APWA:マルチエージェントシステムを真に並列化する分散アーキテクチャ
APWAは、並列化可能なエージェントワークロード向けの分散アーキテクチャを提案し、タスクの規模と複雑さが増大する際のマルチエージェントシステムにおける推論、調整、計算の拡張ボトルネックを解決します。
論文、ベンチマーク、データセット、実験手法の重要な進展を追跡
APWAは、並列化可能なエージェントワークロード向けの分散アーキテクチャを提案し、タスクの規模と複雑さが増大する際のマルチエージェントシステムにおける推論、調整、計算の拡張ボトルネックを解決します。
DDCは、信頼度重み付きベイズプロトコルとトレンド認識型階層プルーニングを用いた統一された推論時スケーリングフレームワークを提案します。5つのベンチマークにおいてベースラインの精度を維持または上回りながら、トークン消費を10倍以上削減します。
MemEyeは、視覚を中核としたマルチモーダルエージェントの記憶評価フレームワークを提案します。17名の研究者による共同研究から生まれ、エージェント記憶システムの評価における空白を埋めるものです。
NVIDIAがMemLensを発表。大規模視覚言語モデル(LVLM)の多モーダル長期記憶能力に特化した初のベンチマークであり、LVLMの記憶評価における空白を埋めるもの。
マイクロソフトリサーチがOrchardをオープンソース化。スケーラブルなエージェントモデリングフレームワークです。コードエージェントからGUIエージェント、パーソナルアシスタントまで、統一された軽量環境レイヤーでクロスドメイン訓練を実現します。SWE-bench Verifiedで67.5%を達成し、GUIエージェントはわずか400件の蒸留軌跡でオープンソース最強を記録しました。
OpenDataLabがCiteVQAベンチマークを公開。ドキュメントインテリジェンスシステムにおける回答の証拠追跡能力を専門的に評価する。HuggingFace Daily Papersで143票を獲得し首位に——信頼できるAIが、単なるスローガンから定量化可能な技術指標へと進化している。
香港大学HKUDSチームが公開したCLI-AnythingプロジェクトがGitHub Trendingで1位を獲得し、スター数は36,000以上を記録。その核となる理念は、すべてのソフトウェアを「Agentネイティブ」に変えることだ。これは単なるツールではなく、ソフトウェアアーキテクチャに対する思考の転換である。
上海交通大学がMMSkillsフレームワークを発表し、マルチモーダル視覚エージェントの能力を、組み合わせ可能で再利用可能なスキルユニットに分離しました。Hugging Faceのホットペーパーで99票を獲得——エージェントの「スキル化」は「モデル化」よりも未来に近いアプローチかもしれません。
DeepCyboがPhysBrain 1.0の技術レポートを発表し、物理法則を理解できるAIシステムの構築を目指している。直観的物理学から動画生成による検証まで、この技術路線は純粋な言語モデルよりも真の「知能」に近い可能性がある。
騰訊混元チームが新論文を発表し、モデルの潜在能力を解放する上でのOn-Policy Distillationの効率を体系的に研究した。本論文は、蒸留戦略の選択がモデル性能に与える重要な影響を明らかにし、大規模モデルのトレーニングに実証的な根拠を提供している。
