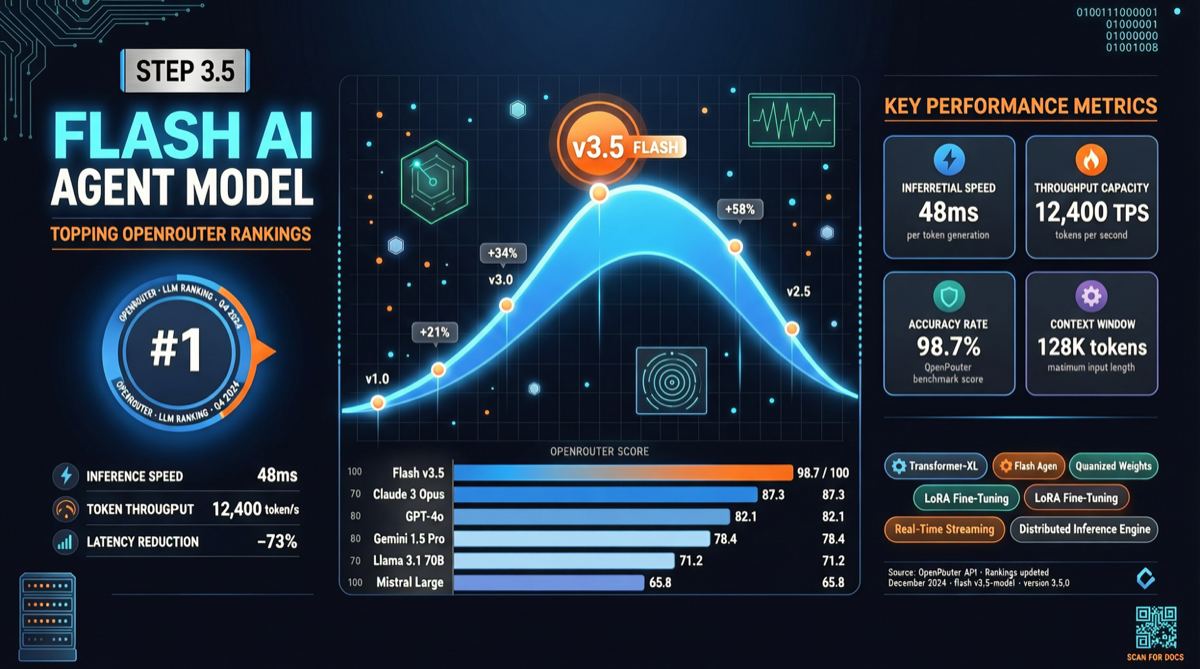
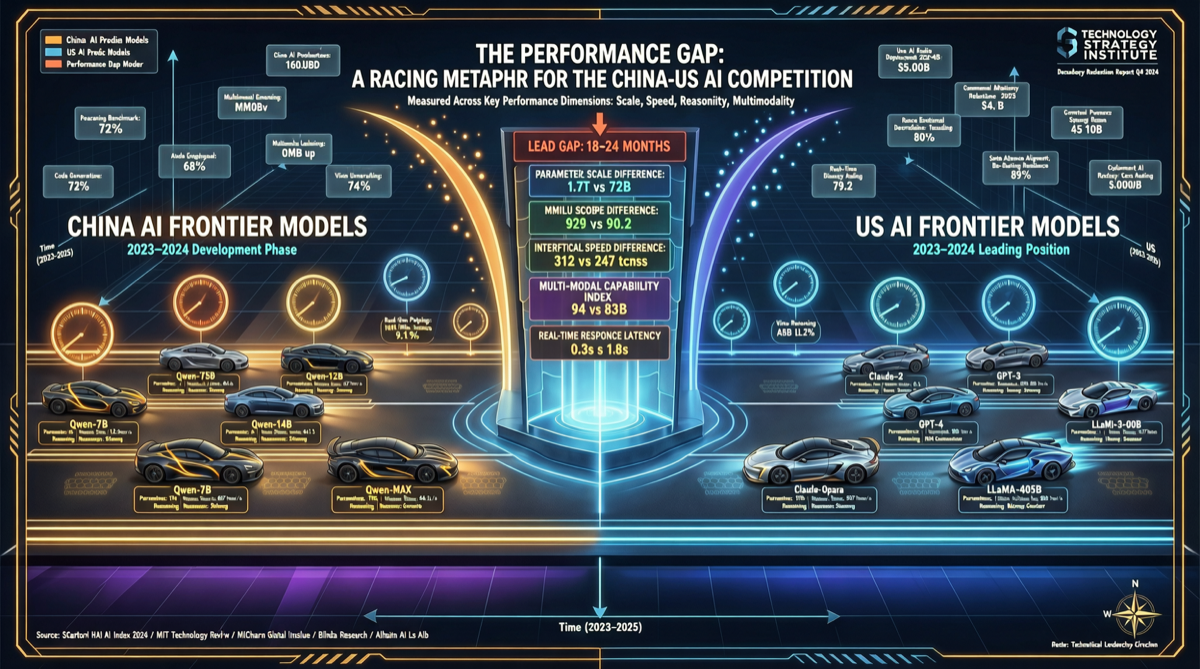
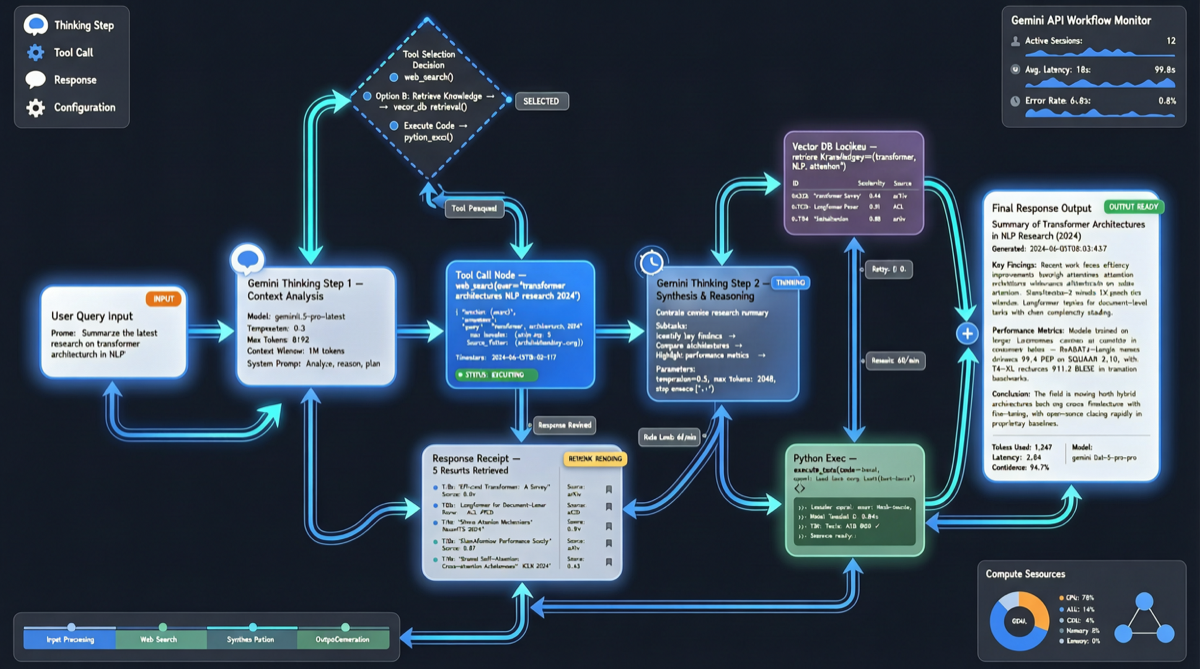
