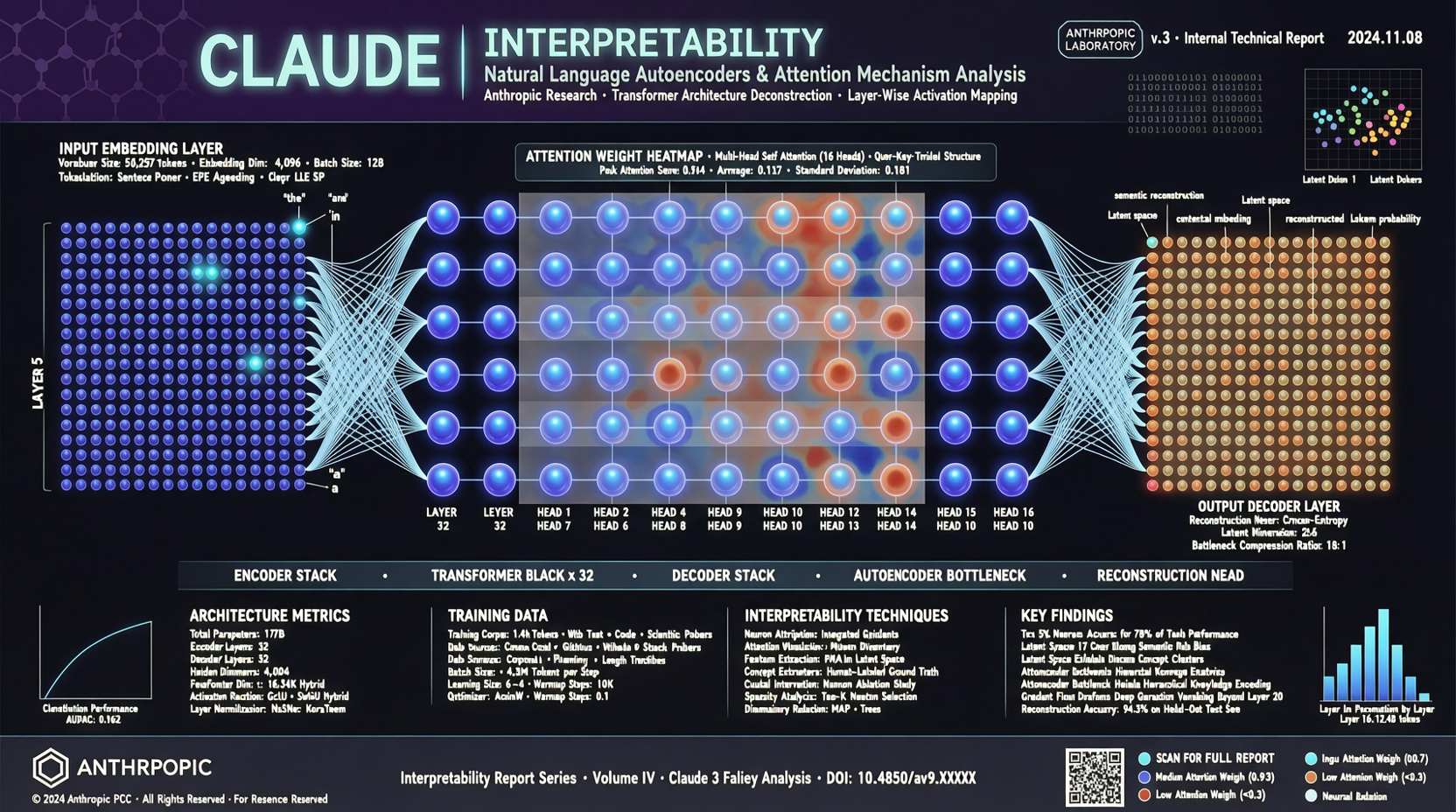
Claude говорит словами, но думает числами. Anthropic хочет это исправить.
7 мая команда интерпретируемости Anthropic опубликовала статью с лёгким «научно-фантастическим» оттенком: они обучили автоэнкодер, способный напрямую переводить внутренние состояния активации Claude — те самые высокоразмерные векторы, числовые значения в матрицах весов — в понятный человеку естественный язык.
Не резюме. Не аппроксимация. Прямой перевод.
Зачем это нужно
Самая большая проблема чёрного ящика LLM — не «что он сказал», а «почему он это сказал». Вы задаёте Claude вопрос, он даёт ответ. Но за этим ответом модель выполнила тысячи матричных операций.
Подход Anthropic прямой: прикрепить «слой перевода» к Claude. Этот слой читает внутренние сигналы активации модели и выводит соответствующие описания на естественном языке.
Технические детали без обёртки
Основа — sparse autoencoder (разреженный автоэнкодер), обученный реконструировать внутренние представления модели с помощью естественного языка.
Ключевые моменты:
- Размер словаря — миллионы, каждое измерение соответствует понятной человеку концепции
- Ограничения разреженности гарантируют, что каждая активация запускает лишь несколько концепций
- Данные обучения охватывают множество внутренних слоёв Claude
Надёжно ли это?
Хорошая новость: если внутренние активации можно надёжно перевести в текст, это огромный инструмент для отладки моделей и safety-исследований.
Но есть оговорки:
Во-первых, процесс «перевода в текст» сам по себе несёт потерю информации. Сжатие высокоразмерных активаций в естественный язык не может быть на 100% точным.
Во-вторых, эти «концепции» обнаружены автоматически самой моделью. Соответствуют ли они человеческой семантике — требует дополнительной проверки.
В-третьих, система пока работает только для Claude. Другая архитектура модели, скорее всего, потребует переобучения.
Практическое значение
Для обычных пользователей у этой статьи нет прямой продуктовой ценности. Кнопки «показать мой мыслительный процесс» в следующем релизе Claude не появится.
Но для сообщества исследователей ИИ-безопасности это может быть один из важнейших инструментов года.
Перевод «мозговых волн» Claude звучит очень киберпанково. Но киберпанковые вещи обычно сначала происходят в лабораториях.
Основной источник: Anthropic Research Blog (7 мая 2026), "Natural Language Autoencoders: Turning Claude's thoughts into text"