TideGSはSSD-CPU-GPUの階層型ストレージ管理により、単一の24GB GPUで10億超のガウスプリミティブを用いた3DGS訓練を実現しました。これは従来のアウトオブコアベースライン(約1億)の10倍、インメモリ訓練(約1100万)の約100倍に相当します。本論文はICML 2026にてSpotlightとして採択されました。
Anti-SD 通过点互信息(PMI)分析发现,特权上下文会抑制模型在推理过程中生成“思考型”token(deliberation token)。为此,该研究提出“反向自蒸馏(Anti-Self-Distillation)”方法:不追求学生模型与教师模型趋同,反而刻意增大二者输出分布的散度。在数学推理基准测试中,该方法仅需GRPO基线方法2~10倍的训练步数即可达到同等准确率,最终准确率最高提升11.5分。
CogOmniControl は、推論駆動型の制御可能な動画生成フレームワークを提案し、生成プロセスを「創造的意図の認知」と「動画生成」の2段階に分解します。専門的なアニメ制作データで訓練されたCogVLMは、疎で抽象的な条件を正確に理解でき、CogOmniDiTおよび強化学習(RL)による整合性最適化と組み合わせることで、著者らが独自に構築した2つのベンチマークにおいて既存のオープンソースモデルを上回る性能を達成しました。
GoLongRLは、完全にオープンソース化された長文脈強化学習(RL)後の微調整手法を提案し、23,000件のRLVRサンプルからなるデータセットおよび完全なトレーニングコードを公開しています。Qwen3-30B-A3Bモデルは、長文脈タスクにおいてDeepSeek-R1-0528およびQwen3-235B-A22B-Thinking-2507と同等の性能を発揮します。
OpenComputer は検証器ベースのフレームワークを提案し、computer-use agent 向けに検証可能なソフトウェア環境を構築する。33のデスクトップアプリと1000のタスクをカバーしており、実験により、そのハードコードされた検証器は LLM-as-judge よりも人間の評価に近いことが示された。
シンガポール国立大学(NUS)など複数の機関が共同で発表したAIによる完全自動科学研究ロードマップは、AIが研究ライフサイクル全体においてどこまで活用可能かを体系的に分析したものである。たとえば、1編の論文をわずか15ドルで自動生成できる一方で、大規模言語モデル(LLM)は依然として結果をでっち上げたり、隠れたエラーを見落としたり、革新的性を信頼ably判断できなかったりする。
IAAR-ShanghaiとMemtensor Research Groupが、エージェントスキルのライフサイクル全体を管理するフレームワーク「SkillsVote」を提案。オフライン進化によりGPT-5.2のTerminal-Bench 2.0スコアが7.9ポイント向上し、オンライン進化によりSWE-Bench Proスコアが2.6ポイント向上した。