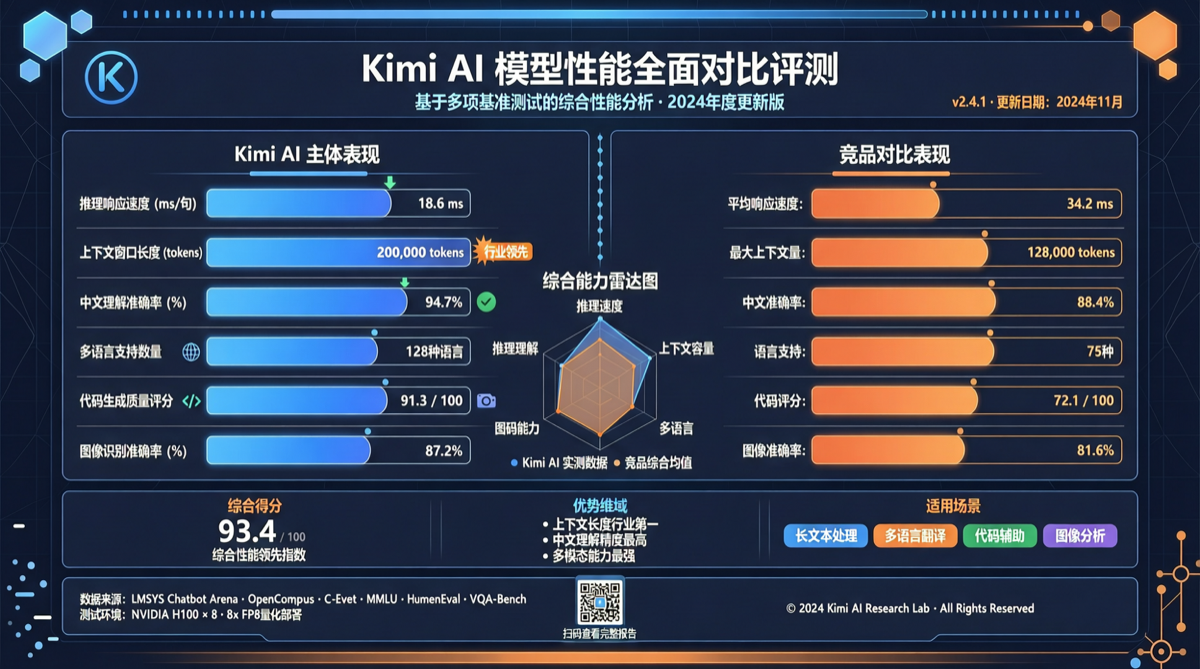
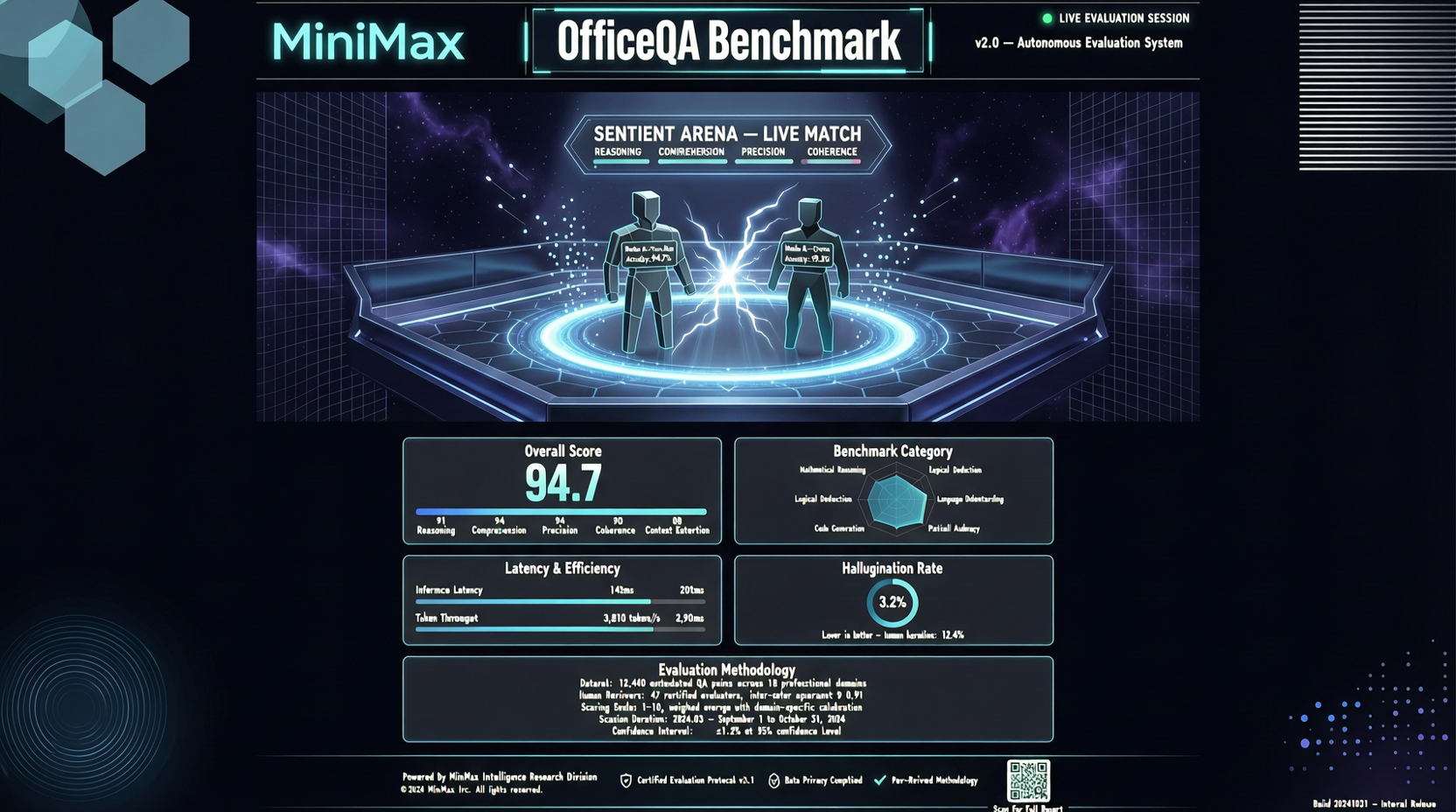
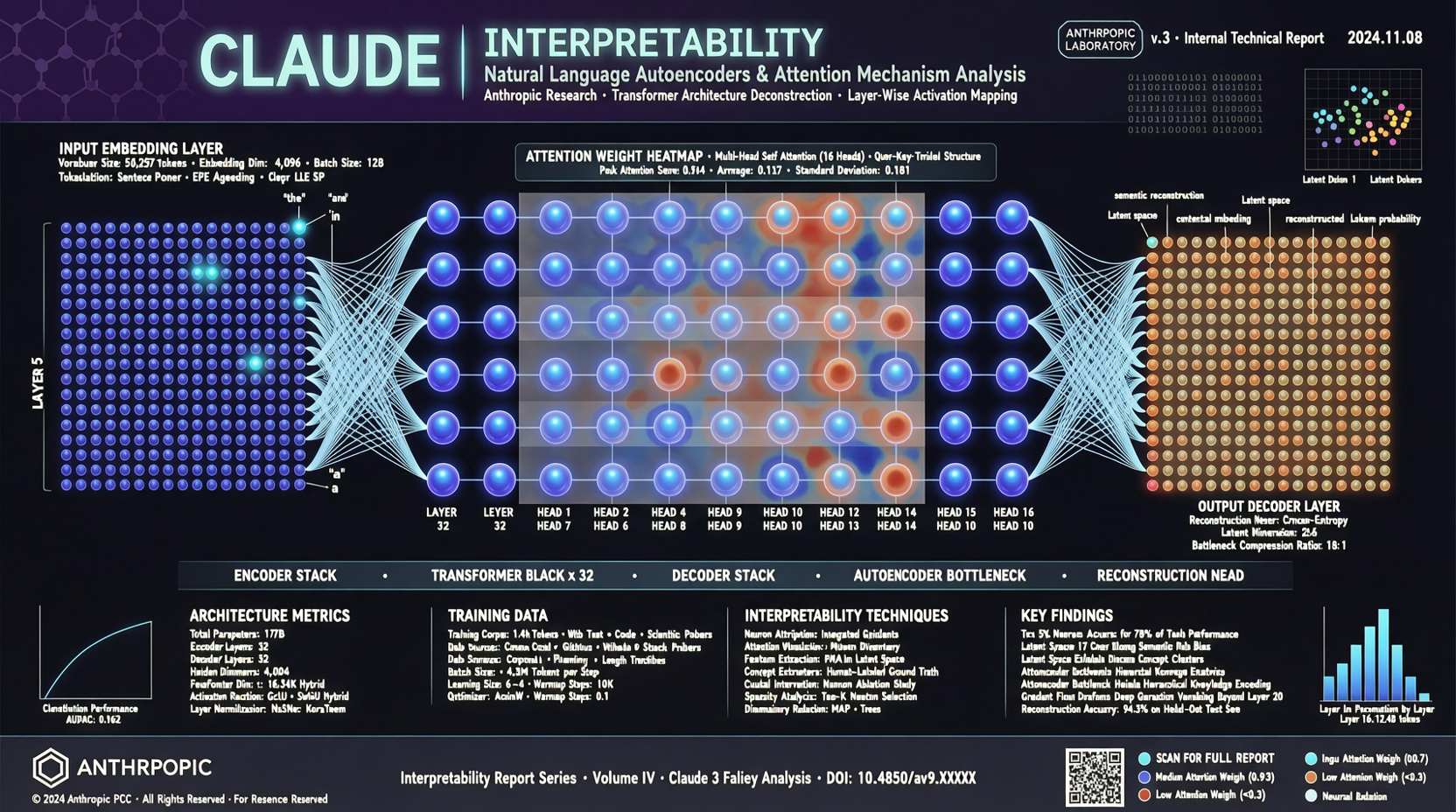
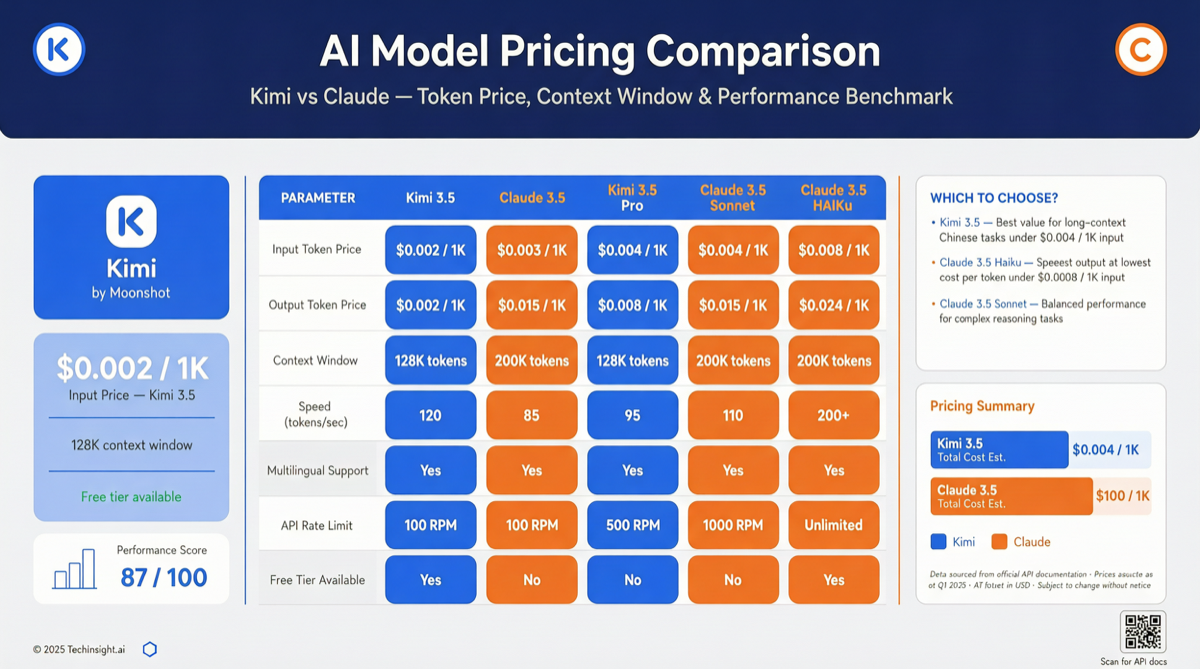
