Выводы в начале
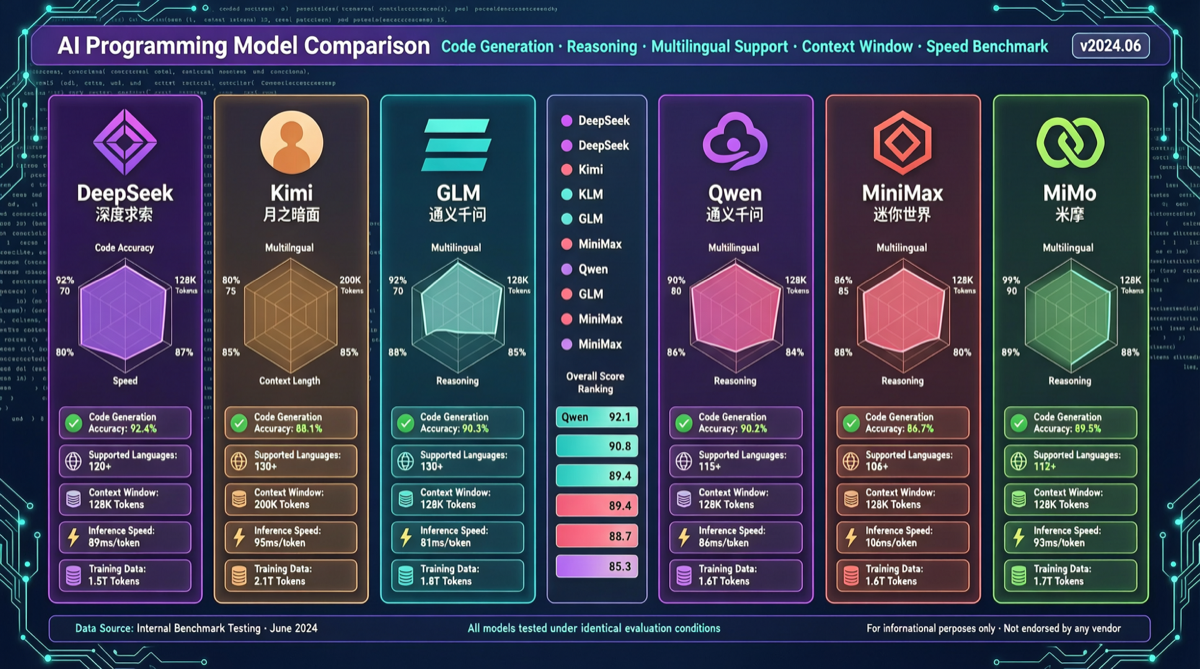
Пока большинство всё ещё следит за GPT и Claude, шесть китайских ИИ-моделей уже сформировали свои уникальные позиции в программировании. Недавний кросс-модельный тест кодинга показывает, что китайские модели больше не просто «альтернативы GPT» — они прокладывают дифференцированные пути в стиле мышления, архитектуре кода и эффективности исполнения.
Ключевые результаты:
| Модель | Сильнейшее измерение | Стиль | Лучше всего для |
|---|---|---|---|
| DeepSeek | Сложное мышление | Движок логики, пошаговый разбор | Алгоритмы, проектирование архитектуры |
| Kimi K2.6 | Обучение коду | Как учитель, объясняет каждое решение | Обучение, ревью кода |
| Zhipu GLM 5.1 | Архитектура кода | Самая чистая структура в стиле разработчика | Инженерные проекты, командная работа |
| Qwen 3.6 | Эффективность | Эффективно и лаконично, сразу к делу | Быстрое прототипирование, генерация скриптов |
| MiniMax | Креативный кодинг | Нестандартные решения | Креативные проекты, UI/UX |
| Xiaomi MiMo | Мультимодальный кодинг | Голос + зрение + код, полный стек | IoT, развёртывание на edge |
Фон тестирования
Тест запускал идентичные промпты кодинга на всех шести моделях, сравнивая качество вывода, структуру кода, процесс мышления и фактические результаты исполнения. Это не сравнение бенчмарков — это реальное «одна задача, шесть решений».
