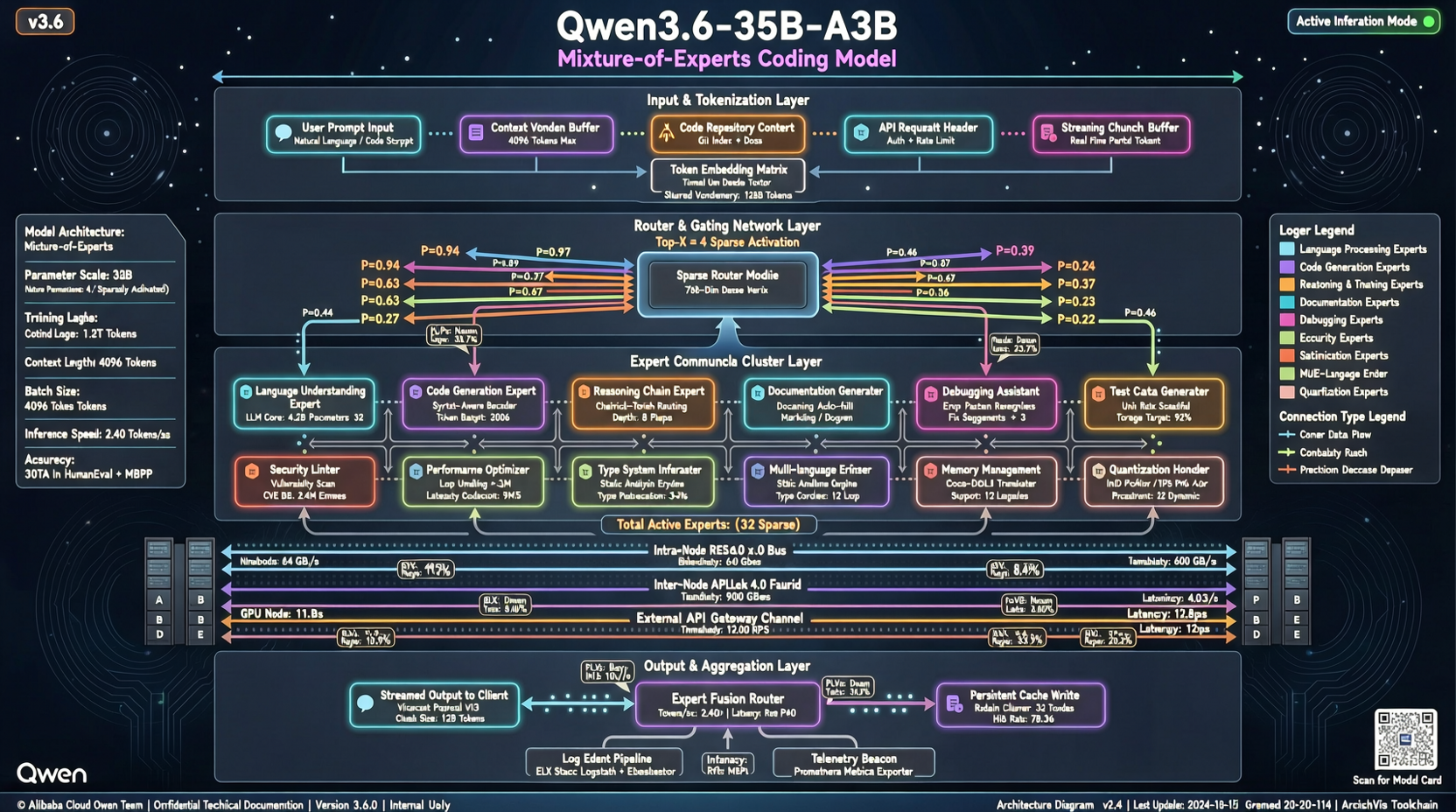
通义千问团队在 Qwen 3.6 系列里藏了一个很有意思的模型:35B-A3B。总参数量 350 亿,但每个 token 只激活 36 亿参数。
社区有人拿它跑编码测试,结论挺炸:在仓库级编码任务上,这个 3B 活跃参数的 MoE 模型追平了 397B 稠密模型的水准。
数字先摆出来
Qwen 3.6-35B-A3B 的核心配置:
- 总参数:35B
- 活跃参数:3.6B(每次推理只激活约 10%)
- 架构:混合专家(MoE),类似 Mixtral 的 sparse MoE 路线
- 部署:已通过 AWS JumpStart 上线,可以用比参数量小得多的实例跑
对比一下同系列的 Qwen3.6-27B 稠密模型:27B 参数全部激活,编码性能也很好,但推理成本和延迟明显更高。
35B-A3B 的意义在于:用十分之一的计算量,拿到了接近全量模型的编码表现。
MoE 路线的"性价比时刻"
MoE 不是新概念。Mixtral 8x7B 早在 2023 年底就证明了这个方向可行。但 Qwen 3.6-35B-A3B 把 MoE 的优势推到了一个新的实用水位:
- 3.6B 活跃参数 ≈ 可以塞进一张消费级 GPU(RTX 4090 24GB 勉强能跑,5090 更轻松)
- 仓库级编码能力 ≈ 之前需要 397B 稠密模型才能达到的水平
- AWS JumpStart 部署:不需要自己管理 GPU,直接调 API
对独立开发者和小型团队来说,这个组合拳相当实用。不用花大价钱租 H100,用中等算力就能跑出一个编码能力不输旗舰模型的本地 Agent。
但是 MoE 也有代价
社区测试也暴露了一些问题。MoE 模型的弱点主要集中在:
- 专家路由不稳定:某些 edge case 下,路由层可能选错专家,导致输出质量骤降
- 长上下文性能衰减:在超长上下文场景下,MoE 的优势不如稠密模型稳定
- 微调复杂度高:LoRA/QLoRA 对 MoE 的支持不如稠密模型成熟,全参微调成本更高
这些问题不是致命的,但意味着 MoE 目前更适合"推理为主、微调为辅"的场景。如果你需要对模型做大量领域适配,稠密模型仍然是更稳妥的选择。
阿里云的算盘
Qwen 3.6 系列的部署策略很清晰:35B MoE 走性价比路线打中端市场,27B 稠密打性能标杆,3.6B 小模型覆盖边缘设备,Max Preview 守旗舰 API。
35B-A3B 上 AWS JumpStart 是一个信号:通义千问在加速进入全球开发者的日常工作流。不再只是"中国模型",而是"可以在 AWS 上一键部署的开源选项"。
这跟 Llama 的策略类似,但 Qwen 在中文能力和编码场景上确实有自己的优势。
下一次值得关注的是 Qwen 3.6 8B 稠密模型——如果 8B 也能接近当前 27B 的编码水平,那边缘部署的门槛就真的降到笔记本级别了。
主要来源:
- Qwen 官方 Hugging Face 页面
- 社区编码测试线程(SWE-bench 变体)
- AWS JumpStart 模型目录