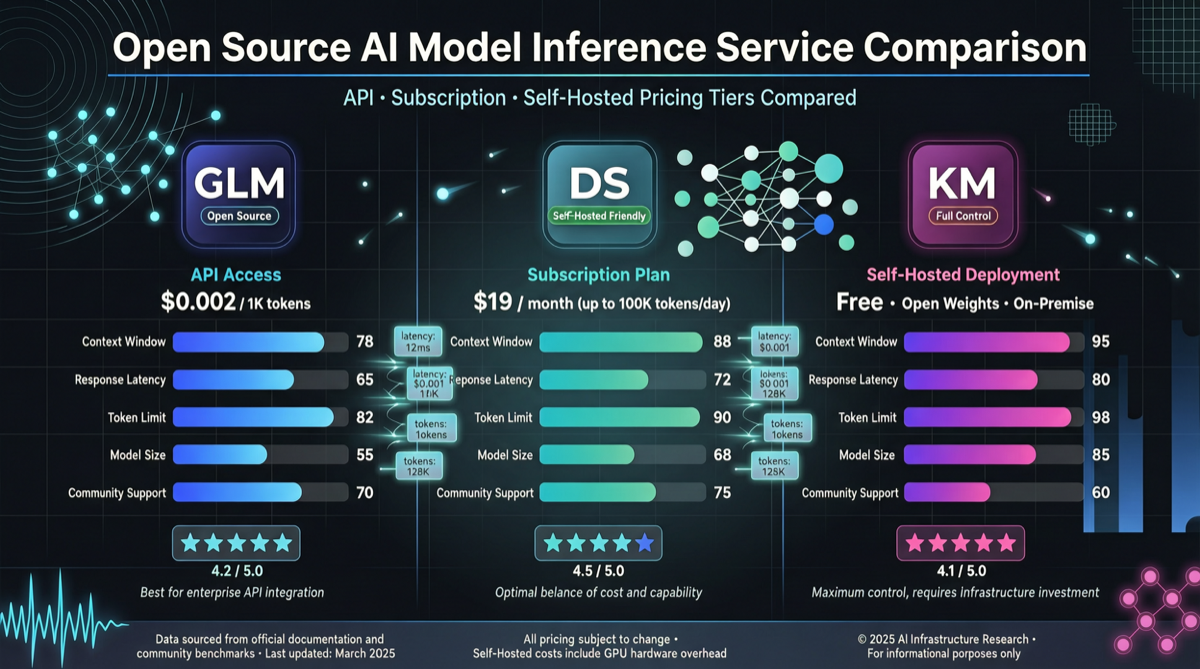
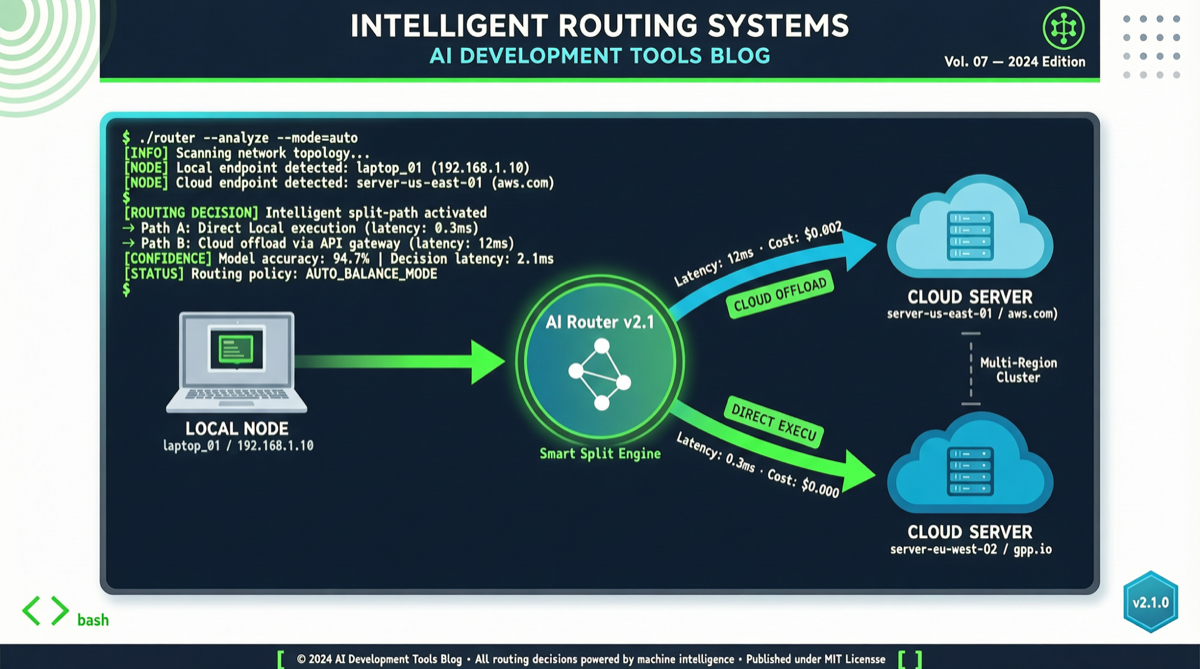
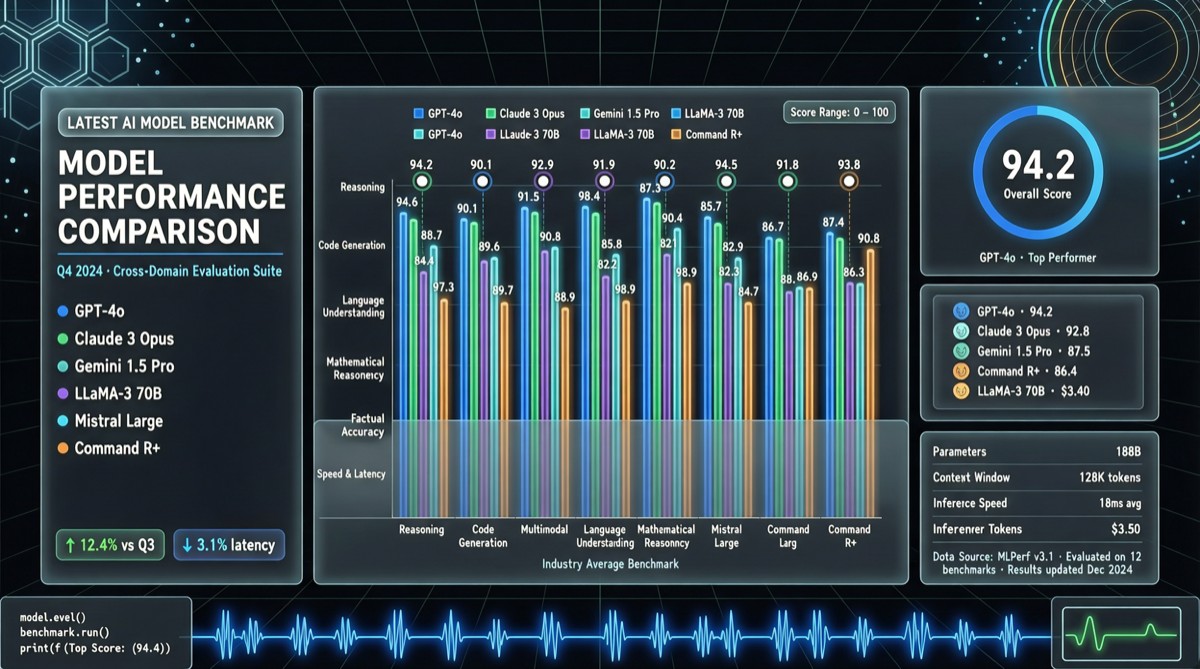
