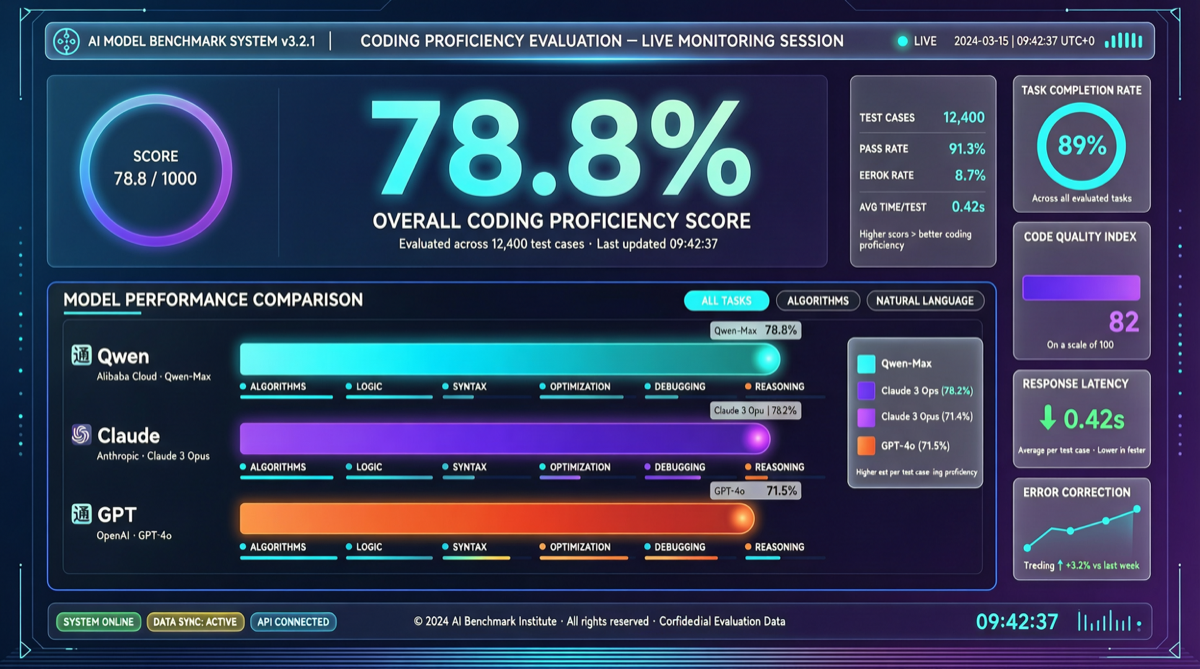
核心判断
Qwen3.6-Max-Preview 在 SWE-bench 上拿到 78.8%,配合 1M token 上下文窗口——这个数字意味着什么?意味着 Claude Code、Cursor、GitHub Copilot 这些编码工具的"底层模型护城河"正在快速蒸发。
社区已经有人在 X 上直言:"Next differentiation won't be raw capability — it'll be reliability, how gracefully it fails, and how well it handles edge cases under load."(下一个差异化不再是原始能力——而是可靠性、失败时的优雅程度,以及负载下处理边缘场景的能力。)
这不是 Qwen 的独角戏。同一时间段,GPT-5.5 在 SWE-bench Pro 上是 58.6%,Claude Opus 4.7 是 64.3%。Qwen3.6-Max-Preview 以显著优势领先。
数据对比
| 模型 | SWE-bench | SWE-bench Pro | 上下文窗口 | 定价参考 |
|---|---|---|---|---|
| Qwen3.6-Max-Preview | 78.8% | — | 1M token | 国内云厂商 |
| Claude Opus 4.7 | — | 64.3% | 200K | $15/$75 per 1M |
| GPT-5.5 | — | 58.6% | 1M | $180/M (Pro) |
| Gemini 3.1 Pro | — | — | 1M | $12/M |
| Qwen3.6-Plus | 78.8% | — | 1M | 阿里云 |
数据来源:X/Twitter 社区汇总(@ivanfioravanti 等),各模型官方公告
注意:Qwen3.6-Max-Preview 和 Qwen3.6-Plus 在 SWE-bench 上都报告了 78.8%,这可能是同一基准的不同命名,也可能意味着 3.6 系列的整体编码能力达到了统一的高水位线。
三个关键信号
1. 编码模型进入"超饱和"区间
当 SWE-bench 分数逼近 80% 时,边际改进的价值急剧下降。从 50% 到 70% 是质的飞跃——模型终于能解决真实仓库的 bug。但从 70% 到 80%,更多是长尾 case 的覆盖,对开发者日常体验的改善远不如从 30% 到 50% 那么明显。
换句话说,编码模型的能力竞赛正在进入收益递减区。
2. 1M 上下文成为标配
Qwen3.6-Max-Preview 的 1M 上下文窗口不再是"实验性功能",而是生产级特性。这意味着:
- 整个大型代码库可以一次性放入上下文
- Agent 可以同时查看依赖关系、测试文件、文档和 PR 历史
- 传统"文件级"编码辅助将全面升级为"仓库级"编码辅助
3. 国产模型进入第一梯队
Qwen3.6 系列(包括 27B 本地版和 Max-Preview 云端版)的组合拳策略非常清晰:
- 27B:消费级硬件可跑,本地编码辅助,18GB 内存即可部署
- Plus:API 性价比路线,78.8% SWE-bench
- Max-Preview:旗舰能力展示,更强的工具调用和 Agent 工作流可靠性
这种"全栈覆盖"策略让 Qwen 在不同预算和场景下都有竞争力,而不只是在某个细分领域领先。
格局判断
编码工具的未来差异化方向
当底层模型能力趋同时,编码工具的竞争将转移到:
| 维度 | 说明 |
|---|---|
| 可靠性 | 模型失败时的行为——是静默输出错误代码,还是明确告知不确定性? |
| 边缘场景 | 处理冷门语言、遗留代码库、非标准构建系统的能力 |
| 集成深度 | 与 IDE、CI/CD、代码审查流程的无缝衔接 |
| 多 Agent 协作 | 不是单个模型多强,而是多个 Agent 如何分工协作完成复杂任务 |
| 成本控制 | 1M 上下文不便宜,如何在质量和成本之间做动态平衡 |
对开发者的行动建议
- 不要锁死单一编码工具——Qwen3.6-Max-Preview 的出现意味着你可以在不同工具间切换而不会损失太多编码能力
- 关注 1M 上下文的实际用法——把整个仓库放入上下文后的 prompt 策略、token 预算管理是新技能
- 评估 Agent 工作流可靠性——在负载下的表现比单次 benchmark 分数更重要
- 考虑混合方案——本地 27B 做日常辅助 + 云端 Max 处理复杂任务,成本效率最优
值得关注
Qwen3.6 系列的能力提升不是孤立的。同一时期:
- Qwen Image 2.0 Pro 在 Text-to-Image Arena 排名 #9
- 社区传闻 Qwen3.6-122B-A10B(MoE 架构)即将发布
- 阿里巴巴持续在 Agent 基础设施层面投入(Qwen Code Terminal Agent 已发布)
2026 年的 AI 竞争已经从"谁能做出最好的模型"转向"谁能把模型最好地集成到工作流中"。Qwen3.6-Max-Preview 的 78.8% 是一个重要里程碑——它宣告了编码模型基础能力的"军备竞赛"正在收尾,下一阶段的竞争已经开始。