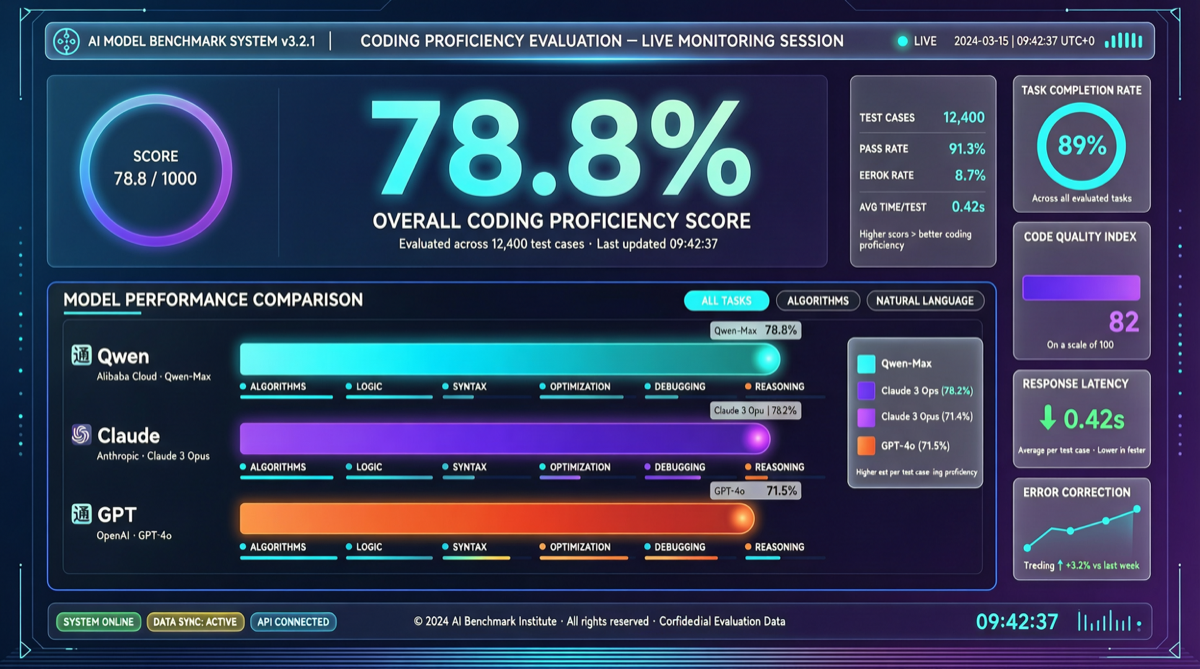
Ключевой вывод
Qwen3.6-Max-Preview набрал 78.8% на SWE-bench с контекстным окном 1M токенов. Это означает, что «рвы базовых моделей» для инструментов кодинга, таких как Claude Code, Cursor и GitHub Copilot, быстро исчезают.
Кто-то в X выразился прямо: «Следующая дифференциация — не сырые способности, а надёжность, то, как элегантно модель справляется с ошибками, и как хорошо обрабатывает крайние случаи под нагрузкой.»
Это не соло-выступление Qwen. В тот же период GPT-5.5 набрал 58.6% на SWE-bench Pro, Claude Opus 4.7 — 64.3%. Qwen3.6-Max-Preview лидирует со значительным отрывом.
Сравнение данных
| Модель | SWE-bench | SWE-bench Pro | Контекстное окно | Цена |
|---|---|---|---|---|
| Qwen3.6-Max-Preview | 78.8% | — | 1M токенов | Китайские облачные провайдеры |
| Claude Opus 4.7 | — | 64.3% | 200K | $15/$75 за 1M |
| GPT-5.5 | — | 58.6% | 1M | $180/мес (Pro) |
| Gemini 3.1 Pro | — | — | 1M | $12/мес |
| Qwen3.6-Plus | 78.8% | — | 1M | Alibaba Cloud |
Три ключевых сигнала
1. Модели кодинга входят в зону «перенасыщения»
Когда результаты SWE-bench приближаются к 80%, ценность маржинального улучшения резко падает. Скачок с 50% до 70% — это качественный прорыв. Но с 70% до 80% — это в основном покрытие длинного хвоста случаев, с гораздо меньшим влиянием на повседневный опыт разработчиков.
Гонка способностей моделей кодинга входит в зону убывающей отдачи.
2. Контекст 1M становится стандартом
Контекстное окно 1M у Qwen3.6-Max-Preview — это уже не «экспериментальная функция», а производственная возможность.
3. Китайские модели входят в первый эшелон
Стратегия «полного покрытия» серии Qwen3.6:
- 27B: Работает на потребительском оборудовании, локальная помощь в кодинге, развёртывание с 18 ГБ ОЗУ
- Plus: API-маршрут с соотношением цена-качество, SWE-bench 78.8%
- Max-Preview: Флагманская демонстрация возможностей
Оценка ландшафта
Когда способности базовых моделей сходятся, конкуренция инструментов кодинга смещается в следующие измерения:
| Измерение | Описание |
|---|---|
| Надёжность | Поведение модели при ошибках |
| Крайние случаи | Обработка нишевых языков, легаси-кода |
| Глубина интеграции | Бесшовное соединение с IDE, CI/CD |
| Мультиагентное сотрудничество | Разделение труда между несколькими агентами |
| Контроль затрат | Динамический баланс между качеством и стоимостью |
Рекомендации к действию
- Не привязывайтесь к одному инструменту кодинга
- Изучите практическое использование контекста 1M
- Оценивайте надёжность рабочих процессов агентов
- Рассмотрите гибридные подходы
Что отслеживать
Конкурентная борьба в сфере ИИ 2026 года сместилась от «кто создаст лучшую модель» к «кто лучше всего интегрирует модели в рабочие процессы». 78.8% Qwen3.6-Max-Preview — важная веха, означающая, что «гонка вооружений» моделей кодинга подходит к концу, и следующий этап конкуренции уже начался.