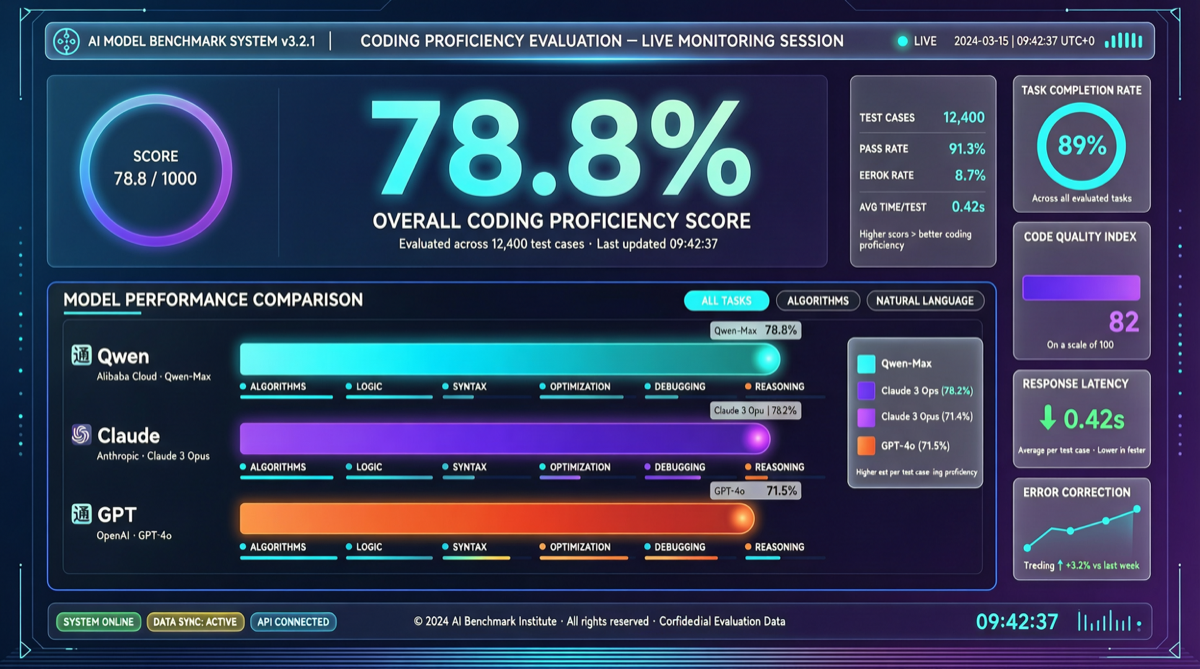
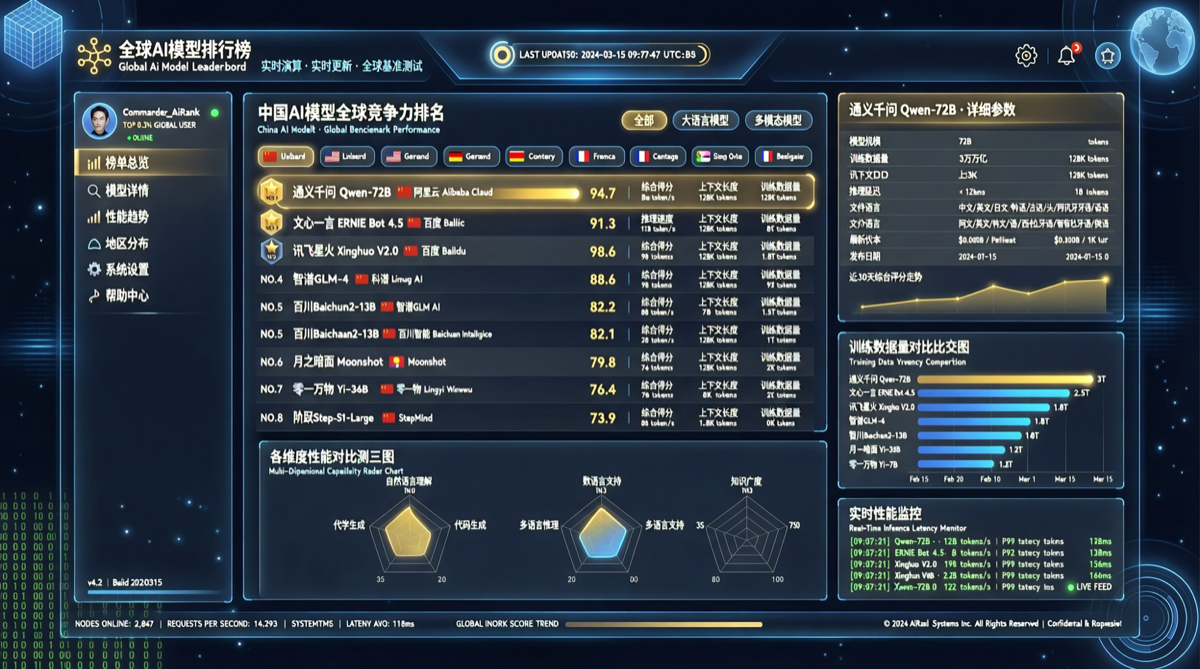
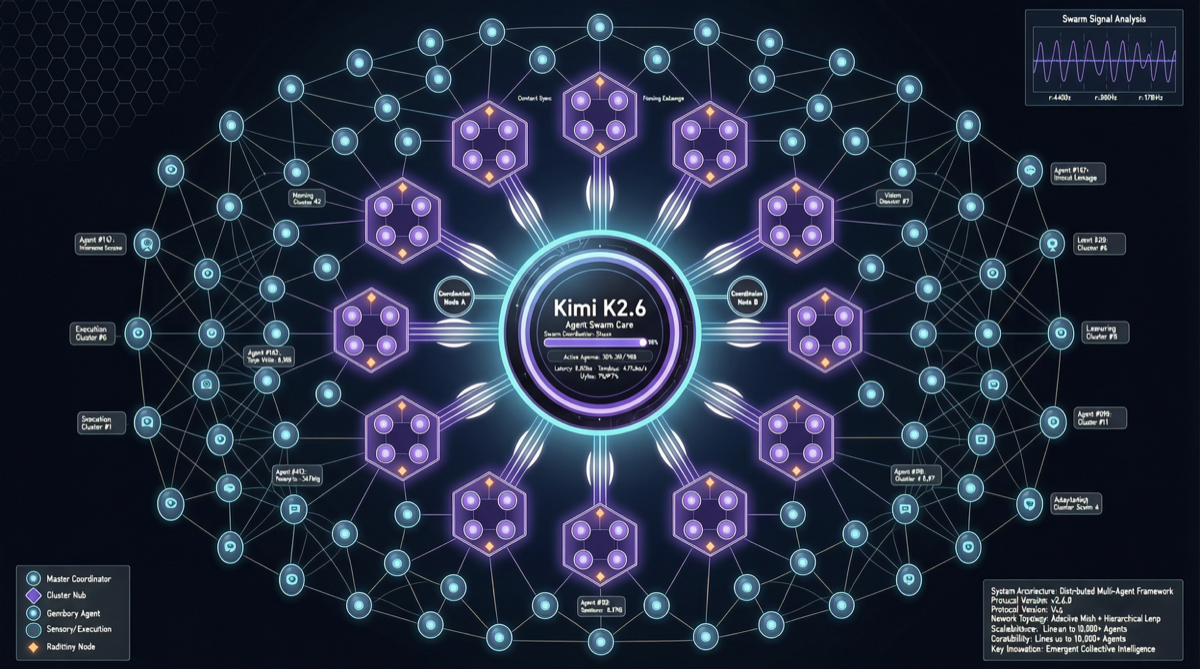
