найдёт подходящий вариант развёртывания.
Технические особенности
Омни-модальность
Ключевое достижение Nano Omni заключается в его омни-модальности — одна модель способна обрабатывать текст, изображения, аудио и другие типы входных данных. Это напрямую решает одну из болевых точек в разработке агентов: многомодальные задачи обычно требуют последовательного соединения нескольких специализированных моделей, что приводит к высокой задержке, высоким затратам и сложной отладке.
Омни-модальные возможности Nano Omni позволяют агентам выполнять с помощью одной модели:
- Анализ пользовательского ввода (текст/голос/изображение)
- Многомодальное понимание и рассуждение
- Генерацию многомодального вывода
Оптимизация FP8-инференса
Глубоко оптимизированный FP8-инференс — ключевая технология, стоящая за 9-кратным повышением эффективности. По сравнению с традиционным FP16-инференсом:
- Использование видеопамяти снижено примерно на 50%: один и тот же GPU может запускать более крупные модели или обрабатывать более длинные контексты
- Скорость инференса выросла в 2-3 раза: вычислительная пропускная способность FP8 значительно выше, чем у FP16
- Контролируемая потеря точности: специфическая стратегия квантования NVIDIA удерживает потерю точности в приемлемых пределах
Нативная агентная архитектура
Цели дизайна Nano Omni напрямую направлены на разработку приложений AI-агентов. Модель имеет целевые оптимизации в следующих аспектах:
- Возможность вызова инструментов: расширенная нативная поддержка протокола MCP и вызова функций
- Многошаговое рассуждение: оптимизированные пути рассуждения Chain-of-Thought, сокращающие «ошибочные повороты» агента в сложных задачах
- Сохранение состояния: улучшенные механизмы управления контекстом, позволяющие агентам лучше поддерживать состояние задачи в многоходовых взаимодействиях
Влияние на индустрию
Стратегия «продавца кирки» для моделей с открытым кодом
Выпуск серии Nemotron 3 продолжает стратегическое позиционирование NVIDIA как «продавца кирки». Независимо от того, какая модель в итоге победит на рынке, все они должны работать на оборудовании NVIDIA. Выпуская высокопроизводительные референсные модели с открытым кодом, NVIDIA по сути:
- Демонстрирует потолок возможностей оборудования: показывая разработчикам, насколько быстро и хорошо модели могут работать на чипах NVIDIA
- Устанавливает технические бенчмарки: задавая систему отсчёта для эффективности и точности во всей отрасли
- Стимулирует процветание экосистемы: модели с открытым кодом снижают барьер для разработки, привлекая больше разработчиков в экосистему агентов
Ускорение Edge AI
Поддержка Nano Omni потребительских видеокарт и платформы Jetson значительно ускорит распространение Edge AI. Ранее для развёртывания AI-агентов требовались облачные GPU-серверы; теперь достаточно рабочей станции с RTX 5090 или даже встраиваемого устройства Jetson.
Это означает:
- Сценарии, чувствительные к конфиденциальности (медицина, финансы) могут развёртываться локально без отправки данных в облако
- Офлайн-сценарии (заводы, шахты, полевые работы) также могут запускать полноценные AI-агенты
- Сценарии, чувствительные к задержкам (управление в реальном времени, автономное вождение) могут обеспечить отклик на уровне миллисекунд
Сигналы и подтверждение
- Официальный выпуск NVIDIA, высокая достоверность
- Данные о 9-кратном повышении эффективности основаны на собственных бенчмарках NVIDIA и требуют независимой проверки
- Стратегия открытого кода снижает технический барьер, но FP8-оптимизация сильно зависит от экосистемы оборудования NVIDIA
- Омни-модальные возможности нуждаются в оценке в реальных агентных сценариях
Рекомендации к действию
- Оцените потребности в Edge AI: если ваш бизнес имеет требования к локальному развёртыванию или низкой задержке, Nano Omni заслуживает серьёзной оценки
- Протестируйте FP8-инференс: запустите бенчмарки на целевом оборудовании для проверки показателей повышения эффективности
- Следите за сообществом открытого кода: открытый характер Nano Omni означает, что сообщество быстро выпустит решения по адаптации и лучшие практики
- Планируйте мультиагентную архитектуру: более низкие затраты на инференс означают возможность развёртывания большего количества специализированных агентов вместо reliance на единую модель общего назначения