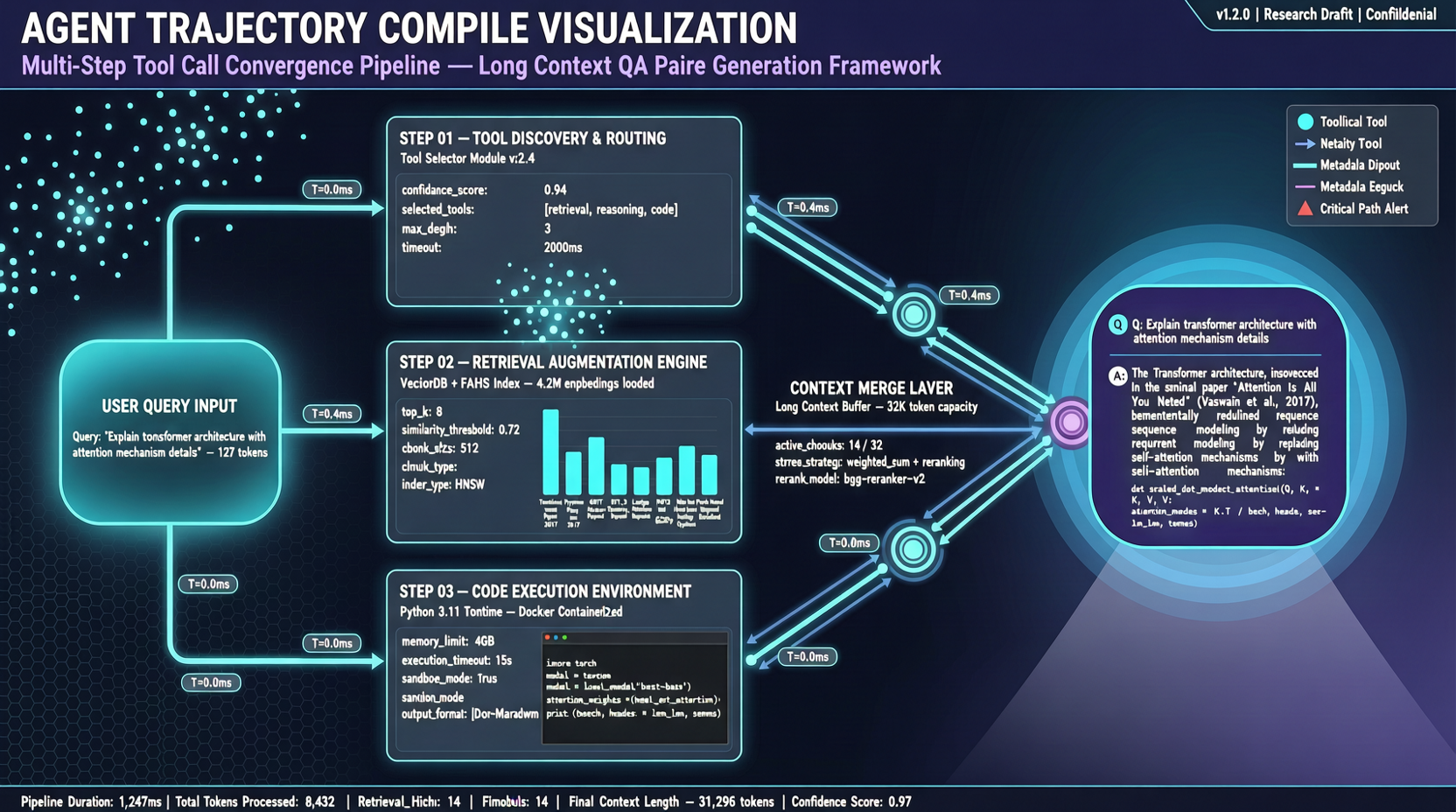
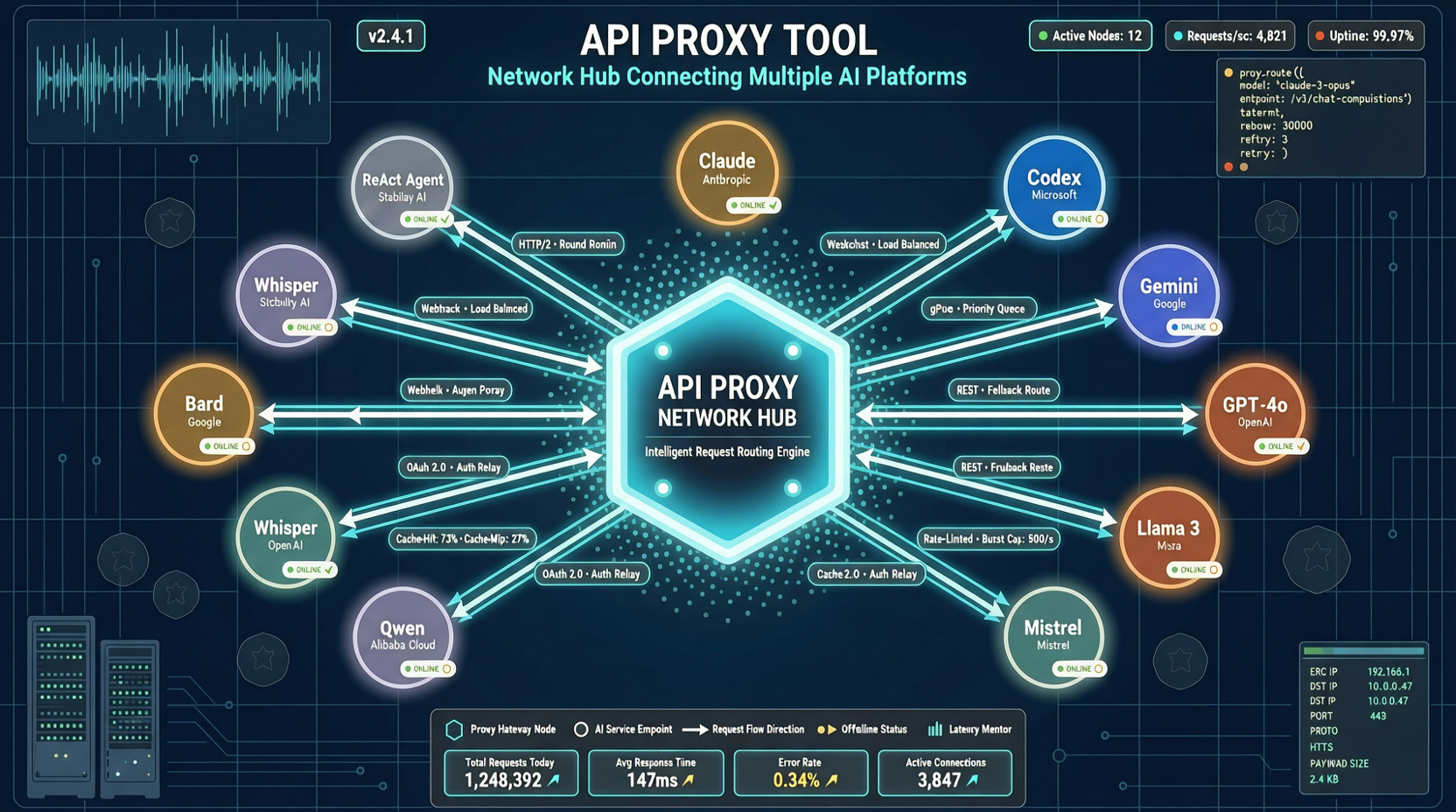
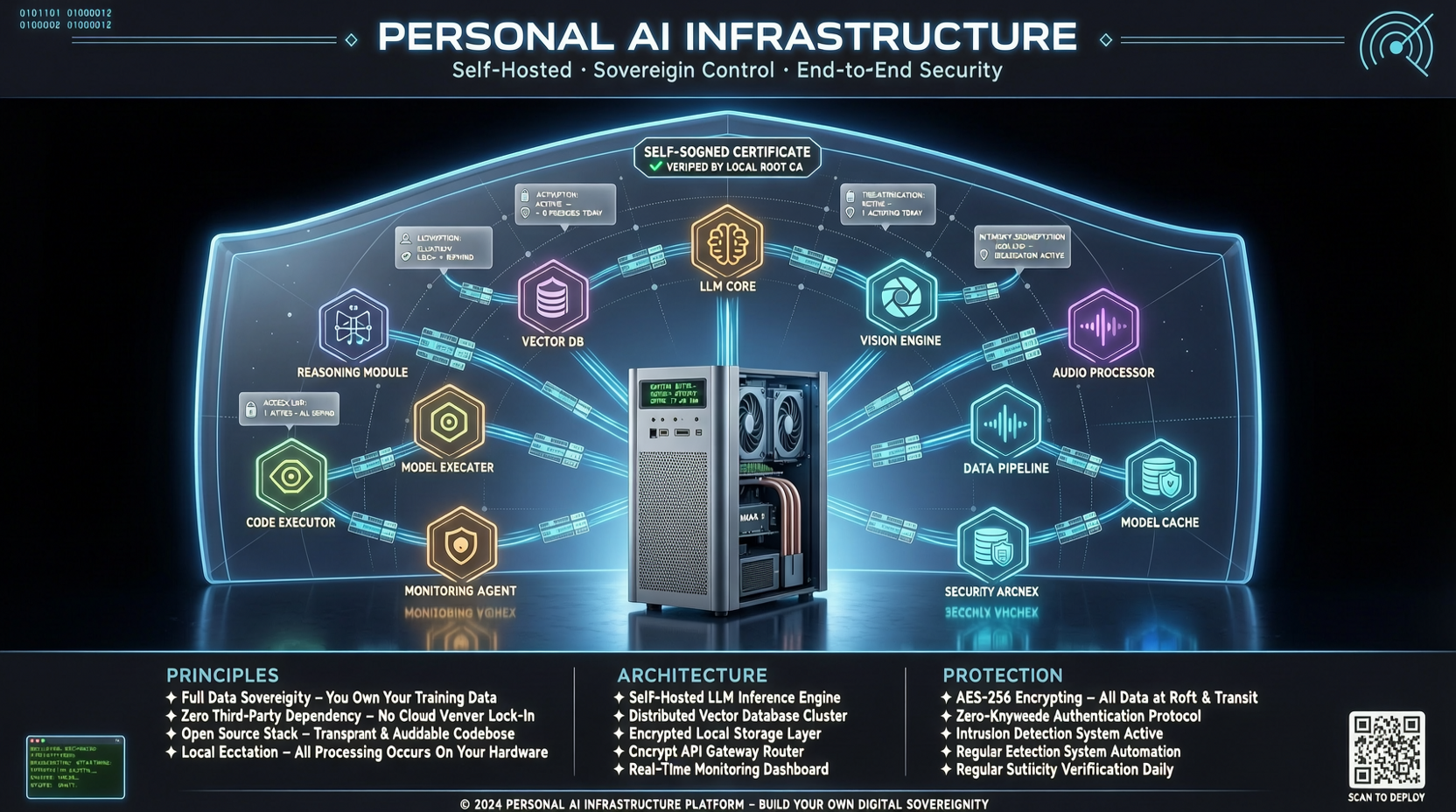
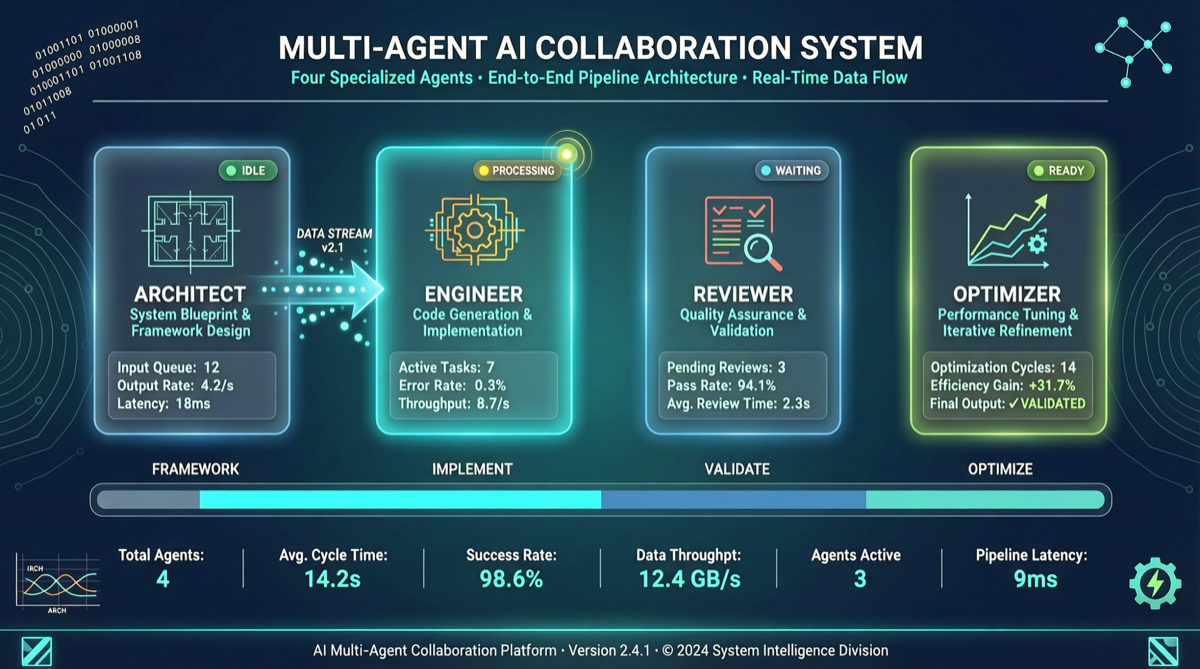
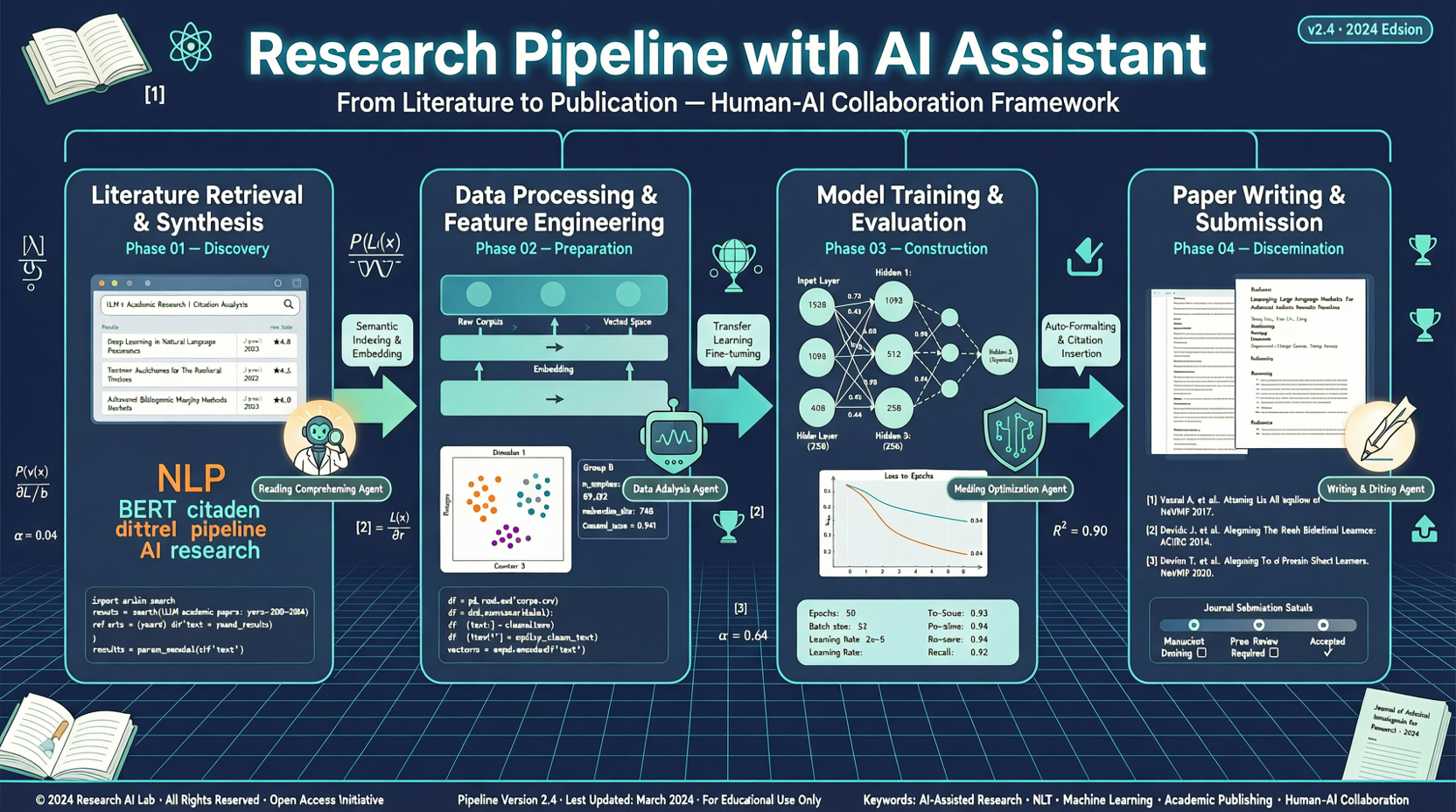