字節跳動は、ゼロから訓練されたネイティブな統合型マルチモーダルモデル「Lance」を発表しました。このモデルは画像および動画の理解、生成、編集をサポートします。デュアルストリーム型Mixture-of-Experts(MoE)アーキテクチャを採用しており、既存のオープンソース統合モデルと比較して生成品質で大幅に先行し、同時に優れた理解能力も維持しています。
Hugging Face「今日の論文」第1位に選出された、42名の著者(複数の著名な学術機関および産業界研究者を含む)による総説論文が、「コードをエージェント・ハーネスとして活用(Code as Agent Harness)」という統一的フレームワークを体系的に提唱。この枠組みでは、コードを、エージェントの推論・行動・環境モデリングを支える統合インフラストラクチャ層と位置づけている。
NVIDIAチームがLongLive-2.0を発表。NVFP4精度をベースとした長尺動画生成の学習・推論フルスタックシステムとしては初となる。シーケンス並列自己回帰学習とW4A4推論を導入し、学習速度を2.15倍、推論速度を1.84倍高速化。5Bモデルで45.7 FPSを達成。
NUSチームが「AI for Auto-Research」ロードマップを発表。アイデア創出から論文発表まで、研究ライフサイクル全体におけるAIの信頼性の境界を体系的に分析し、AIが単独で対応できる工程と、人間の監督が不可欠な工程を明確に示す。
清華大学チームが提案する KVPO は、探索の起点をランダムノイズから履歴 KV Cache へ移行することで、自己回帰型動画生成モデルにおける人間の嗜好へのアライメントを実現する、ODE-Native なオンライン GRPO フレームワークです。視覚品質、動作の自然さ、テキストと画像の一貫性のいずれにおいても向上が確認されています。
清華大学チームは低コストフレームワーク「ZEDA」を提案。学習済みの静的MoEモデルを動的MoEに変換し、Qwen3-30B-A3BおよびGLM-4.7-FlashにおいてエキスパートのFLOPsを50%以上削減。エンドツーエンドの推論速度を約1.2倍向上させる。
ByteDance Researchが発表したLanceは、軽量なネイティブ統一マルチモーダルモデルです。デュアルストリームMoEアーキテクチャとマルチタスク協調学習により、モデル容量の肥大化に依存することなく、画像/動画の理解、生成、編集を同時に実現します。
NVIDIAがLongLive-2.0を発表。NVFP4量子化と並列推論を活用した長尺動画生成インフラであり、GitHubで1.22kのスターを獲得。品質を維持したまま、より長い動画シーケンスを生成する手法を探求している。
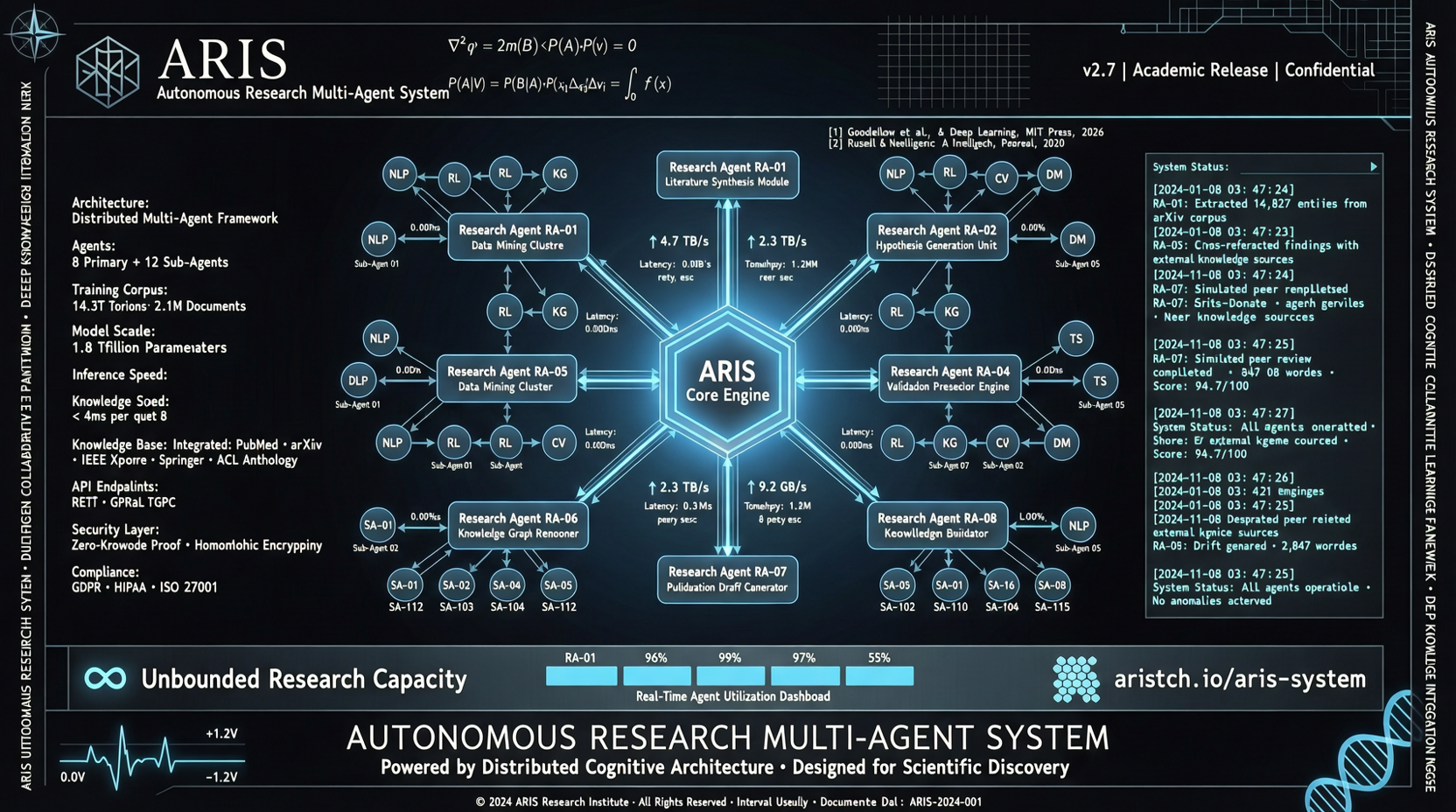
上海交通大学が発表したARISシステムは、複数のAIエージェントが敵対的連携によって自律的に研究タスクを遂行するものです。Papers with Codeで116のupvote、GitHubで9.7kのstarを獲得しており、最近最も注目されているAI for Scienceプロジェクトの一つです。
清華MLグループのCausal Forcing++論文は、スケーラブルな少数ステップ自己回帰型拡散蒸留法を提案し、インタラクティブな動画生成を「数分待ち」から「リアルタイム応答」へ変革します。これはゲーム、VR、インタラクティブなコンテンツ制作にどのような意味を持つのでしょうか?
