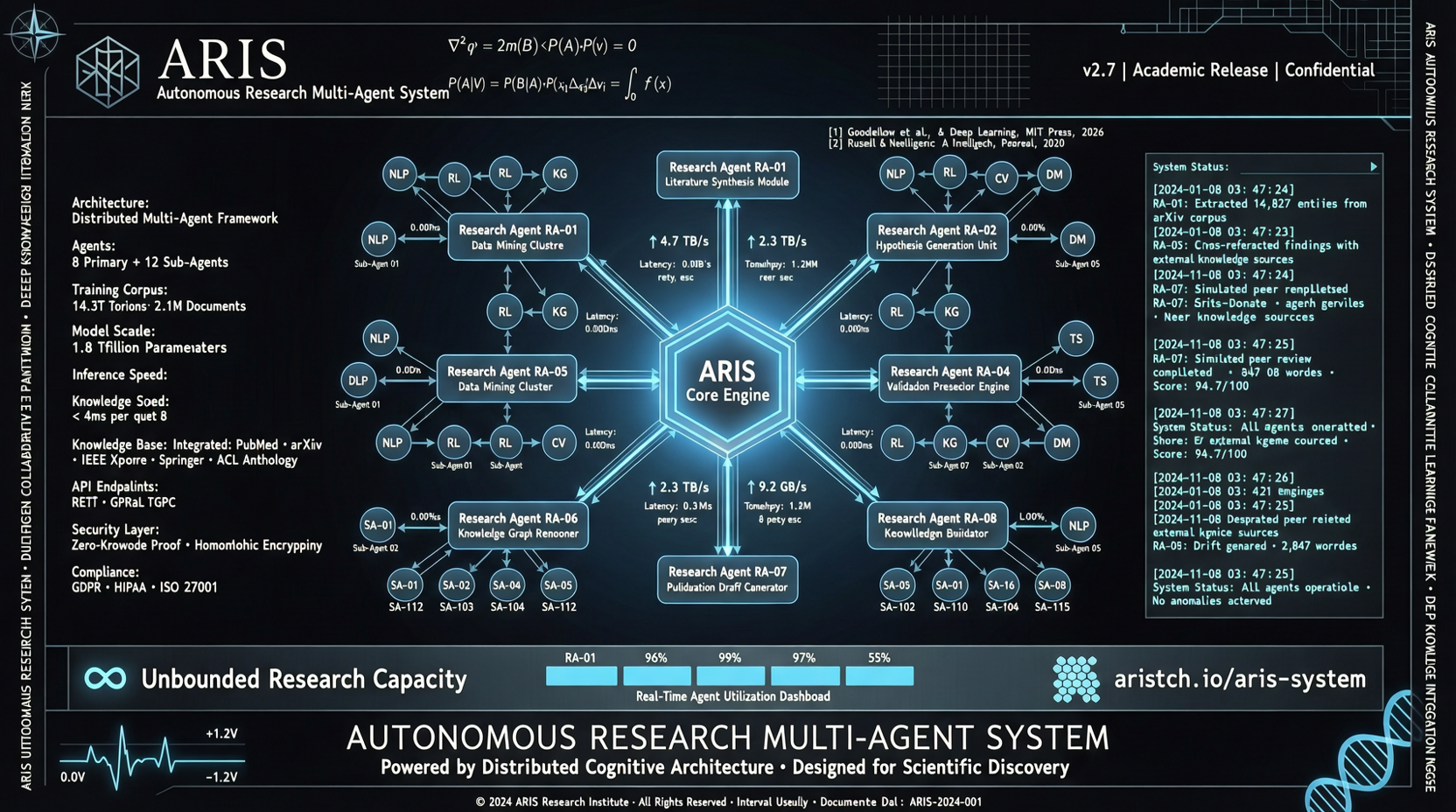
APWA: Распределённая архитектура для истинной параллелизации мультиагентных систем
APWA предлагает распределённую архитектуру, ориентированную на параллелизуемые рабочие нагрузки агентов, которая решает проблемы масштабирования инференса, координации и вычислений в мультиагентных системах при росте масштаба и сложности задач.