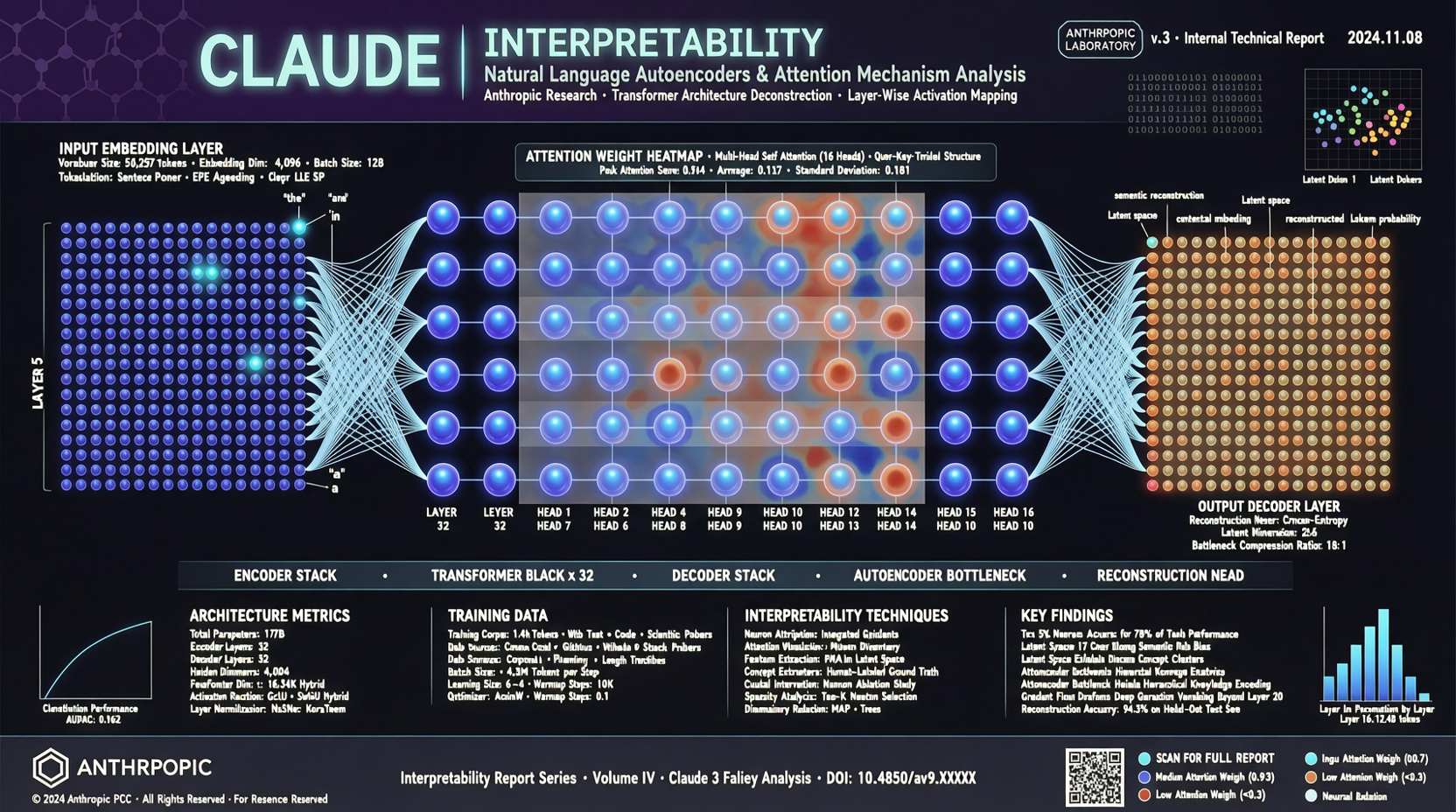
Claude 说话用文字,思考用数字。Anthropic 现在想让这两者对上号。
5 月 7 日,Anthropic 的可解释性团队发了一篇有点"科幻"味道的论文:他们训练了一个自编码器,能把 Claude 内部的激活状态——那些高维向量、权重矩阵里的数值——直接翻译成人类可读的自然语言。
不是总结,不是近似,是直接翻译。
为什么要干这件事
大模型最大的黑箱问题不是"它说了什么",而是"它为什么这么说"。你问 Claude 一个问题,它给你一段回答。但在这段回答背后,模型内部发生了成千上万次矩阵运算。你只知道结果,不知道过程。
Anthropic 的做法很直接:给 Claude 装一个"翻译层"。这个层读模型内部的激活信号,输出对应的自然语言描述。
比如模型内部某个激活模式可能对应"正在考虑这个答案的安全性",另一个可能对应"检测到用户可能有恶意意图"。自编码器学到的就是这些激活模式和文本描述之间的映射关系。
技术细节不绕弯子
核心是一个 sparse autoencoder(稀疏自编码器),训练目标是用自然语言重构模型的内部表示。
关键设计:
- 词典规模在百万级别,每个维度对应一个人类可理解的概念
- 稀疏性约束确保每个激活只触发少量概念,避免概念混在一起
- 训练数据覆盖了 Claude 的大量内部层,不是只翻译最后一层
论文声称学到了大量有意义的概念:从"讨论编程"到"检测偏见",从"数学推理"到"情感分析"。
这东西靠谱吗
先说好的:如果能稳定地把内部激活翻译成文本,那对 model debugging 和 safety research 是巨大的工具。你不需要猜模型在想什么,直接读就行。
但也有保留意见:
第一,"翻译成文本"这个过程本身就有信息损失。高维激活压缩到自然语言,不可能 100% 保真。就像用中文描述一幅画——再好的描述也不是画本身。
第二,这些"概念"是人类标注的还是模型自己发现的?论文说是自动发现的,但自动发现的概念是否真的对应人类理解的语义,还需要更多验证。
第三,这套系统目前只对 Claude 自己有效。换一个模型架构,大概率要重新训练。通用性存疑。
实际意义
对普通用户来说,这篇论文没有直接的产品价值。你不会在 Claude 的下一个版本里看到一个"显示我的思考过程"的按钮。
但对 AI 安全研究社区来说,这可能是今年最重要的工具之一。如果内部激活可以被可靠地解释,那很多 alignment 问题——比如 model deception、goal misgeneralization——就有了新的研究入口。
Anthropic 在可解释性这个方向上投入很重。这篇论文和他们之前发布的 feature visualization 工作是一脉相承的。
翻译 Claude 的"脑电波",听上去很赛博朋克。但赛博朋克的事,往往最先在实验室里发生。
主要来源:Anthropic Research Blog (May 7, 2026), "Natural Language Autoencoders: Turning Claude's thoughts into text"