Darwin Familyは、勾配計算を一切用いない「進化的モデル統合」フレームワークを提案しました。これは既存モデルの重み空間を再構成するだけで、それぞれが持つ潜在的な能力を統合・発現させる手法です。旗艦モデル「Darwin-27B-Opus」はGPQA Diamondベンチマークで86.9%の正解率を記録し、評価済み1,252モデル中第6位にランクイン——しかも、勾配ベースの訓練は一切行っていません。
arXivに新たに公開された論文「FORGE」は、モデルの重みを一切更新せずにエージェントの記憶を自己進化させる手法を提案しています。集団放送(Population Broadcast)メカニズムを通じて、エージェント同士が経験を共有・相互学習し、記憶を継続的に進化させます。このアプローチは従来のファインチューニングプロセスを回避し、エージェントの持続的学習に向けた軽量級の道筋を提供します。
新論文は、シンプルかつ統一的なスケーリング戦略により、大規模言語モデルが国際数学オリンピック(IMO)金メダルレベルの推論能力に安定して到達しうることを示している。派手な新アーキテクチャも複雑な学習テクニックもなく――ただスケーリングするだけだ。この事実が持つ意味は、論文そのもの以上に考察に値するだろう。
KAIST AIラボが発表した論文は、強化学習訓練が積極的に「コンフォートゾーン」から脱出するための戦略誘導型探索手法を提案し、訓練データ量を増やすことなく学習効率を向上させる。本論文はHugging Face Daily Papersで注目を集めている。
ハーバード大学とマサチューセッツ総合病院(MGH)の研究チームは、自律的なLLM主導のツリーサーチに基づく多病原体疾患予測手法を提案しました。LLMはもはや単なる対話ツールではなく、複雑な仮説空間において最適な予測モデルを探求する自律的な探索エージェントへと進化しています。本研究は、LLMが科学モデリングにおいて果たす新たな役割を示すものです。
新しい論文が、異なる学習状況におけるLLMベースのチューターエージェントのフィードバック品質を体系的に評価し、直感に反する結果を明らかにしました。すなわち、AI教師は生徒の正解を確認する際には良好なパフォーマンスを発揮しますが、生徒が誤答した——つまり、高品質なフィードバックが最も求められる瞬間——において、むしろ不正確または不十分な応答を最も出しやすいというのです。
NVIDIAが発表したMemLensベンチマークは、大型ビジョンランゲージモデルのマルチモーダル長期記憶能力を初めて体系的に評価するものです。これは、現在のマルチモーダルモデルの記憶における実際の水準と、「真に記憶する」状態までどれほど距離があるかを明らかにしています。
上海交通大が発表した MMSkills は、汎用視覚エージェント向けのマルチモーダル・スキル学習フレームワークを提案しています。既存のアプローチがモデルの暗記に依存するのに対し、MMSkills はエージェントにスキルのマルチモーダルな本質を真に理解させます――単に「何を見るか」だけでなく、「どう行動するか」も理解します。本論文は Hugging Face Daily Papers で 39 upvote を獲得しました。
OpenDeepThinkは、ペアワイズBradley-Terry比較に基づく母集団ベースのテスト時推論フレームワークを提案。8回のLLM呼び出し(約27分のウォールクロック時間)でGemini 3.1 ProのCodeforces Eloを405ポイント上昇。CF-73データセット—国際グランドマスターが注釈つけた73問のCodeforces問題—もオープンソース化。
SANA-WMは、26億(2.6B)パラメータのオープンソース世界モデルであり、1分間の動画生成をネイティブにサポートします。H100 GPU 64枚を用いて約213,000本の公開動画クリップで15日間学習されました。蒸留済みバリアントでは、RTX 5090 1枚+NVFP4量子化により、60秒・720p解像度の動画を34秒でデノイズ可能です。