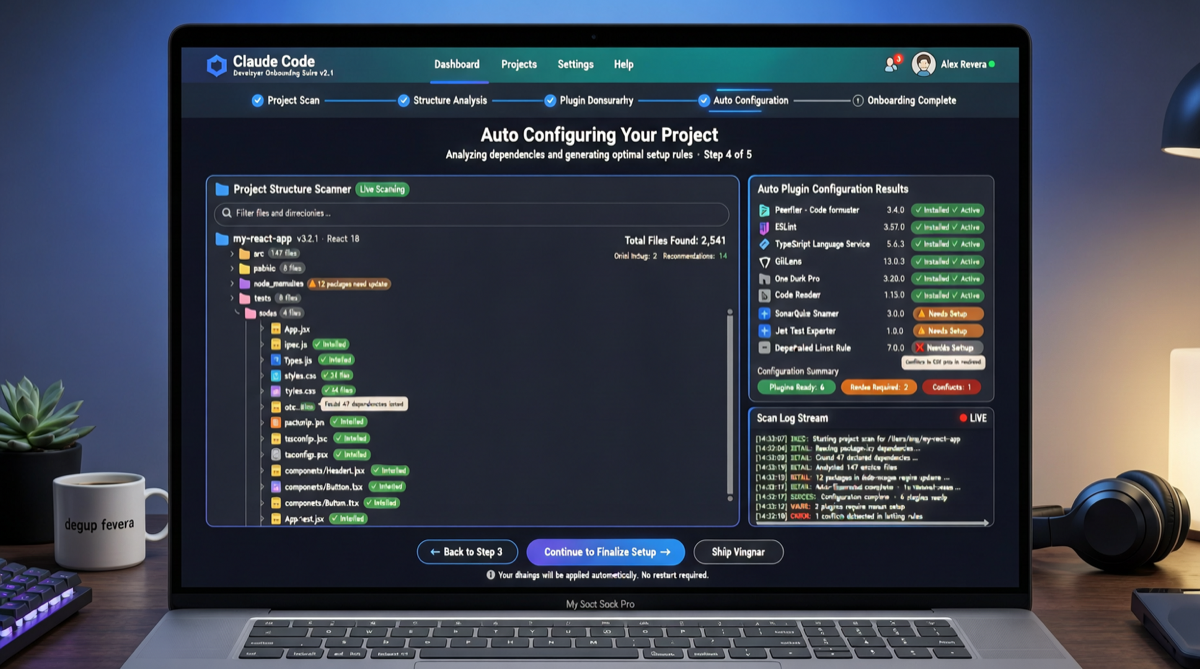
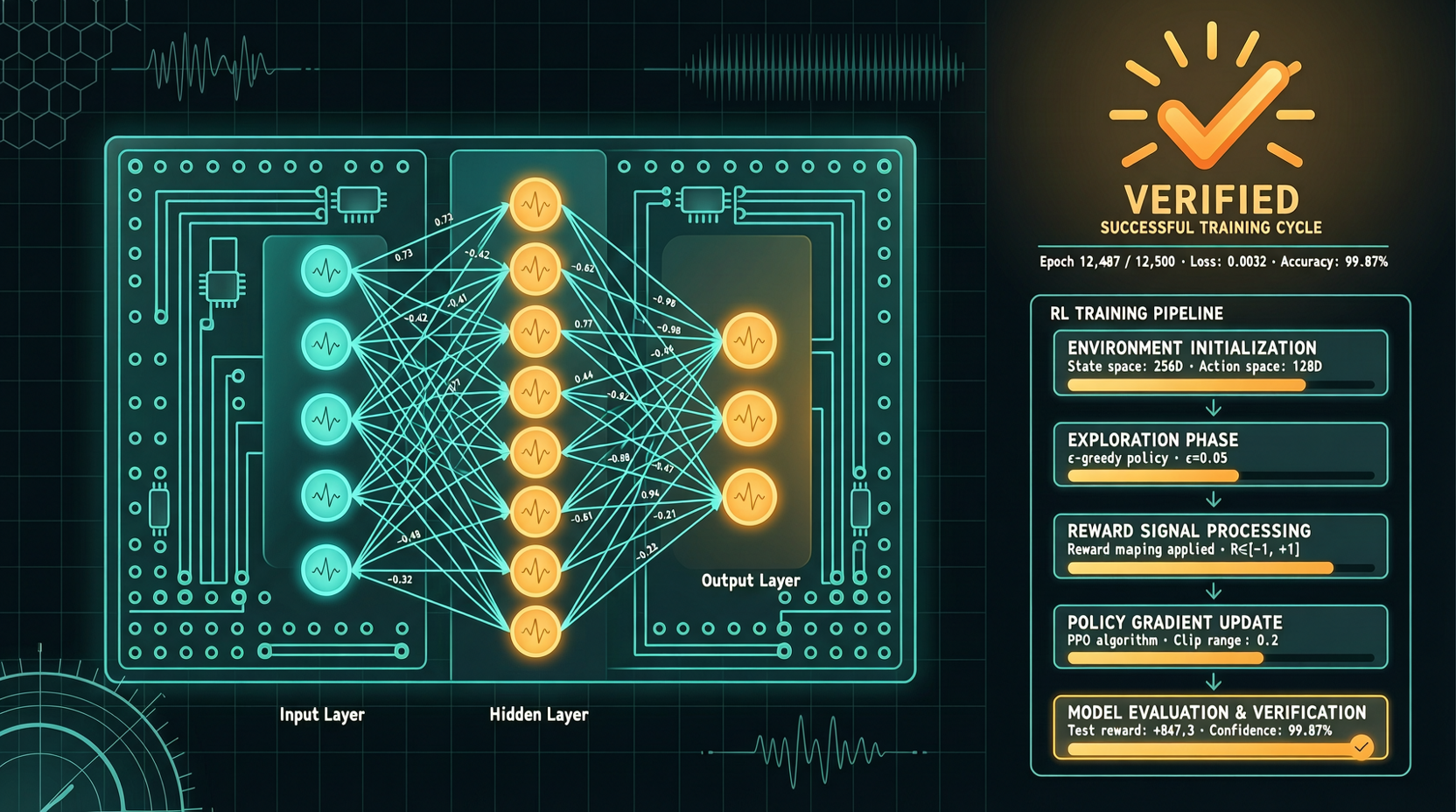
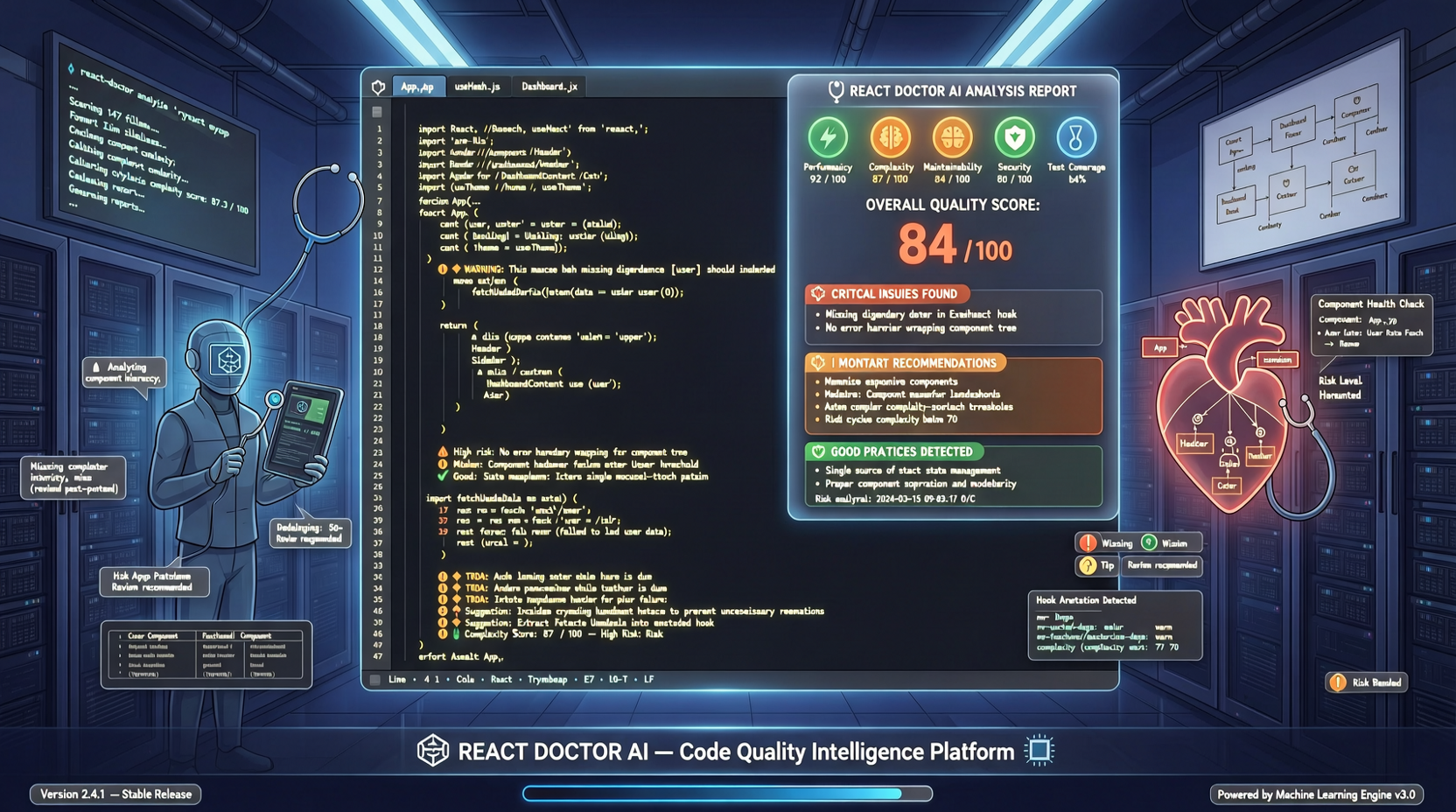
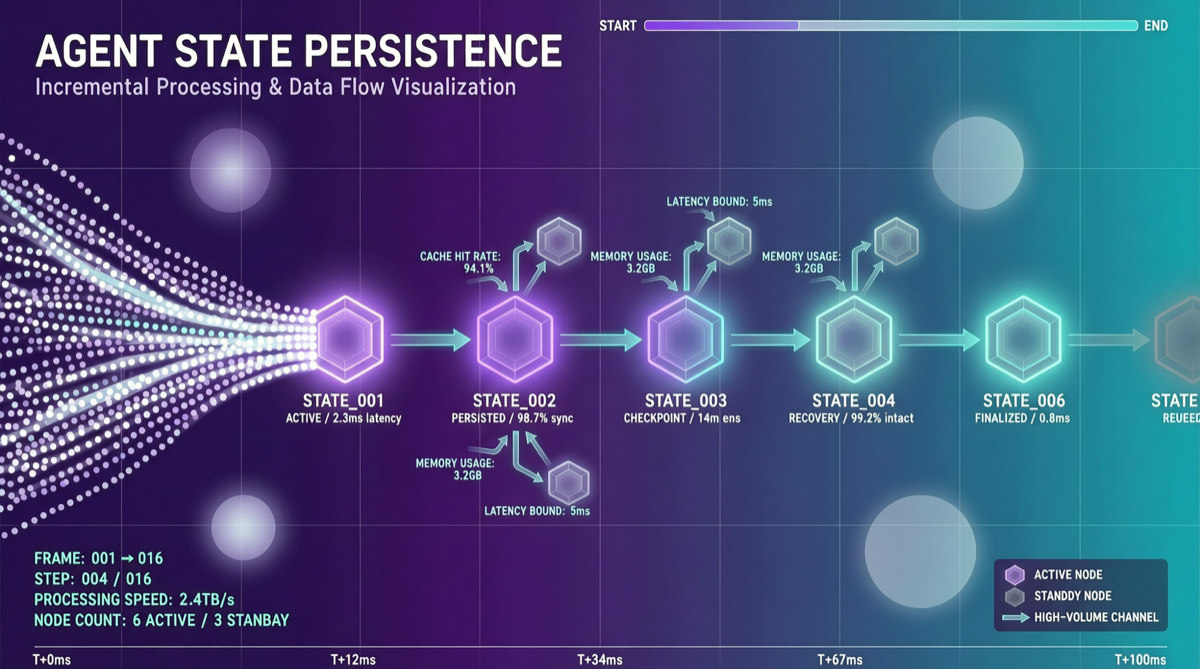
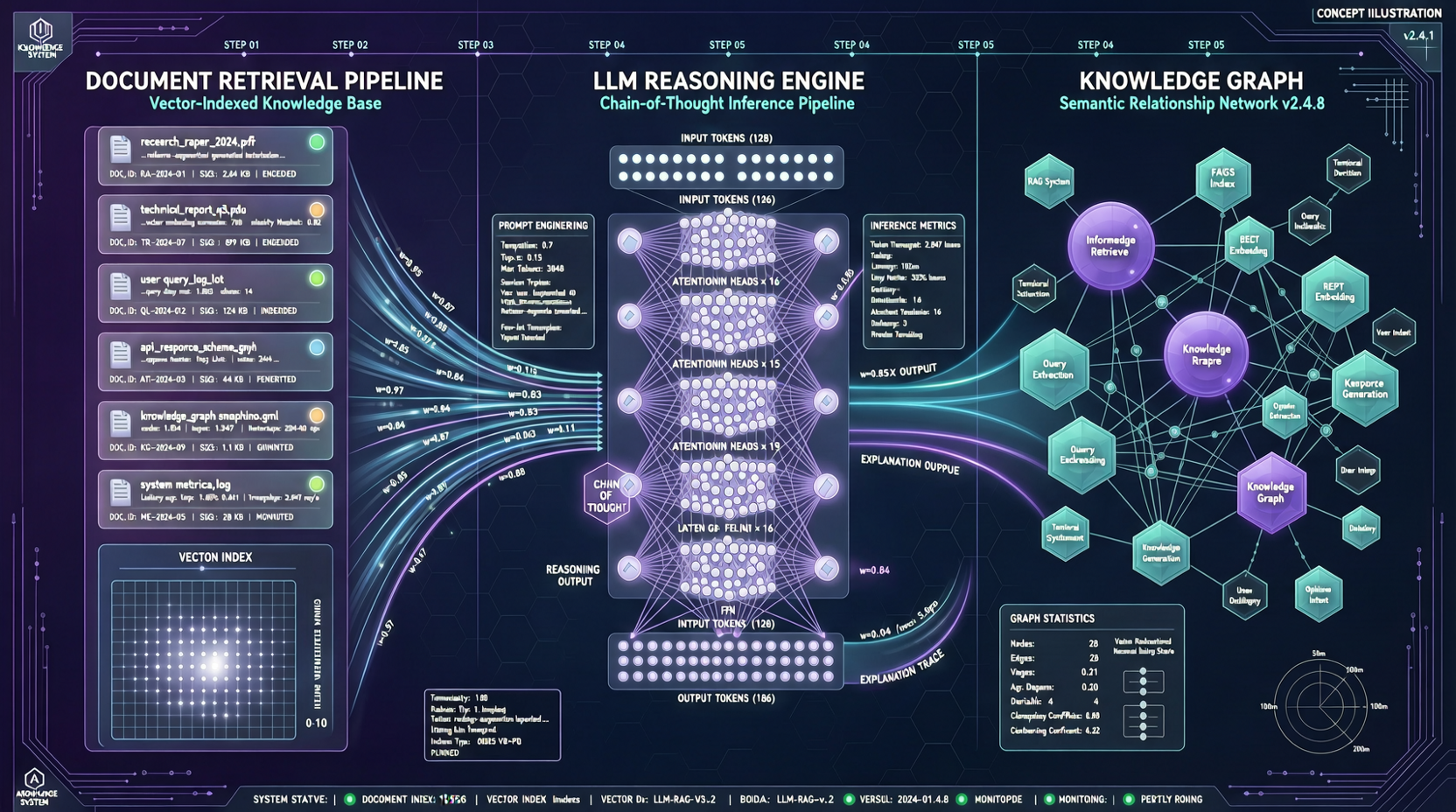
