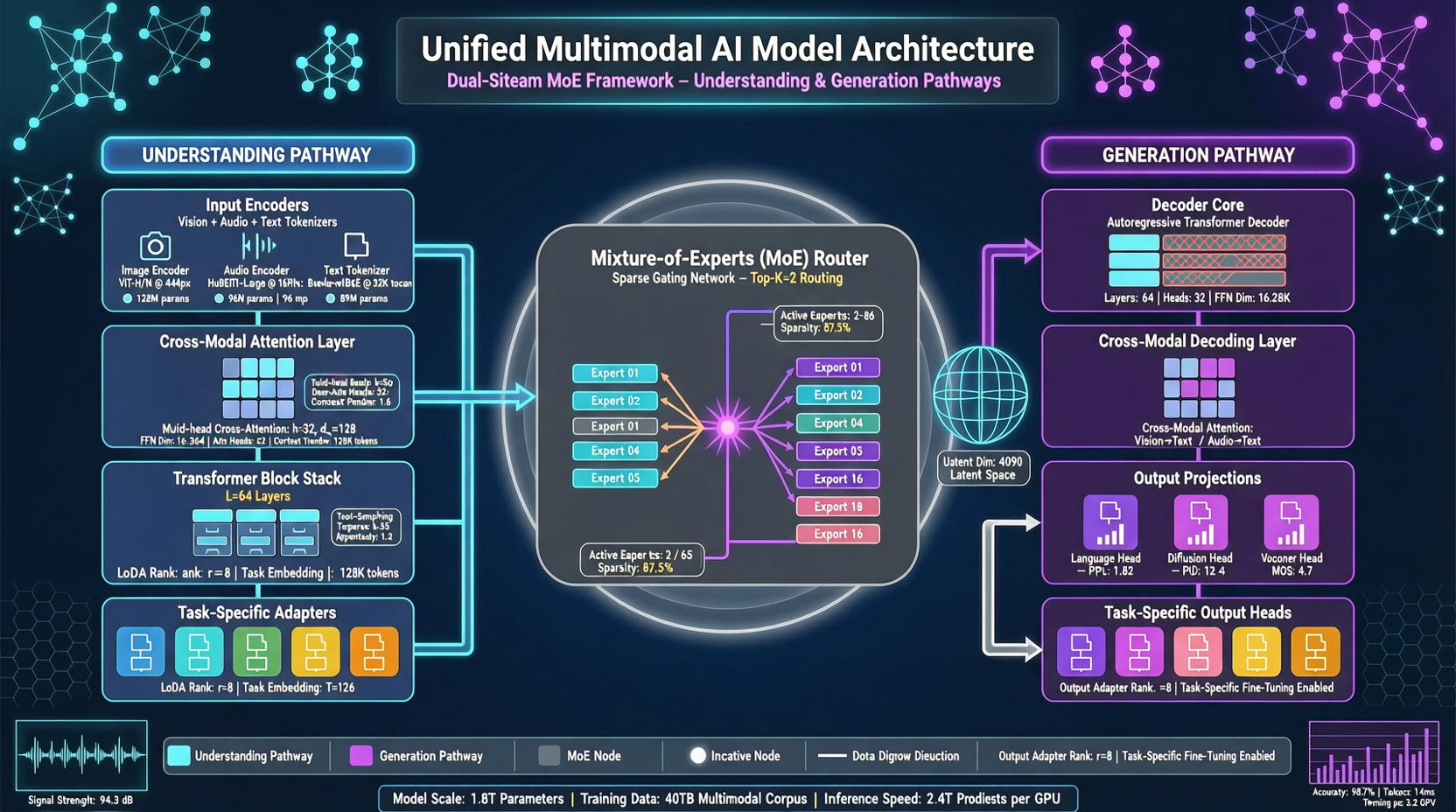
做统一多模态模型的人都知道一个尴尬的现实:理解和生成放在同一个模型里,两边互相拖后腿。理解任务要精准识别,生成任务要创造性输出——这两种能力在训练时本质上在抢同一条特征通道。
字节跳动的研究团队在 5 月 18 日提交了一篇论文,提出了一种不太一样的解法。不靠模型容量堆砌,也不走"文本-图像主导"的老路,而是把理解路径和生成路径拆开——共享上下文,分头干活。
项目叫 Lance。
共享大脑,分头干活
Lance 的架构设计有一个很直觉的比喻——就像一个人同时听和说。听和说共用同一个大脑(共享的上下文建模),但听觉处理和语言输出的神经通路是分开的(解耦的能力路径)。
具体来说,Lance 从零开始训练,采用双流混合专家(dual-stream MoE)架构,在共享的交错多模态序列上运行。所有模态的 token 一起进入模型学习联合上下文,但理解任务和生成任务各自走不同的专家路径。
这不是"理解完了再生成"的级联方案。理解和生成在训练时同时推进,只是通过 MoE 路由让不同的子网络专注不同的能力。
两个关键技术点
第一招是模态感知的旋转位置编码。不同模态的 token——图像 patch、视频帧、文本 token——混在一起时,标准的位置编码会让它们互相干扰。Lance 给不同模态的 token 加了位置编码标识,让模型能区分"这是视觉信号"还是"这是文本信号",减少异构 token 之间的干扰。
第二招是分阶段的多任务训练。不是一上来就把理解、生成、编辑全扔进去,而是分阶段推进,每个阶段有明确的能力目标,配合自适应数据调度。
效果怎么样
论文声称 Lance 在图像和视频生成方面大幅超越现有开源统一模型,同时保持了很强的多模态理解能力。
Hugging Face Daily Papers 上 69 个 upvote。不算爆炸式增长,但在这个方向上算有分量的工作。
值得跟进的观察点
Lance 的 homepage 上应该能看到具体生成样例和对比结果。如果它在视频生成质量上确实明显领先现有开源方案,那字节在多模态统一建模这条路线上就走出了自己的特色。
不过论文才发布不到一周,社区的实际验证还很少。MoE 架构在训练阶段的稳定性、推理时的路由效率,这些只有在真实部署时才能看出来。
为什么这个方向值得看
统一多模态模型不是新概念。但大多数方案要么偏理解(MLLM),要么偏生成(diffusion/flow model),或者用暴力堆参数的方式兼顾两边。Lance 代表了一种更务实的路线——在有限模型容量下,通过架构设计让理解和生成和平共处。
如果这条路走通了,未来可能不需要分别部署一个理解模型和一个生成模型。一个模型,两种能力,成本直接减半。
主要来源:
- Lance 论文(ByteDance Research,2026 年 5 月 18 日)
- Hugging Face Daily Papers(69 upvotes)
- 项目主页:https://lance-project.github.io/