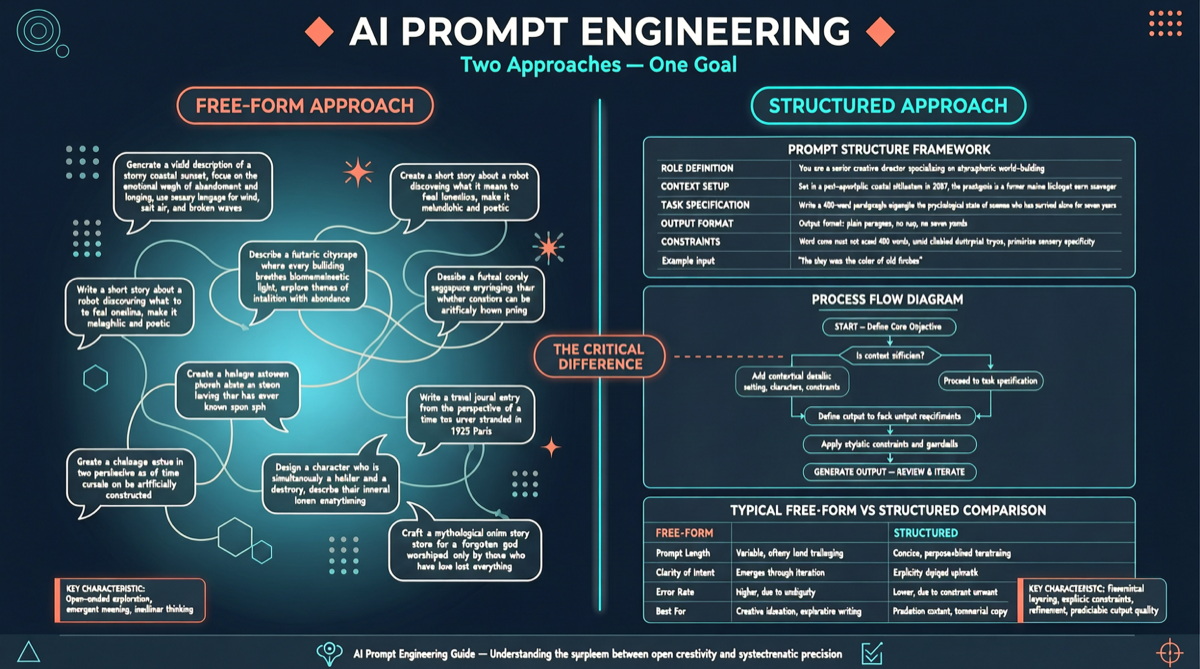
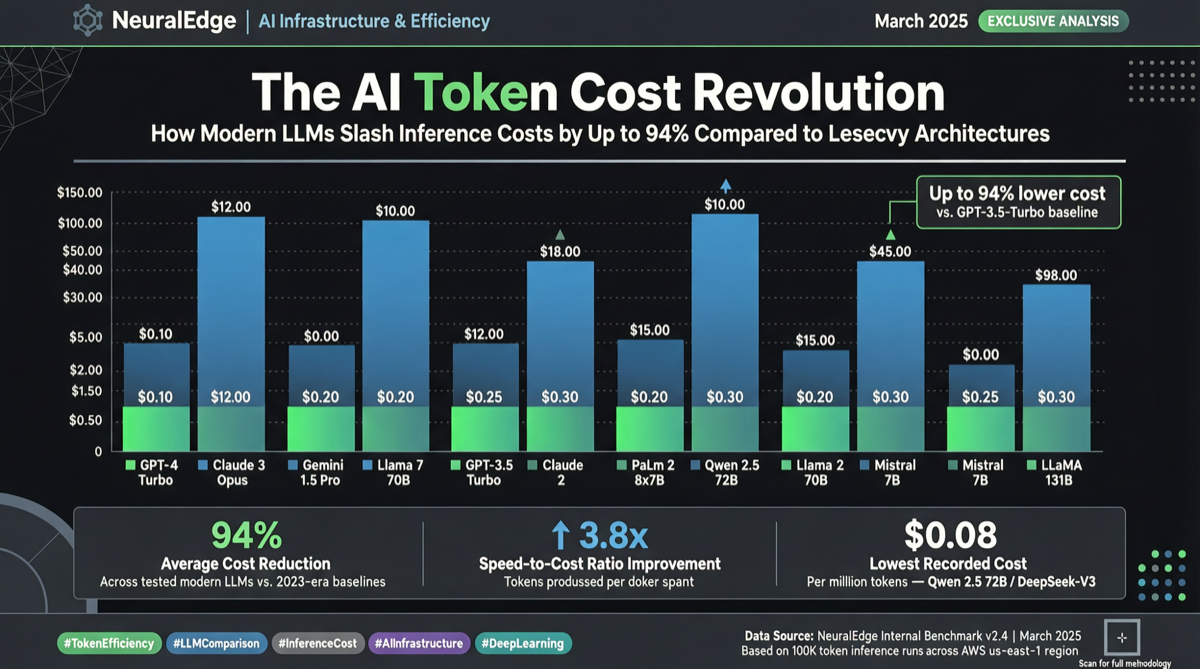
Chrome DevTools Officially Releases MCP Server: AI Coding Agents Can Finally "See" the Browser
The Chrome development team has officially released chrome-devtools-mcp, an MCP server that provides browser DevTools capabilities to AI coding agents. This means AI programming tools like Claude Code and Cursor can now directly control the browser—inspecting the DOM, debugging network requests, and analyzing performance. The project has already garnered over 40,000 stars on GitHub.