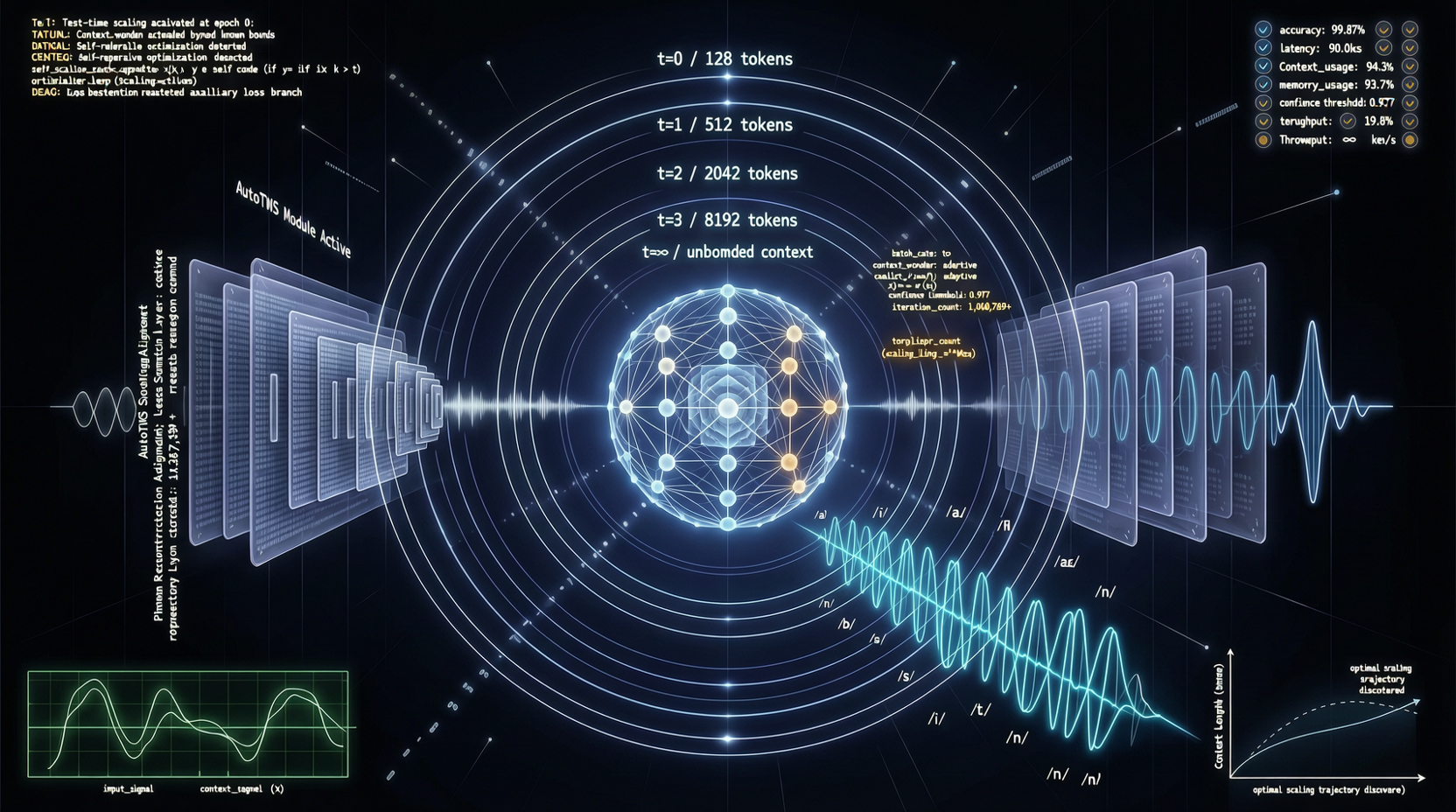
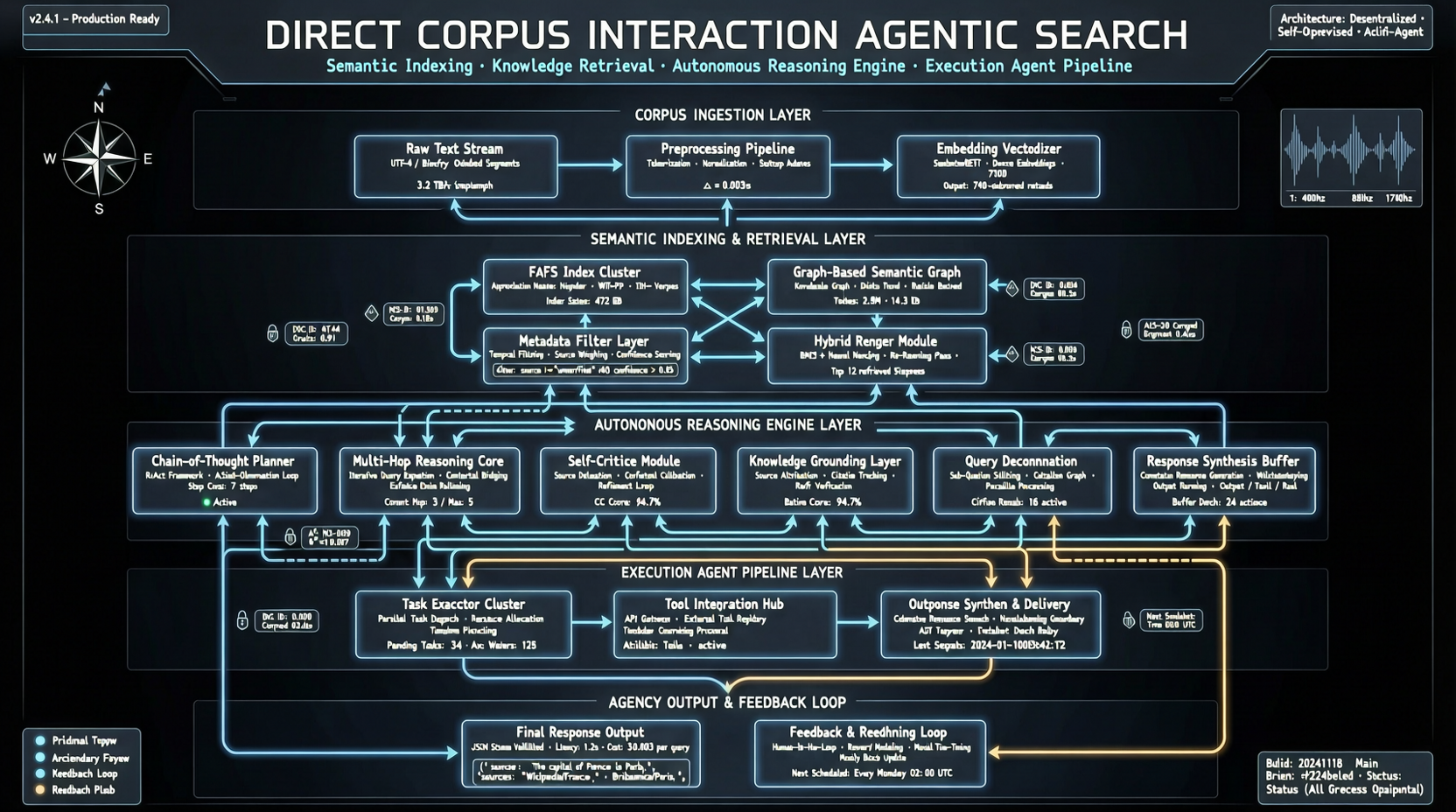
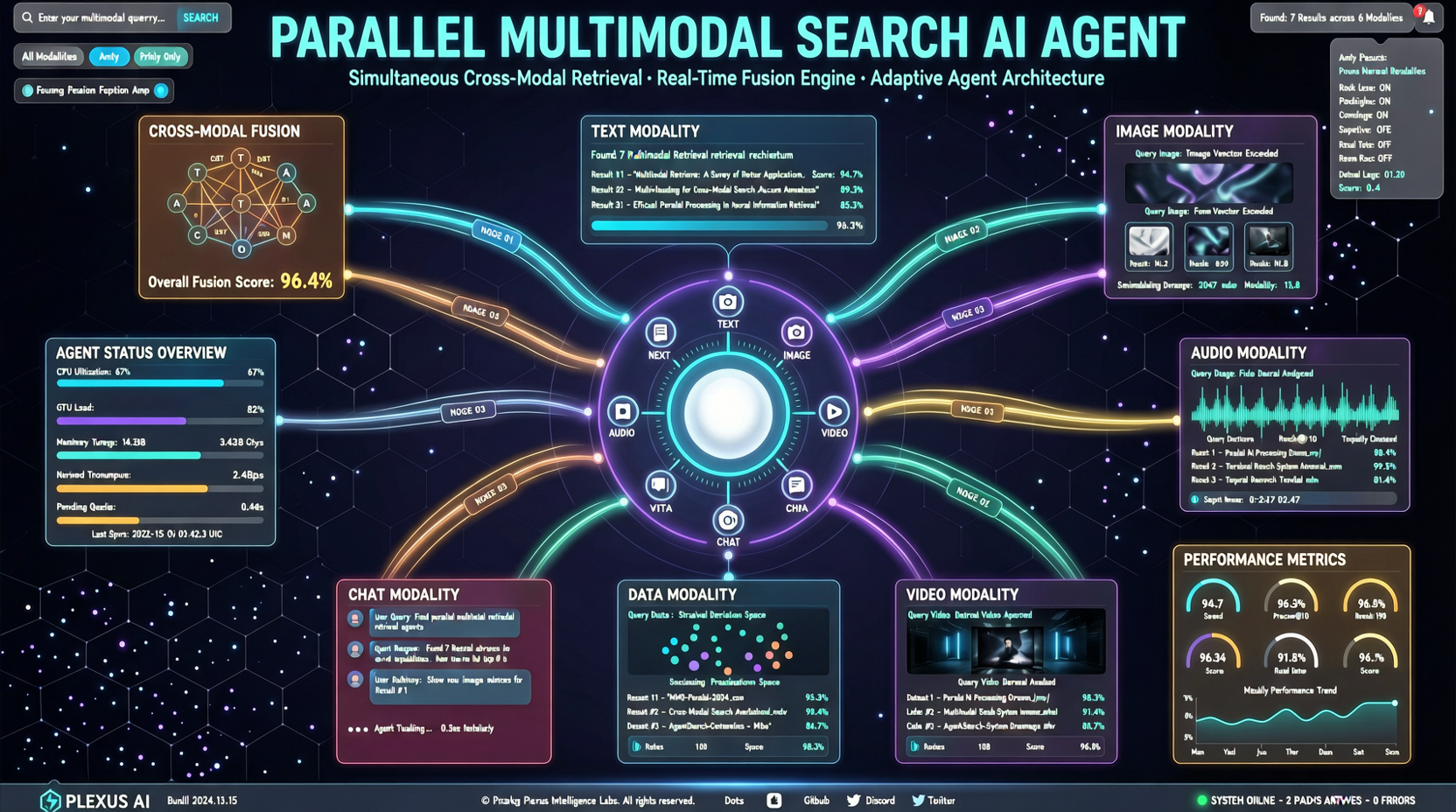
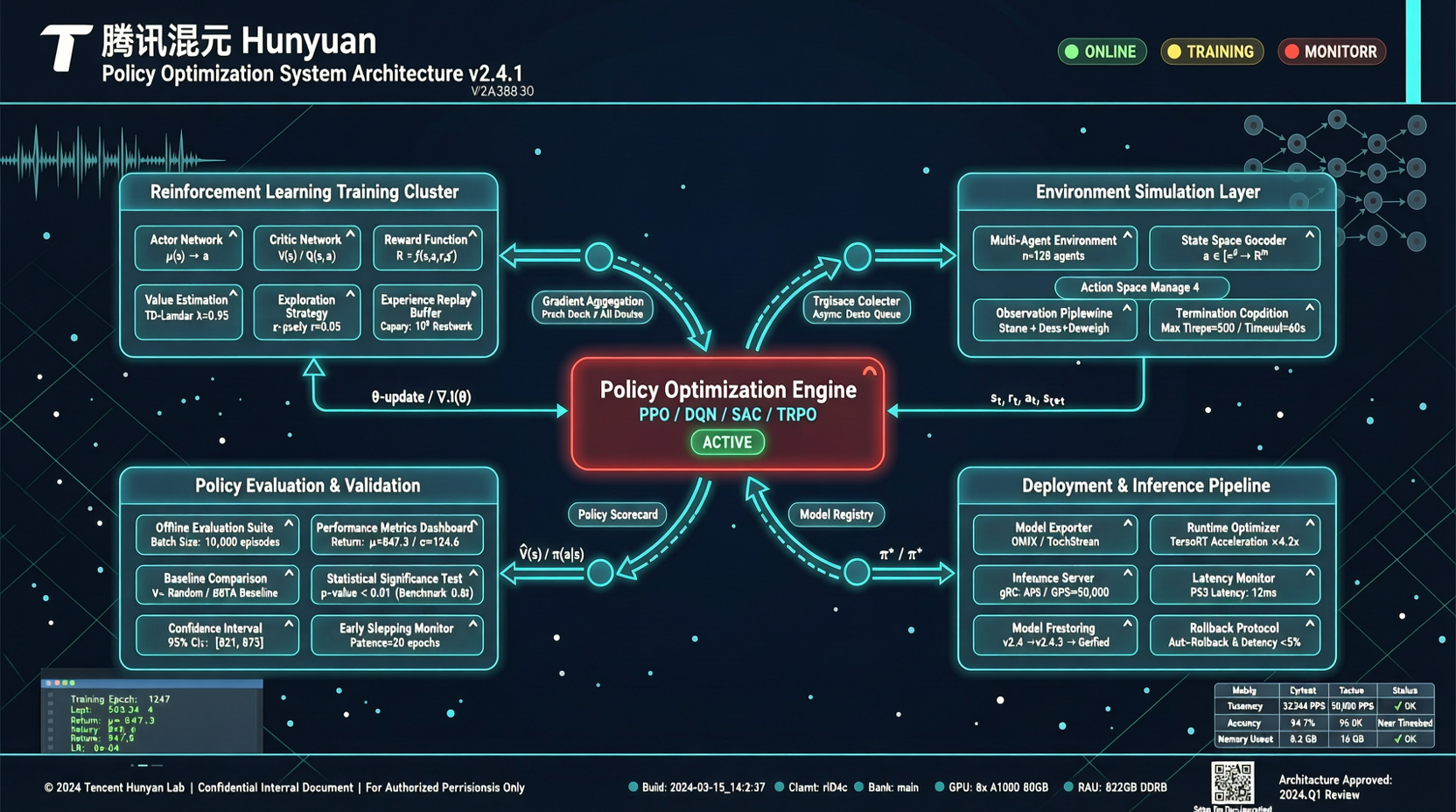
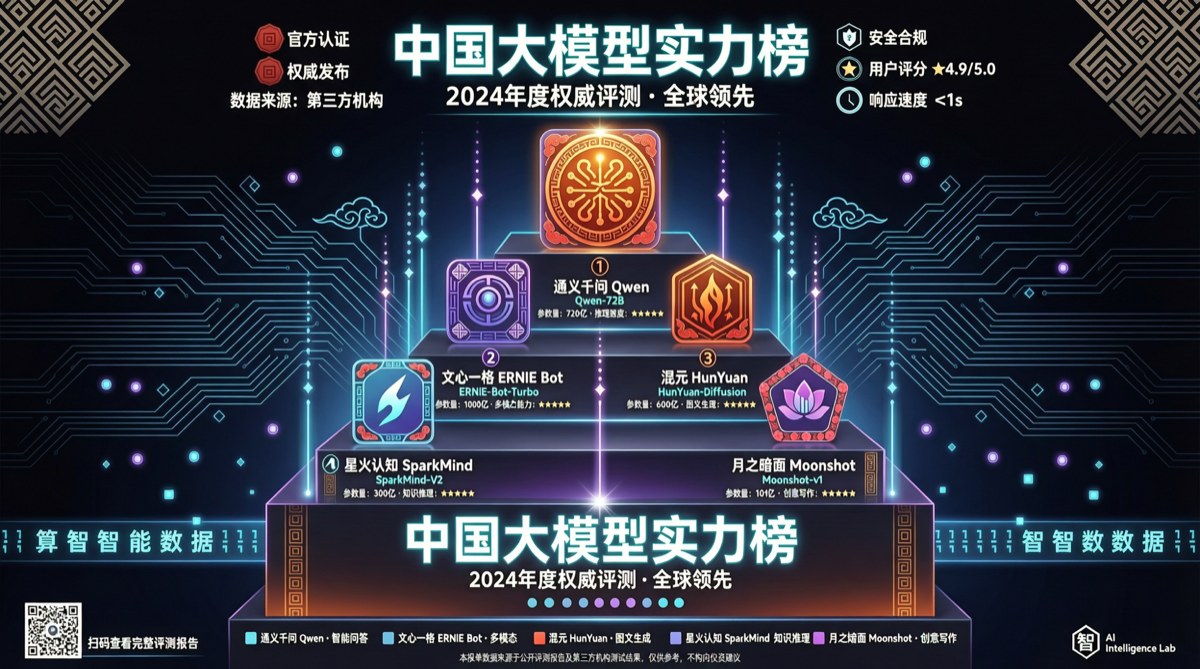
