統一マルチモーダルモデルを作っている人なら皆知っている現実:理解と生成を同じモデルに入れようとすると、両方がお互いを引き下げる。理解タスクは正確な識別を求め、生成タスクは創造的な出力を求める——訓練中、両者は本質的に同じ特徴チャネルを奪い合っている。
ByteDanceの研究チームが5月18日に提出した論文は、少し違うアプローチを提案している。モデル容量の積み上げに頼らず、「テキスト-画像優位」の古い道も歩まない。代わりに、理解パスと生成パスを分離する——コンテキストを共有し、それぞれが仕事をする。
プロジェクト名はLance。
脳を共有し、出力を分離
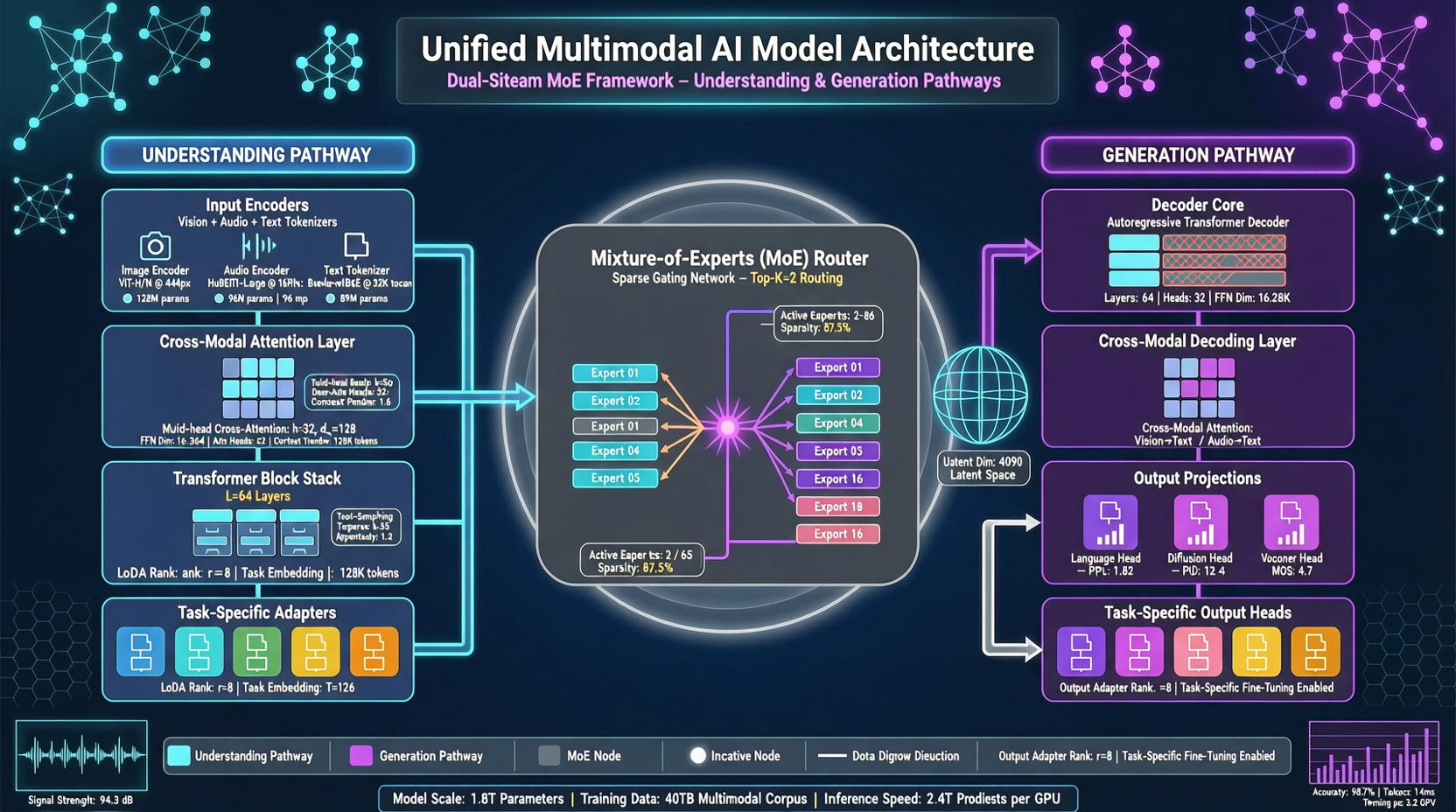
Lanceのアーキテクチャデザインには直感的な比喩がある——人間が同時に聞いて話すようなもの。聞くことと話すことは同じ脳を使い(共有コンテキストモデリング)、聴覚処理と言語出力の神経経路は分かれている(デカップリングされた能力パス)。
具体的には、Lanceはゼロから訓練され、共有された交差マルチモーダルシーケンス上で動作する双流MoE( mixture-of-experts)アーキテクチャを採用。すべてのモダリティのトークンがモデルに入って joint context を学習するが、理解タスクと生成タスクはそれぞれ異なるエキスパートパスを通る。
「理解してから生成する」カスケード方式ではない。理解と生成は訓練中に同時に推進され、MoEルーティングによって異なるサブネットワークが異なる能力に集中する。
2つの重要設計
1つ目はモダリティ対応回転位置エンコーディング(modality-aware RoPE)。異なるモダリティのトークン——画像パッチ、ビデオフレーム、テキストトークン——が混ざるとき、標準の位置エンコーディングは相互干渉を引き起こす。Lanceは異なるモダリティのトークンに位置エンコーディング識別子を付け、モデルが「これは視覚信号」か「これはテキスト信号」かを区別できるようにし、異種トークン間の干渉を減らす。
2つ目はステージ別マルチタスク訓練。理解、生成、編集を一気に放り込むのではなく、段階的に推進し、各ステージに明確な能力目標を設定し、適応的データスケジューリングと組み合わせる。まず基礎を固め、 затем強化。
効果はどうか
論文によると、Lanceは画像とビデオ生成において既存のオープンソース統一モデルを大幅に上回り、同時に強力なマルチモーダル理解能力を維持しているという。
Hugging Face Daily Papersで69upvote。爆発的成長ではないが、この方向では重量級の作業と言える。
注目すべきポイント
Lanceのhomepageで具体的な生成サンプルと比較結果が見られるはず。ビデオ生成品質が既存のオープンソースアプローチを明らかにリードしているなら、ByteDanceは統一マルチモーダルモデリングの道で独自の特色を打ち出したことになる。
ただし論文発表から1週間未満で、コミュニティの実際の検証はまだ少ない。MoEアーキテクチャの訓練段階の安定性、推論時のルーティング効率——これらは実際のデプロイ時に初めてわかる。
主要ソース:
- Lance論文(ByteDance Research、2026年5月18日)
- Hugging Face Daily Papers(69 upvotes)
- プロジェクトページ:https://lance-project.github.io/