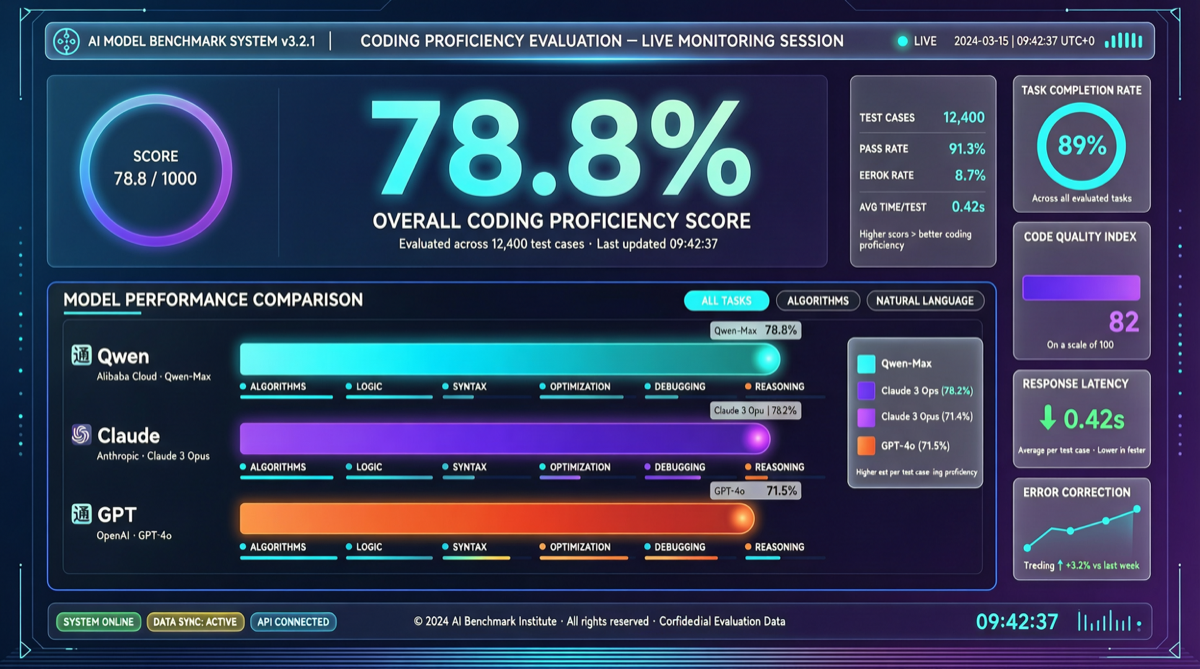
コア判断
Qwen3.6-Max-PreviewがSWE-benchで78.8%、1Mトークンコンテキストウィンドウを獲得——この数字は何を意味するか?Claude Code、Cursor、GitHub Copilotなどのコーディングツールの「基盤モデルの濠」が急速に蒸発していることを意味する。
X上の誰かが率直に言った:「次の差別化は生身の能力ではなく——信頼性、失敗時の優雅さ、負荷下でのエッジケース処理能力だ。」
これはQwenの独壇場ではない。同じ期間、GPT-5.5はSWE-bench Proで58.6%、Claude Opus 4.7は64.3%を獲得。Qwen3.6-Max-Previewが大幅な差でリードしている。
データ比較
| モデル | SWE-bench | SWE-bench Pro | コンテキストウィンドウ | 価格 |
|---|---|---|---|---|
| Qwen3.6-Max-Preview | 78.8% | — | 1Mトークン | 中国クラウドベンダー |
| Claude Opus 4.7 | — | 64.3% | 200K | $15/$75 per 1M |
| GPT-5.5 | — | 58.6% | 1M | $180/M(Pro) |
| Gemini 3.1 Pro | — | — | 1M | $12/M |
| Qwen3.6-Plus | 78.8% | — | 1M | アリババクラウド |
3つの重要なシグナル
1. コーディングモデルは「過飽和」ゾーンに突入
SWE-benchスコアが80%に近づくと、限界改善の価値は急激に低下する。50%から70%への飛躍は質的な変化だが、70%から80%は主にロングテールケースのカバーであり、日常体験への影響は30%から50%ほど大きくない。
つまり、コーディングモデルの能力競争は収穫逓減のゾーンに入っている。
2. 1Mコンテキストが標準に
Qwen3.6-Max-Previewの1Mコンテキストウィンドウはもはや「実験機能」ではなく、本番グレードの機能である。
3. 中国モデルが第一梯隊に参入
Qwen3.6シリーズの「フルスタックカバー」戦略:
- 27B:コンシューマーハードウェアで動作、ローカルコーディング支援、18GBメモリでデプロイ可能
- Plus:APIコストパフォーマンス路線、SWE-bench 78.8%
- Max-Preview:フラッグシップ能力展示、より強力なツール使用とエージェントワークフローの信頼性
市場分析
基盤モデルの能力が収束するとき、コーディングツールの競争は以下の次元にシフトする:
| 次元 | 説明 |
|---|---|
| 信頼性 | モデルが失敗したときの振る舞い |
| エッジケース | ニッチな言語、レガシーコードベースの処理能力 |
| 統合の深さ | IDE、CI/CD、コードレビューとのシームレスな連携 |
| マルチエージェント協調 | 単一モデルの強さではなく、複数のエージェントの分業 |
| コスト管理 | 品質とコストの動的バランス |
アクションアドバイス
- 単一のコーディングツールにロックインしない
- 1Mコンテキストの実践的使い方を学ぶ
- エージェントワークフローの信頼性を評価する
- ハイブリッドアプローチを検討する
注目すべき点
2026年のAI競争は「誰が最高のモデルを作れるか」から「誰がモデルを最も効果的にワークフローに統合できるか」へ移行している。Qwen3.6-Max-Previewの78.8%は重要なマイルストーン——コーディングモデルの「軍備競争」は終わりに近づき、次のフェーズの競争はすでに始まっている。