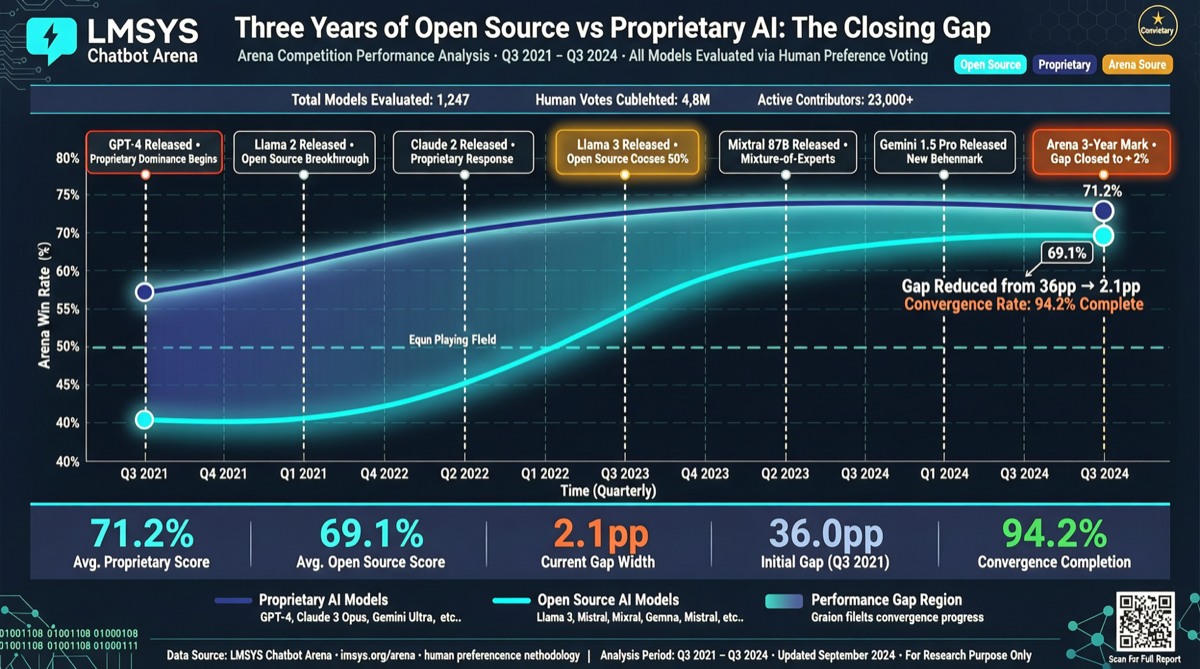
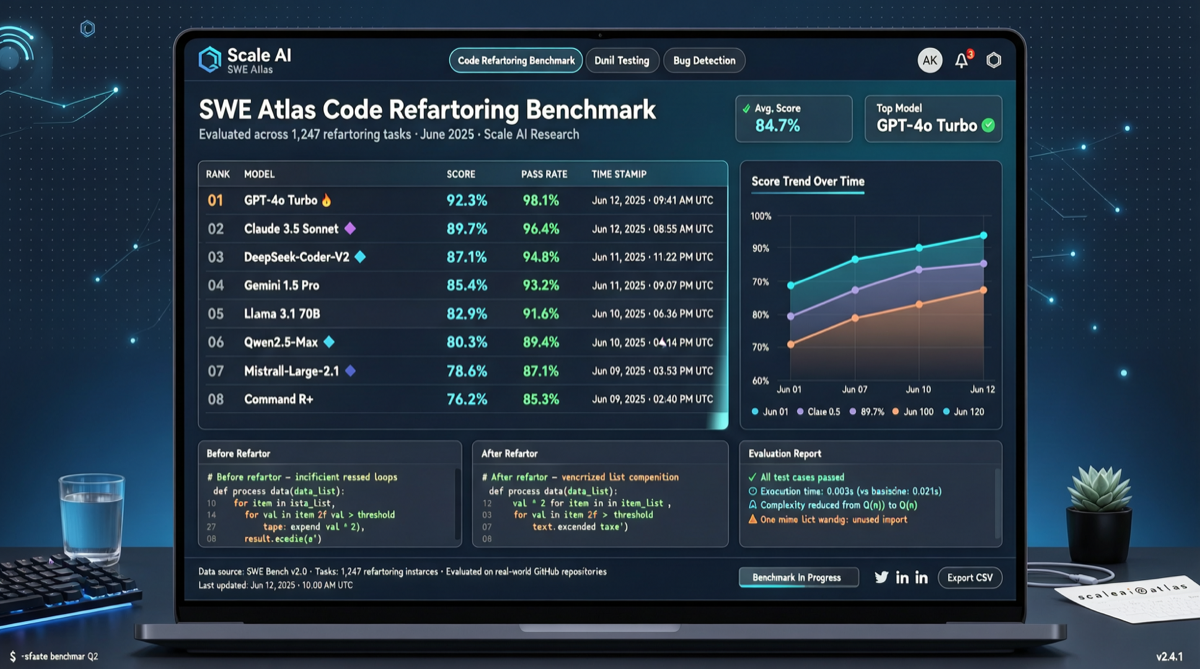
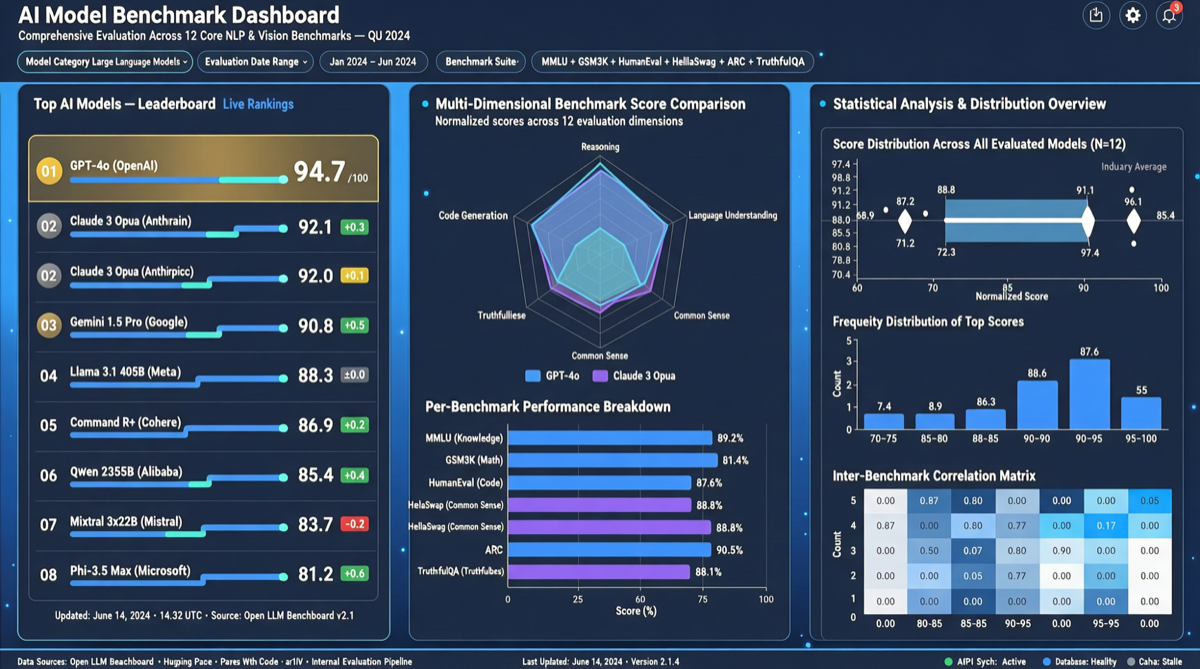
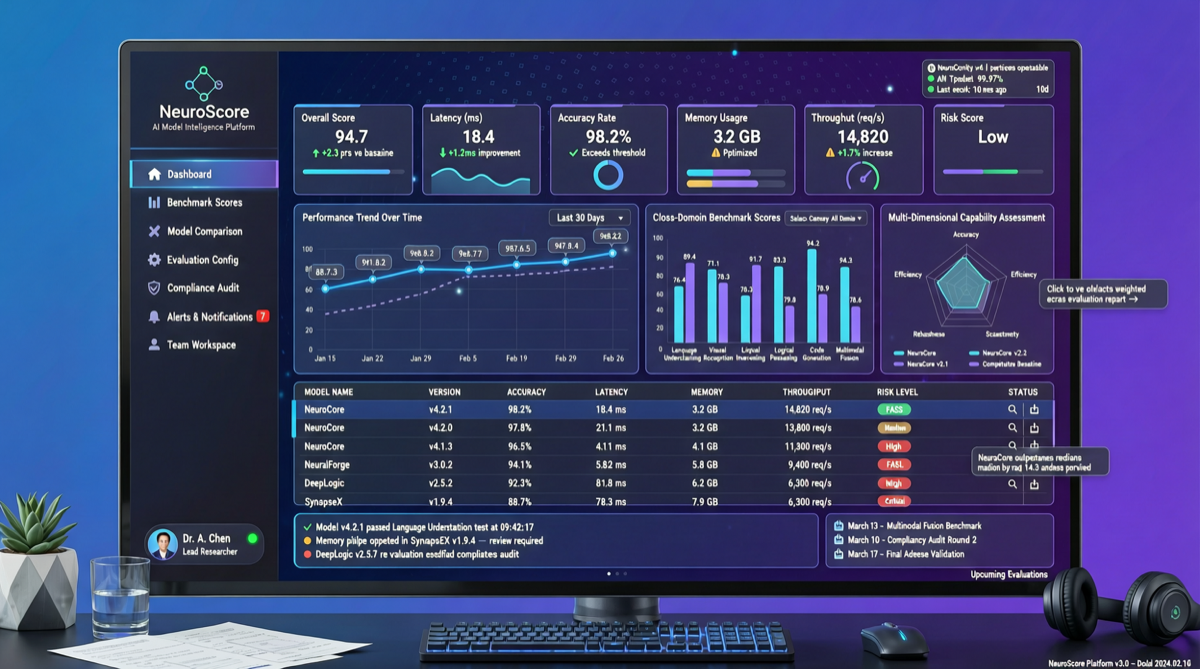
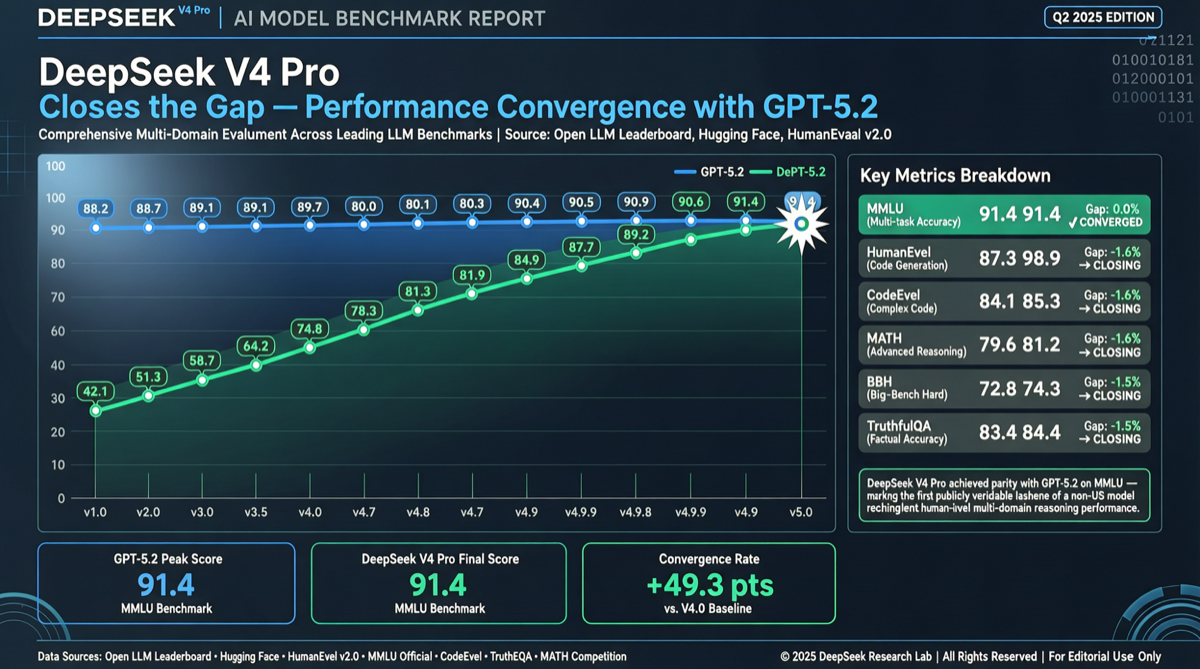