SDAR(Self-Distilled Agentic Reinforcement Learning)は、LLMエージェントの強化学習(RL)訓練において、オンポリシー自己蒸留(On-Policy Self-Distillation)を「ゲート制御型補助目的関数(gated auxiliary objective)」として導入します。ALFWorld、WebShop、Search-QAの各ベンチマークで、GRPO比でそれぞれ+9.4%、+10.2%、+7.0%の性能向上を達成し、一方で単純なGRPO+OPSD組み合わせに起因する訓練不安定性を回避します。
「Self-Distilled Agentic Reinforcement Learning」は、人間のラベリングや外部報酬シグナルに依存するのではなく、エージェントが自己蒸留を通じて自身の経験から学習する新たな訓練パラダイムを提示します。これはAIエージェントの訓練方法の根本を変える可能性があります。
南京大学NJU-LINK Labが発表したSolvitaは、大規模言語モデル(LLM)の競技プログラミング能力を「エージェント進化(Agentic Evolution)」という新しいパラダイムで高めることを提案します。従来の教師あり微調整(SFT)とは異なり、Solvitaではエージェントが自己対戦と継続的な反復を通じて、自らより強力なプログラミング推論能力を進化させていきます。
SU-01は、30BパラメータのA3B MoE(Mixture of Experts)モデルであり、シンプルかつ統一された訓練レシピを用いて、IMO 2025、USAMO 2026、およびIPhO 2024/2025において金メダルレベルの性能を達成した。そのコアなフローは、「逆パープレキシティに基づくSFT課程」→「2段階の強化学習(検証可能な報酬によるRL → 証明品質重視のRL)」→「テスト時スケーリング」である。また、10万トークンを超える安定した推論トラジェクトリをサポートする。
Kronosは金融市場向けのFoundation Modelであり、金融データを一種の「言語」としてモデル化する。本プロジェクトはGitHubで24,946スターを獲得し、トークナイザーを用いて金融時系列データを離散化したトークン列に変換し、Transformerで予測を行うアプローチを提案している。この道は果たして通じるのだろうか?
最新のarXiv論文が指摘するように、現在のメンタルヘルスAIの安全性評価には根本的な欠陥がある。それらは孤立したレスポンスや最終結果のみを評価しており、臨床的に最も危険な被害は、相互作用のシーケンスにおける累積効果(段階的な依存の進行、繰り返し強化されるネガティブなパターン、ターン間の緩やかな悪化など)から生じるものである。本論文は「時系列安全性の非識別可能性」という理論的枠組みとSCOPE-MH評価基準を提案している。
NVIDIAが最新発表したAnyFlow論文では、「任意ステップ数」で動作する動画拡散モデルを提案しています。同じモデルで1ステップから数十ステップまで柔軟に切り替えることが可能であり、ステップ数ごとに個別に訓練する必要がありません。核となる手法「On-Policy Flow Map Distillation」は、訓練中にステップ数をランダムサンプリングし自己指導蒸留を行うことで、モデルがどのような推論ステップ数でも安定した生成品質を維持するよう学習させます。
arXivの最新論文「OpenDeepThink」は、集団競争に基づく推論フレームワークを提案します。モデルが単一の推論チェーンに固執するのではなく、複数の候補案をペアワイズで対戦させ、Bradley-Terryモデルで評価結果を集約します。これによりGemini 3.1 ProのCodeforces Eloスコアは405ポイントも上昇し、全プロセスは約27分で完了します。