Измерения тестирования
- Правильность кода: Компилируется ли? Верна ли логика?
- Прозрачность мышления: Чётко ли объясняет ход мысли?
- Стандартизация кода: Именование, структура, комментарии соответствуют инженерным стандартам?
- Эффективность исполнения: Соотношение потребления токенов к качеству вывода
- Различия в стилях: Как разные модели подходят к одной задаче
Анализ по моделям
DeepSeek: Движок мышления
DeepSeek демонстрирует сильные характеристики «цепочки мышления». Сталкиваясь со сложными задачами, он:
- Сначала разбивает задачу на подзадачи
- Анализирует ограничения каждой подзадачи
- Постепенно строит решение
- В конце интегрирует и проверяет
Этот стиль особенно подходит для сценариев программирования, требующих глубокого мышления.
Kimi K2.6: Учитель
Выдающаяся особенность Kimi — «объяснимость». Он не просто пишет правильный код, но также:
- Объясняет, почему выбрана одна структура данных вместо другой
- Описывает, как обрабатываются граничные случаи
- Указывает на потенциальные возможности оптимизации
Уровень кодинга GPT 5.4, при этом цена — одна седьмая от Opus 4.7.
Zhipu GLM 5.1: Архитектор
Вывод GLM показал лучшие результаты в структурной стандартизации:
- Именование функций следует отраслевым соглашениям
- Разделение модулей чёткое
- Обработка ошибок полная
Qwen 3.6: Игрок эффективности
Дифференцированное преимущество Qwen — «меньше слов, больше дела»:
- Наименьшее потребление токенов
- Вывод сразу переходит к делу
- Лучшая производительность на потребительском оборудовании
MiniMax: Креативный игрок
MiniMax продемонстрировал совершенно иной подход к решению задач. Когда другие модели давали стандартные ответы, MiniMax:
- Пробовал нестандартные алгоритмы
- Давал дополнительные предложения по UI/UX
Xiaomi MiMo: Универсал
Как новичок, особенность MiMo — «немного умеет во всём»:
- Голосовое программирование
- Визуально-ассистированное программирование
- Поддержка открытого ASR диалектов
- Дружественность к edge-развёртыванию
Сравнение цен: китайские модели переопределяют ценообразование
| Модель | Цена относительно Opus 4.7 | Окно контекста | Открытый исходный код |
|---|---|---|---|
| Kimi K2.6 | ~14% | 200K | ✅ |
| GLM 5.1 | ~19% | 128K | ✅ |
| DeepSeek V4 | ~5% | 1M | ✅ |
| Qwen 3.6 | ~8% | 256K | ✅ |
Оценка ландшафта
- Дифференцированная конкуренция — факт: китайские модели больше не гонятся за «превзойти GPT во всём»
- Открытый исходный код становится стандартом: пять из шести моделей предлагают open-source версии
- Скорость вывода остаётся проблемой: большинство пользователей сообщают, что китайские модели всё ещё медленнее
- Мультимодальность — следующее поле битвы
Рекомендации
| Ваша потребность | Рекомендуемая модель |
|---|---|
| Сложные алгоритмы/архитектура | DeepSeek V4 |
| Обучение программированию/ревью кода | Kimi K2.6 |
| Инженерные проекты/командная работа | GLM 5.1 |
| Быстрое прототипирование/локальное развёртывание | Qwen 3.6 |
| Креативные проекты/UI-дизайн | MiniMax |
| IoT/edge мультимодальность | MiMo |
Ключевая рекомендация: перестаньте держаться за одну модель. Переключайте модели в зависимости от типа задачи — это лучшая стратегия для оптимального опыта кодинга и контроля затрат.