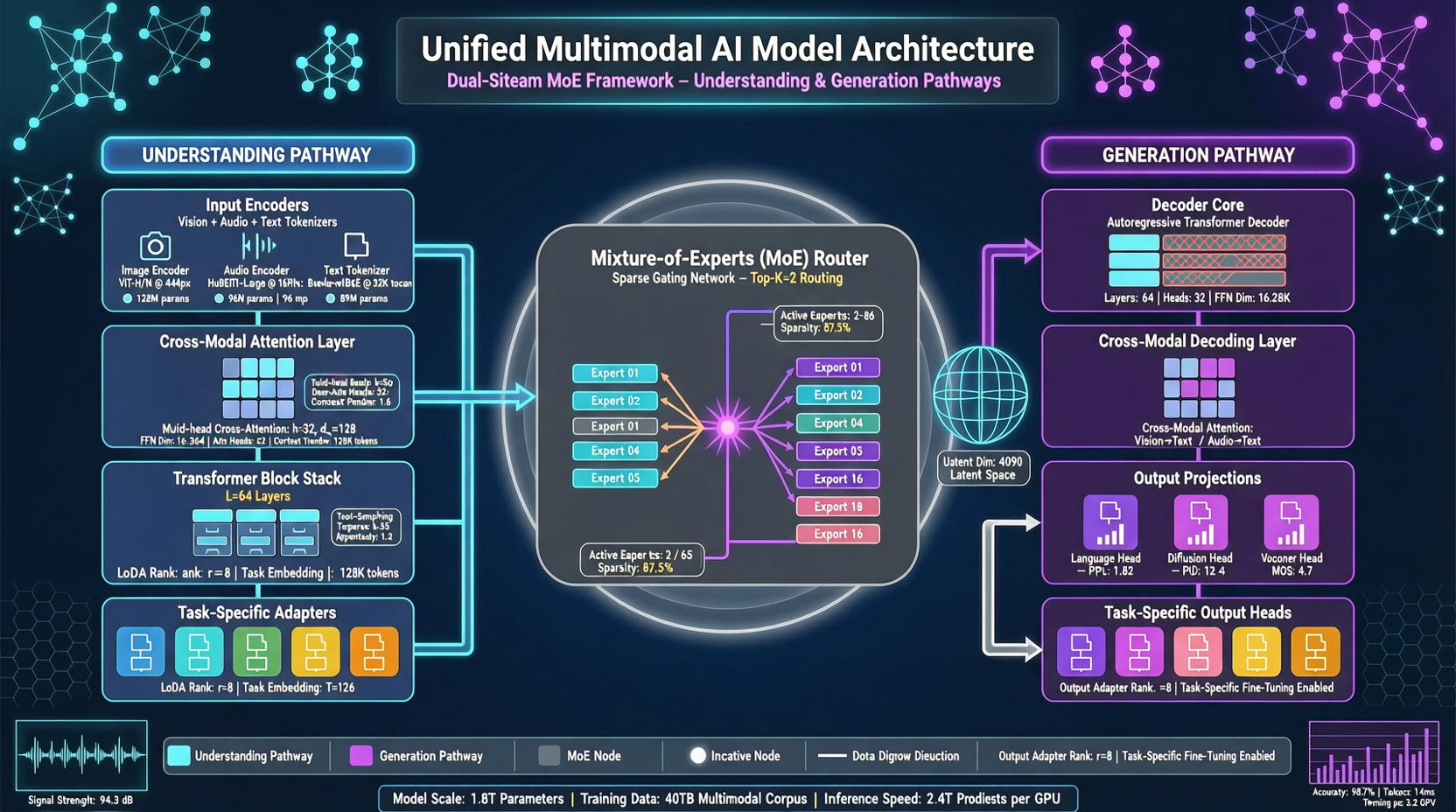
Все, кто работает над едиными мультимодальными моделями, знают неудобную реальность: понимание и генерация, помещённые в одну модель, тянут друг друга вниз. Задачи понимания требуют точной идентификации, задачи генерации — креативного вывода. Во время обучения оба направления по сути конкурируют за один и тот же канал признаков.
Исследовательская команда ByteDance 18 мая опубликовала статью с другим подходом. Никакого накопления параметров, никакого наследования пути «текст-изображение доминирует». Вместо этого — разделение путей понимания и генерации: общий контекст, раздельная работа.
Проект называется Lance.
Общий мозг, раздельный вывод
Архитектура Lance имеет интуитивную аналогию: как человек, который одновременно слушает и говорит. Слух и речь используют один мозг (совместное моделирование контекста), но нейронные пути обработки звука и языкового вывода разделены (разделённые пути способностей).
Конкретнее, Lance обучается с нуля на архитектуре двухпотоковой смеси экспертов (dual-stream MoE), работающей на общих чередующихся мультимодальных последовательностях. Токены всех модальностей поступают в модель вместе для совместного обучения контексту, но задачи понимания и генерации проходят по разным экспертным путям.
Это не каскад «сначала понять, потом сгенерировать». Понимание и генерация продвигаются одновременно во время обучения, а маршрутизация MoE направляет разные подсети на разные способности.
Два ключевых решения
Первое — позиционное кодирование с учётом модальности (modality-aware RoPE). Когда токены разных модальностей — патчи изображений, кадры видео, текстовые токены — смешиваются, стандартное позиционное кодирование вызывает взаимные помехи. Lance добавляет идентификаторы позиционного кодирования для разных модальностей, позволяя модели различать «это визуальный сигнал» и «это текстовый сигнал», уменьшая помехи между разнородными токенами.
Второе — многозадачное обучение по этапам. Не бросать сразу понимание, генерацию и редактирование в одну кучу, а продвигаться поэтапно, каждый этап с чёткой целью,配合 адаптивным планированием данных. Сначала фундамент, затем усиление.
Как результаты
По данным статьи, Lance значительно превосходит существующие open-source единые модели в генерации изображений и видео, сохраняя при этом сильные способности мультимодального понимания.
69 upvotes на Hugging Face Daily Papers. Не взрывной рост, но весомая работа в этом направлении.
На что обратить внимание
На домашней странице Lance должны быть конкретные примеры генерации и сравнения. Если качество генерации видео действительно значительно превосходит существующие open-source решения, ByteDance проложила свой собственный путь в едином мультимодальном моделировании.
Но статье меньше недели. Реальная валидация сообществом ещё впереди. Стабильность архитектуры MoE на этапе обучения, эффективность маршрутизации при инференсе — всё это проявляется только при реальном развёртывании.
Основные источники:
- Статья Lance (ByteDance Research, 18 мая 2026)
- Hugging Face Daily Papers (69 upvotes)
- Страница проекта: https://lance-project.github.io/