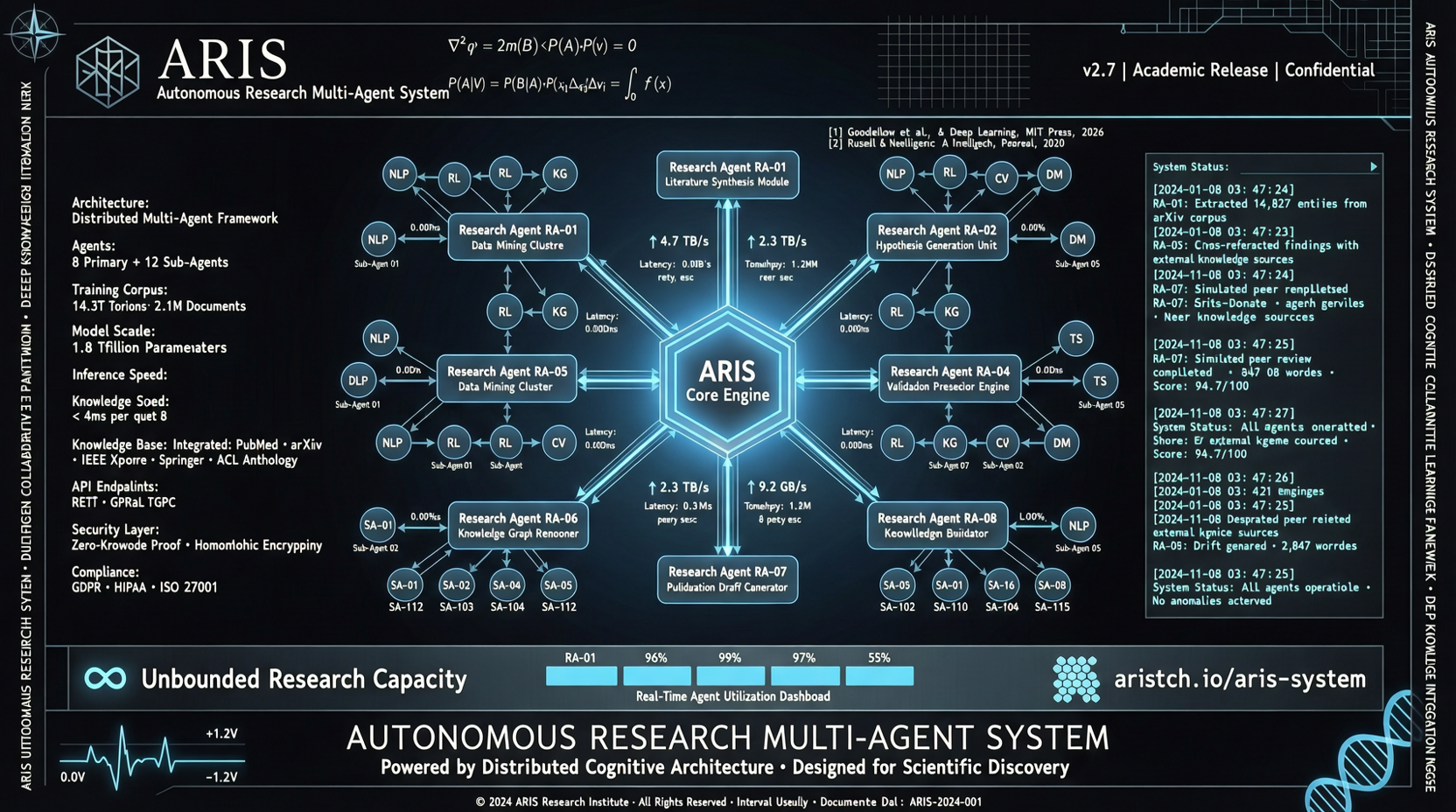
APWA: A Distributed Architecture for True Parallelization in Multi-Agent Systems
APWA proposes a distributed architecture designed for parallelizable agent workloads, addressing the inference, coordination, and computational scaling bottlenecks that multi-agent systems face as task scale and complexity increase.