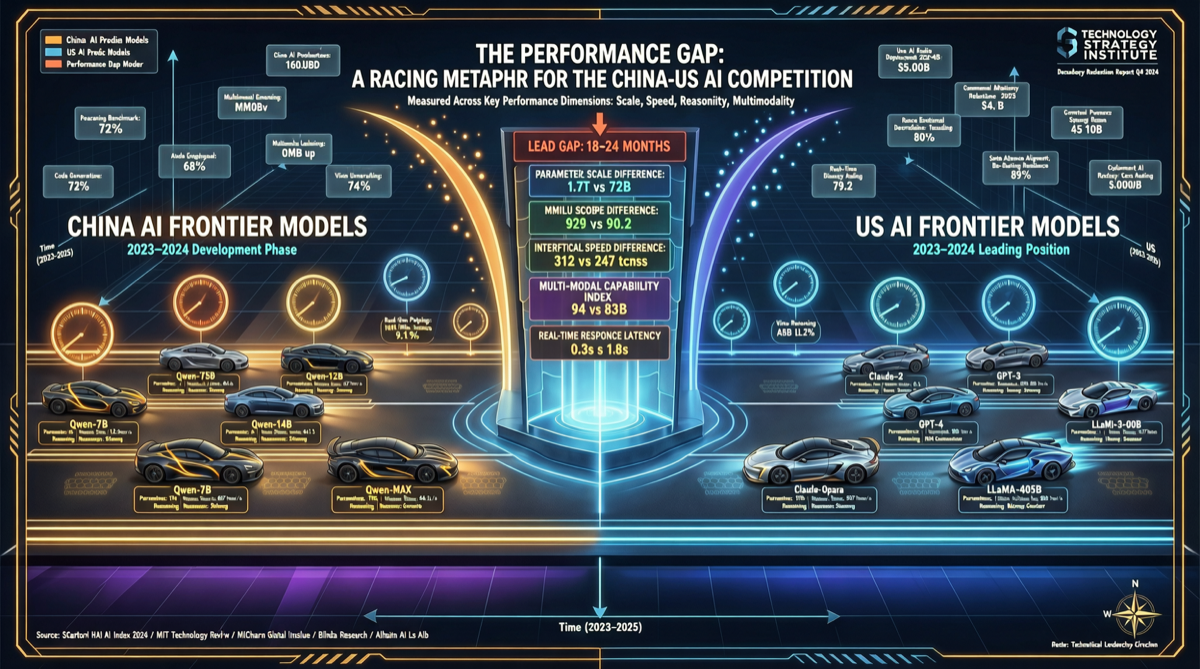
CAISI(美国官方 AI 评测与标准机构)发了一份报告,核心结论很扎眼:DeepSeek V4Pro 相当于去年 8 月发布的 GPT-5,落后美国前沿模型大约 8 个月。
参数不差。跑分不差。那差距从哪来的?
报告给出的答案很明确:实战。
跑分和实战的鸿沟
CAISI 的逻辑不难理解。跑分是标准化的,题目和评分标准都是公开的。DeepSeek V4Pro 在 MMLU、GSM8K、SWE-bench 上的成绩确实可以跟 GPT-5 正面硬刚。
但跑分不等于实战。实战场景有几个跑分测试不到的维度:
工具调用稳定性。在实际 Agent 工作流中,模型需要连续调用多个 API、处理错误、重试、回退。跑分测试通常只测单轮调用的准确率,不测长链路的稳定性。
上下文利用率。给模型 128K 的上下文窗口和让它在 128K 上下文中有效提取关键信息是两回事。CAISI 发现在实际文档处理任务中,DeepSeek V4Pro 的长上下文信息检索效率低于同期的 GPT-5。
多轮对话一致性。在 20 轮以上的复杂对话中,DeepSeek V4Pro 更容易出现前后矛盾或者遗忘早期信息的情况。
这些差距在跑分里看不出来,但在实际使用中会很明显。
"8 个月"这个数字怎么来的
CAISI 没有给出一个精确的公式。但从描述来看,它的对标方法是把 DeepSeek V4Pro 的能力映射到美国模型的时间线上——也就是说,DeepSeek V4Pro 当前的综合能力,大约相当于 GPT-5 在 2025 年 8 月发布时的水平。
这个对标有几个前提假设:
- 美国模型的能力按照可预测的节奏在进步
- 跑分和实战能力之间存在稳定的映射关系
- 8 个月的差距是综合能力差距,不是单一 benchmark 的差距
这些假设都有争议。但作为政府机构的评测框架,它至少提供了一个可讨论的基准。
这个判断公平吗
说实话,有失偏颇的部分也有合理的部分。
合理的部分:实战差距确实存在。DeepSeek 的优势主要在成本——API 价格只有美国模型的几分之一。但如果实际可用性差了,便宜也就没那么大意义了。
有失偏颇的部分:CAISI 的评测框架天然偏向美国模型的生态。评测任务的设计、工具调用接口的定义、甚至 prompt 的语言风格,都以美国模型的交互习惯为基准。换一个评测体系,结果可能不同。
另外,"8 个月"是一个瞬时快照。DeepSeek 的迭代速度很快,如果 V4Pro 在接下来几个月里持续优化工具调用和长上下文能力,这个差距可能在缩小。
社区怎么看
中文社区的反应比较分化。一部分人认为 CAISI 的结论客观——跑分确实不能代表一切,实战差距需要正视。另一部分人认为这是"美国机构给美国模型打分",可信度有限。
英文社区则普遍认为这个报告印证了他们的直觉:DeepSeek 的性价比高,但在生产环境的稳定性上还需要追赶。
我的看法
CAISI 的报告最大的价值不在于"8 个月"这个数字本身,而在于它指出了一个被很多人忽略的问题:跑分和实战之间的差距正在扩大。
随着 Agent 工作流越来越复杂,单一 benchmark 分数能说明的东西越来越少。模型需要在工具调用、长上下文、多轮一致性、错误恢复等多个维度同时及格,才能在生产中真正可用。
DeepSeek 如果想在生产环境跟美国前沿模型正面竞争,下一步要优化的不是跑分,是这些"跑分测不到但用户感受得到"的能力。
主要来源: