核心结论
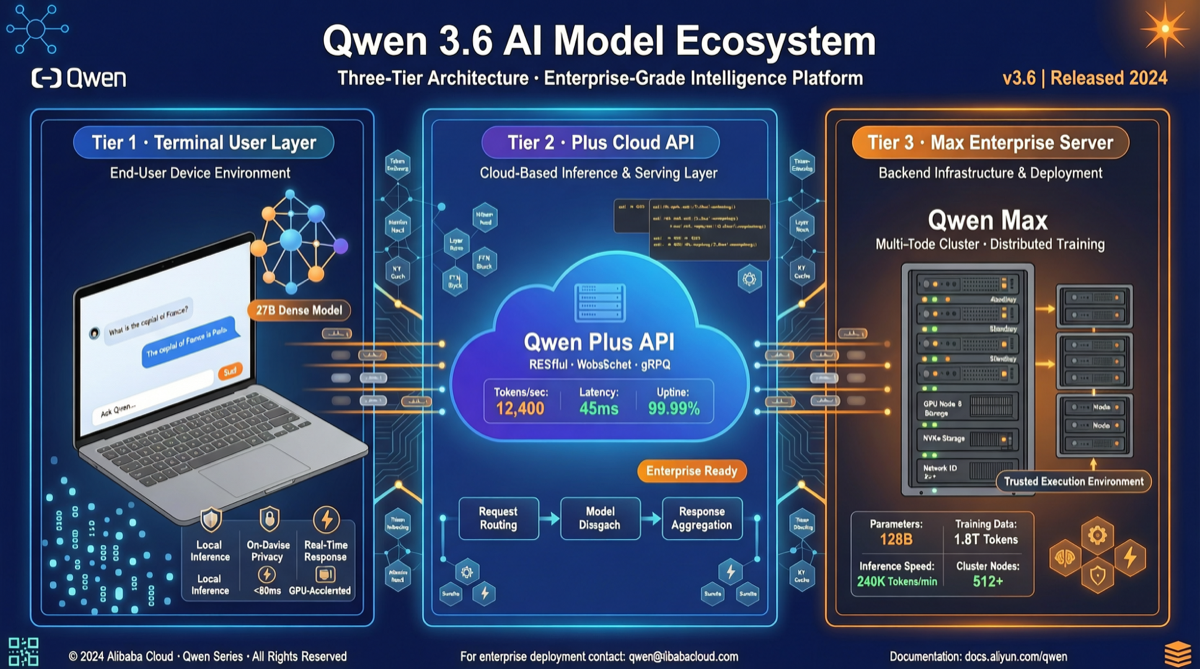
Qwen 3.6 系列不是一个模型,而是一套三层产品矩阵:27B 稠密模型主打本地部署和消费级硬件,Plus 面向性价比敏感的云端用户,Max 则攻坚最复杂的编码和推理任务。三档定价和能力互为补充,形成从边缘到云端的完整覆盖。
更有趣的是,阿里云对 27B API 的定价($0.6/$3.6 per M tokens)高于 Plus($0.5/$3),这看似反直觉,却反映了 27B 模型的独特定位——它不是"缩水版",而是独立产品线。
三层产品矩阵拆解
第一层:Qwen3.6-27B — 边缘端的"小钢炮"
27B 是稠密架构(不是 MoE),意味着所有 270 亿参数在每个 token 生成时都会被激活。这种设计带来了几个关键优势:
| 维度 | 数据 | 含义 |
|---|---|---|
| 参数规模 | 27B 稠密 | 所有参数每次都参与计算 |
| 最低硬件 | 18GB 内存 | MacBook Pro / RTX 4090 可跑 |
| 原生上下文 | 262K | 通过 YaRN 可扩展至 1M |
| SWE-bench | ~77% | 接近 Claude Opus 4.6 水平 |
| Terminal-Bench | 追平 Opus 4.5 | 终端操作能力达旗舰级 |
量化版本已经在 DGX-Spark 上跑出了 95 tps、92 tps 和 73 tps 的性能,超过了 gpt-oss-120B 和 gemma4-26B。这意味着企业可以在自有硬件上部署接近旗舰性能的编码助手,无需依赖云端 API。
第二层:Qwen 3.6 Plus — 性价比的"主力军"
Plus 定位在 27B 和 Max 之间,是大多数日常场景的最优选择:
- API 定价更低:$0.5/$3 per M tokens,比 27B API 便宜 17%-20%
- 推理速度更快:MoE 架构让激活参数量更小,吞吐更高
- 工具调用优化:相比 Qwen 3.5,工具调用的稳定性和准确性有显著提升
- 科学编码跳跃:在数学和科学编程场景的表现大幅提升
Plus 的核心价值主张很明确:用最少的钱,解决 80% 的日常编码和推理需求。
第三层:Qwen 3.6 Max — 复杂任务的"攻坚手"
Max 是 Qwen 3.6 系列中能力最强的版本,面向需要极限性能的场景:
- 256K tokens 原生上下文
- 在 SWE-bench Verified 上表现突出
- 前端 UI 生成能力显著提升
- 适合大型代码库重构和复杂系统架构设计
定价悖论:为什么 27B API 比 Plus 更贵?
这是一个反直觉的定价策略。按常理,参数少的模型应该更便宜。但阿里云的选择恰恰相反。
背后的逻辑可能是:
- 稀缺性定价:27B 的独特价值在于"能在消费级硬件上跑",API 版本提供了无需本地部署的便利,这个便利本身就值得溢价
- 差异化定位:27B 和 Plus 不是"高低配",而是两种不同的技术路线(稠密 vs MoE),各自有独立的用户群
- 生态策略:通过 API 价格引导用户根据实际需求选择——要便宜走 Plus,要特定能力走 27B
格局判断
Qwen 3.6 的三层矩阵策略比单一的"最强模型"叙事更成熟。它认识到:
- 不是所有用户都需要最强模型——大部分日常任务 Plus 就够了
- 本地部署是真实需求——27B 让消费者和中小企业有了不依赖云端的选项
- API 定价可以引导行为——通过价格信号引导用户选择合适的模型
对比 OpenAI 的"一个模型打天下"和 Anthropic 的"少而精"策略,阿里巴巴的 Qwen 3.6 更像是在走安卓路线——用产品矩阵覆盖尽可能多的场景和预算区间。
行动建议
| 你的场景 | 推荐选择 | 理由 |
|---|---|---|
| 本地编码辅助、离线推理 | Qwen3.6-27B | 18GB 内存即可运行,SWE-bench 77% |
| 日常 API 调用、成本敏感 | Qwen 3.6 Plus | 性价比最优,工具调用稳定 |
| 大型代码库、复杂推理 | Qwen 3.6 Max | 极限性能,256K 上下文 |
| 企业私有化部署 | Qwen3.6-27B 量化版 | DGX-Spark 验证,95 tps 吞吐 |
Qwen 3.6 系列的核心竞争力不在于某一个指标跑分第一,而在于它提供了从边缘到云端、从低成本到高性能的完整选择空间。在这个 AI 模型快速迭代、用户选择困难的时代,这种产品策略本身就是一种竞争优势。