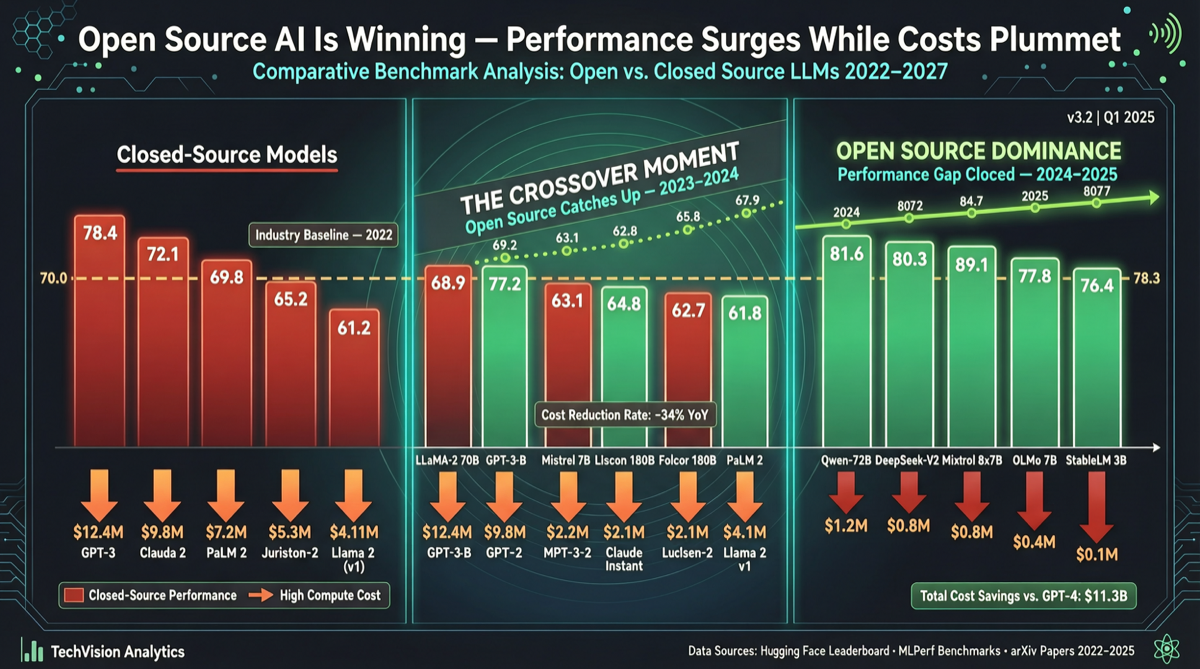
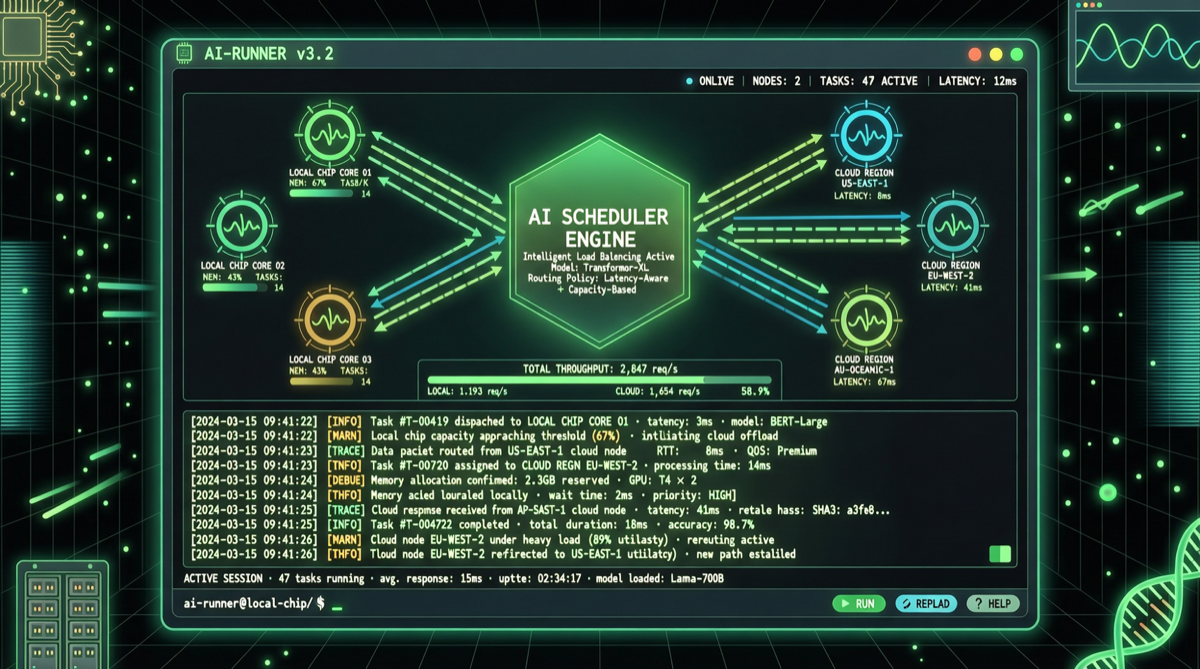
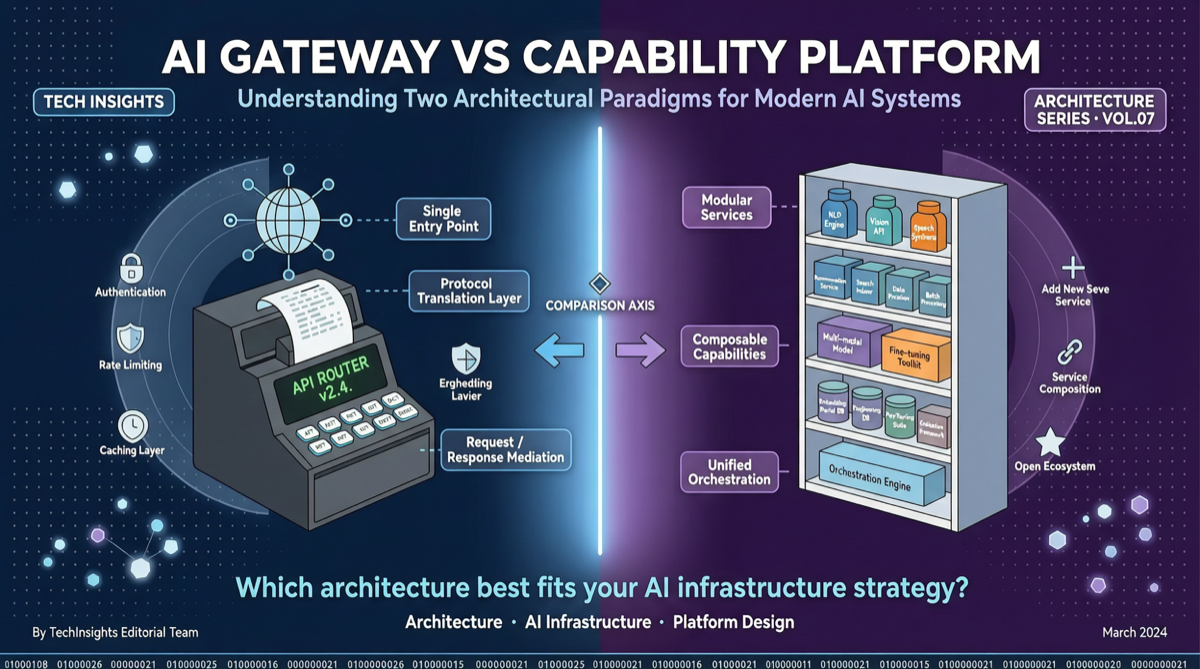
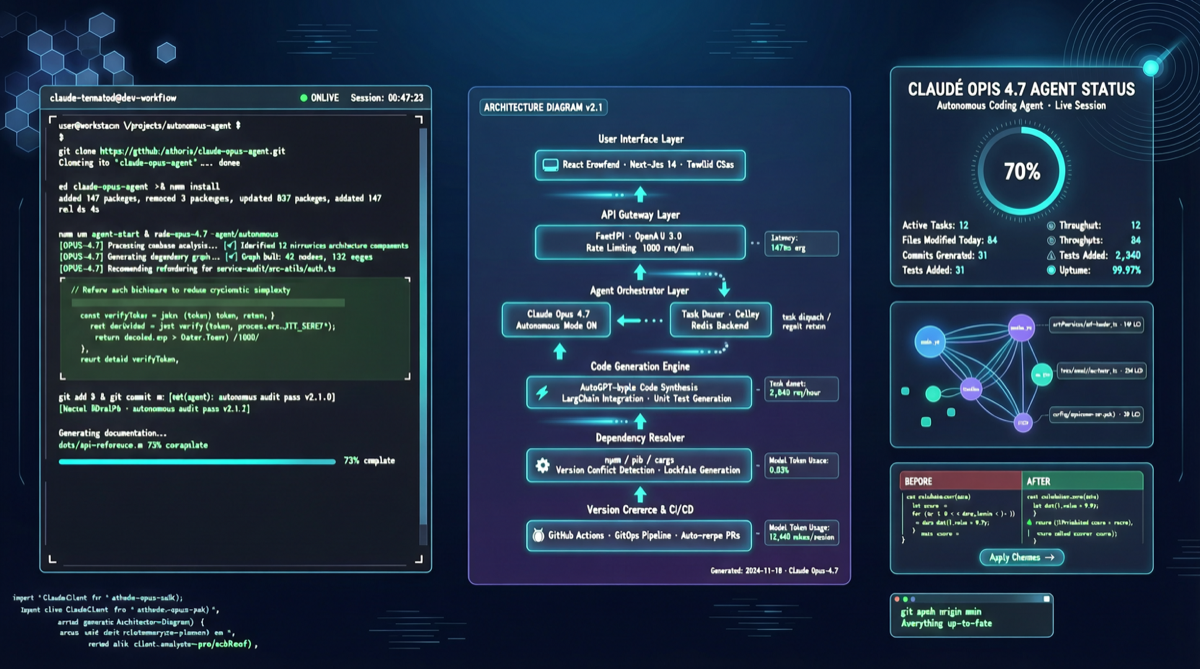
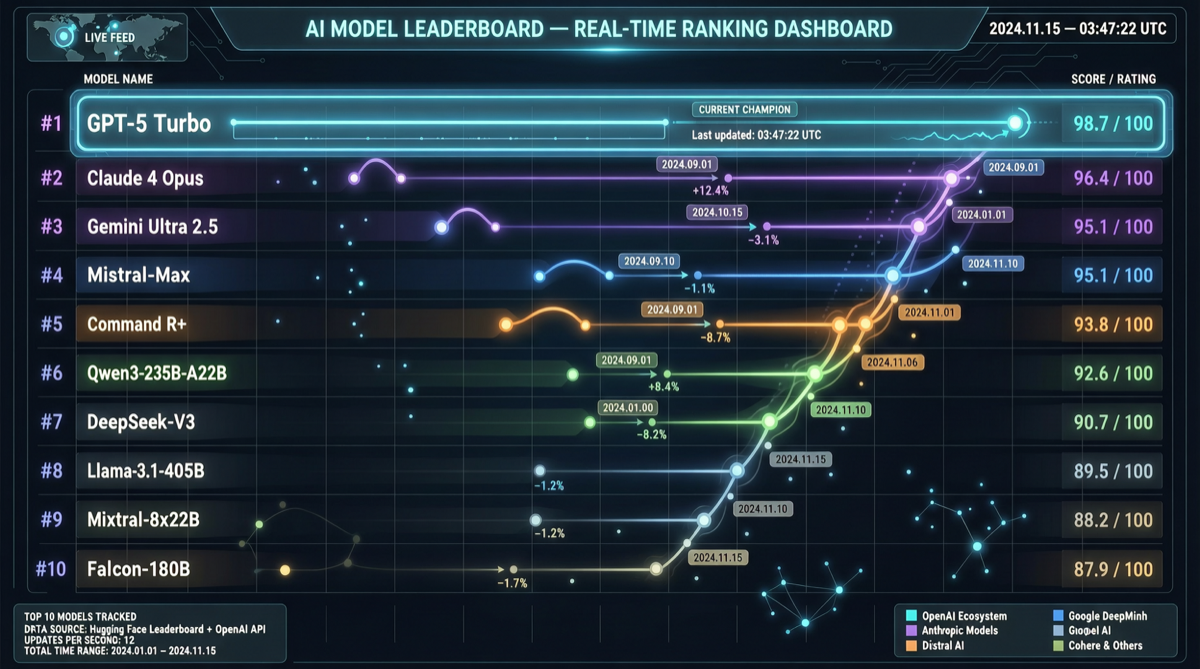
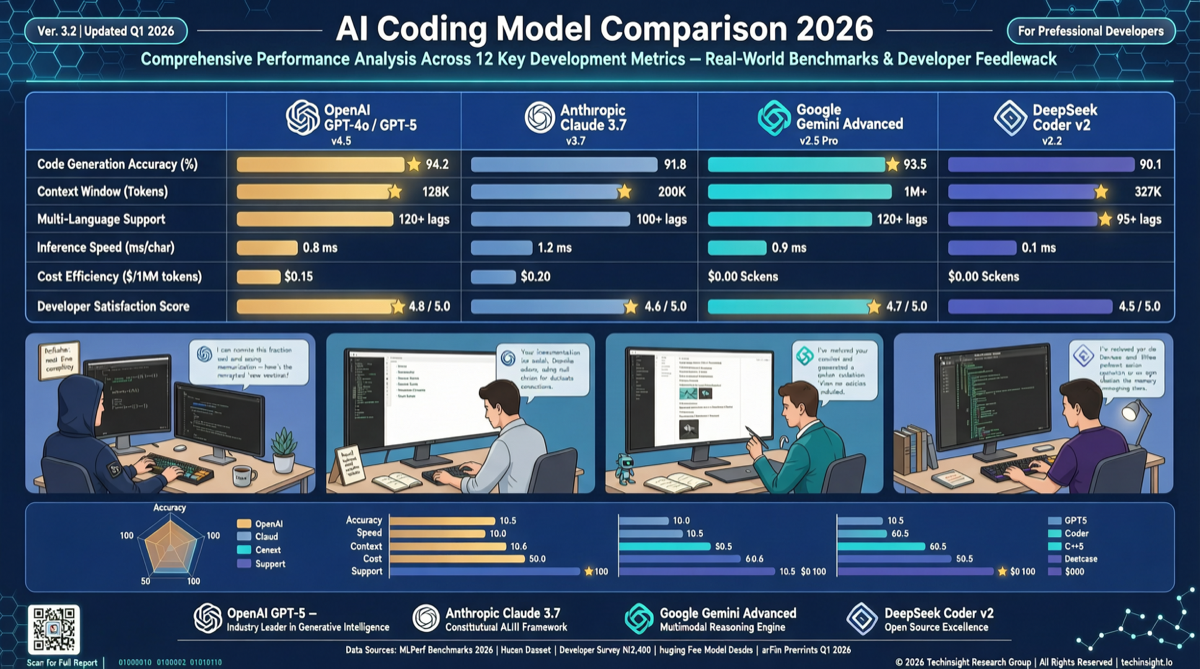
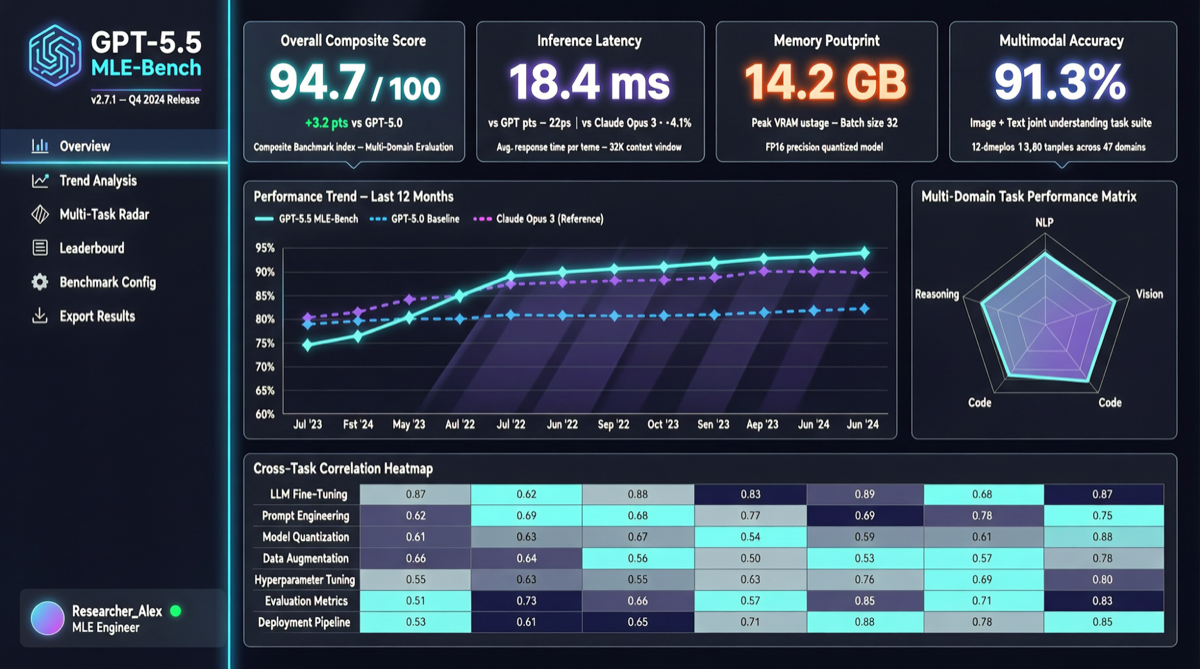
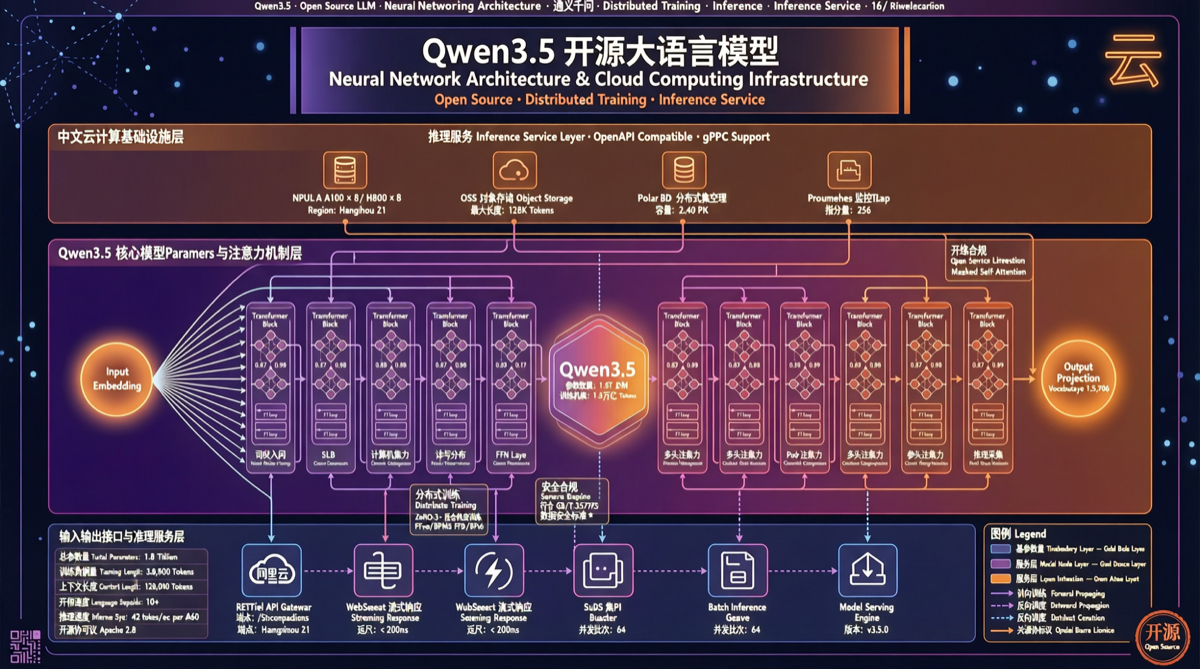
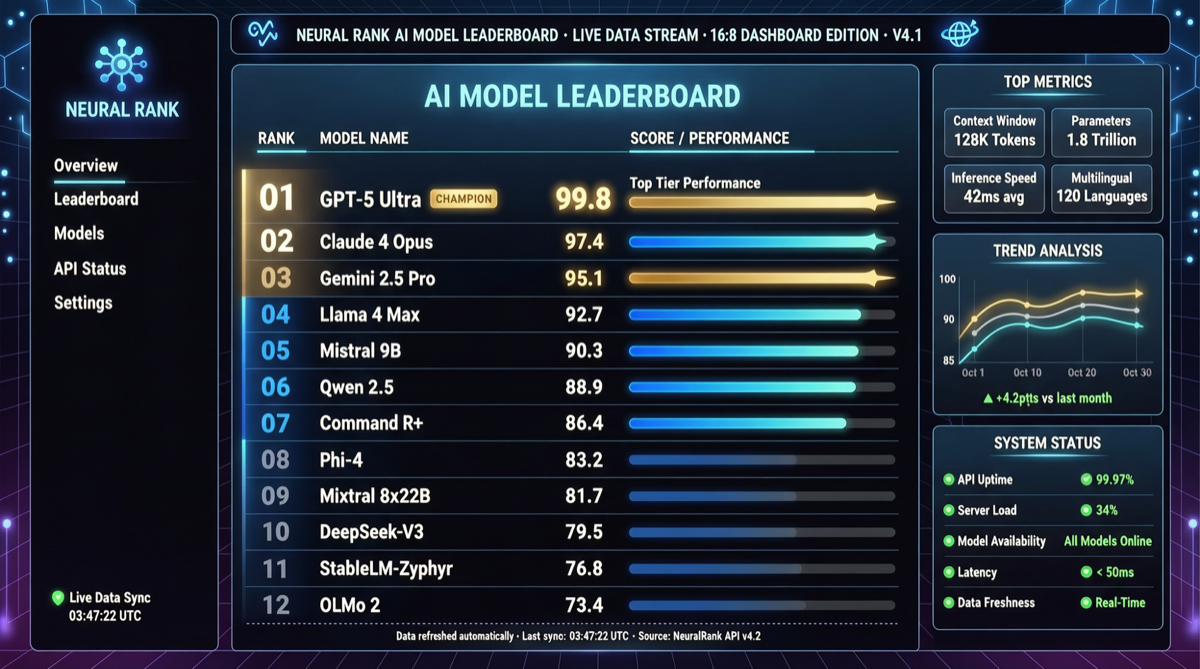
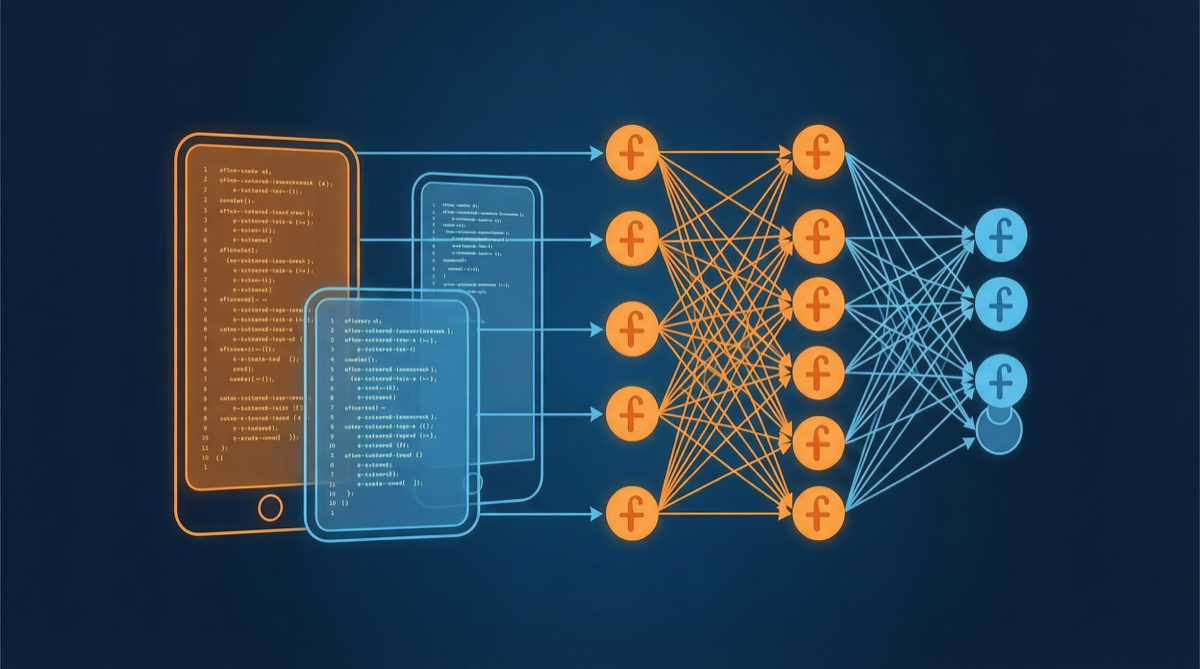
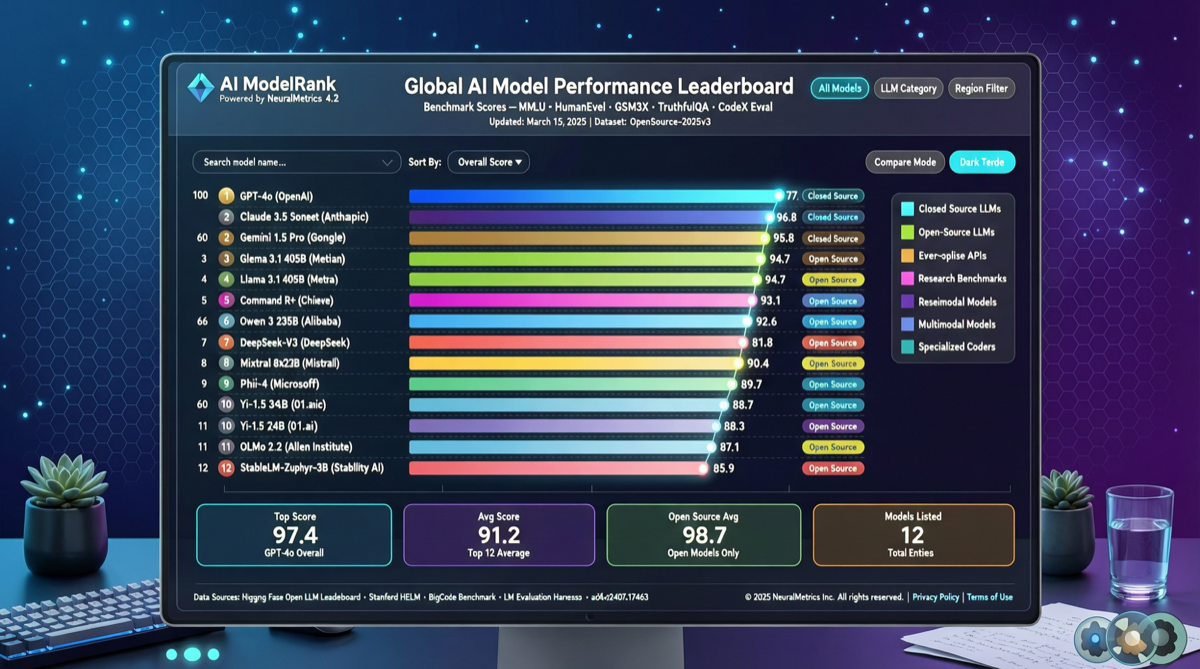
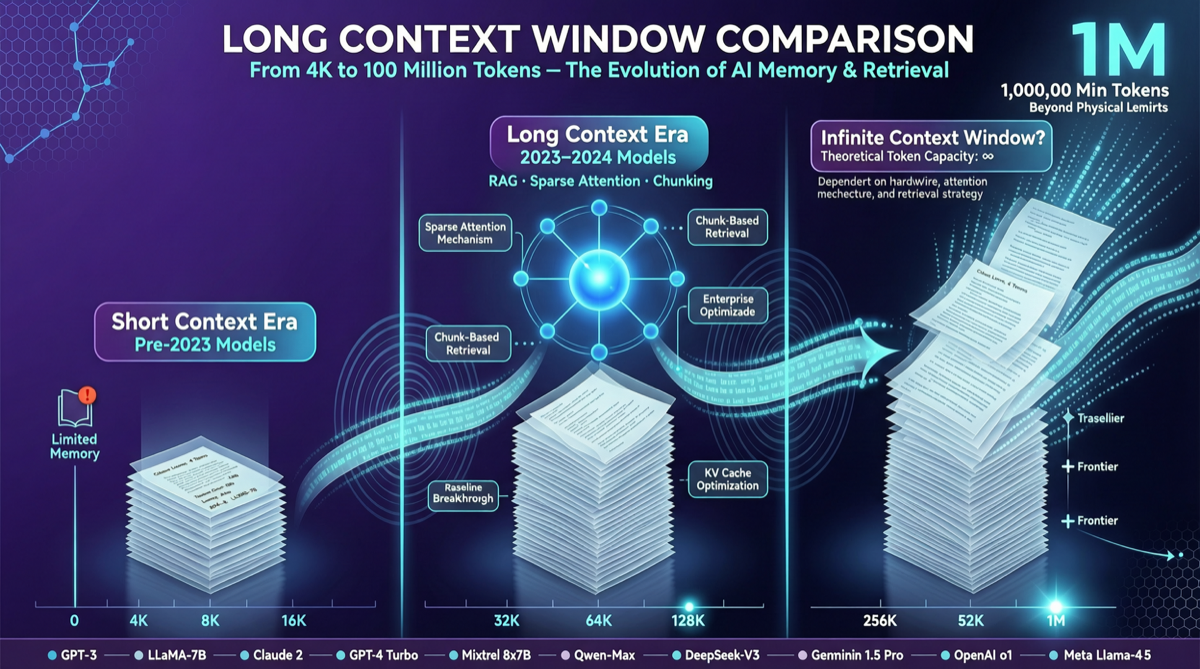
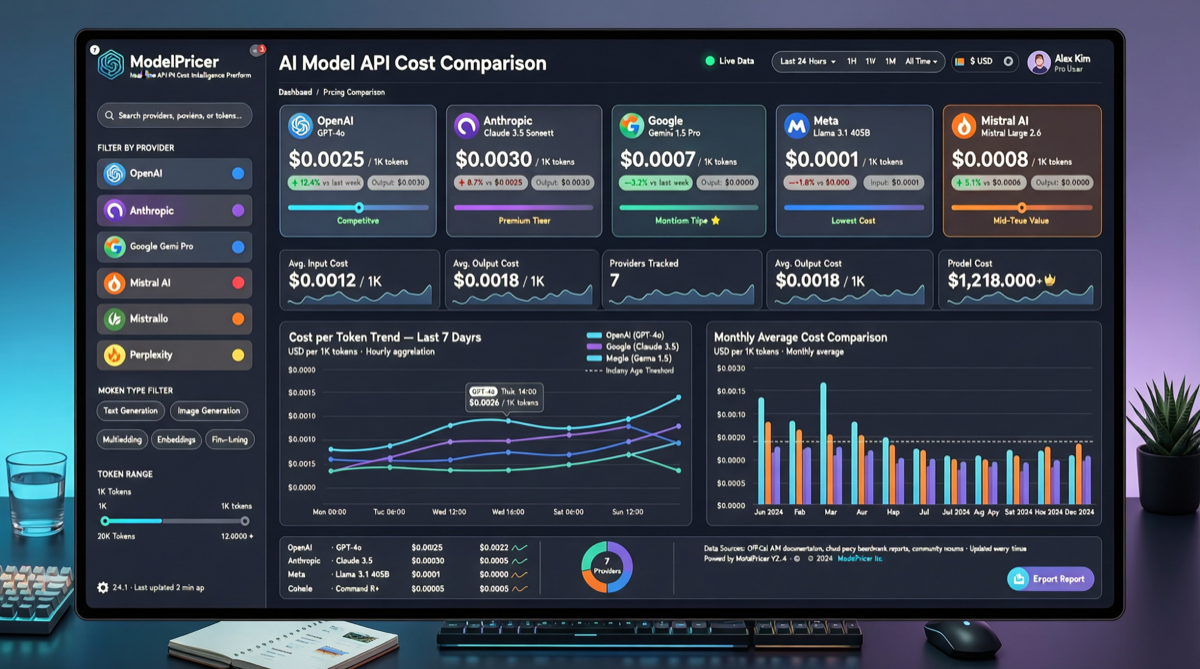
ACC: Компиляция траекторий агентов в длинные контекстные QA-пары
ACC компилирует многоходовые траектории вызовов инструментов агента в длинные контекстные QA-пары, обучая модель интегрировать разрозненные доказательства. Qwen3-30B-A3B получает +18.1 на MRCR после обучения ACC, приближаясь к версии 235B.