结论先行
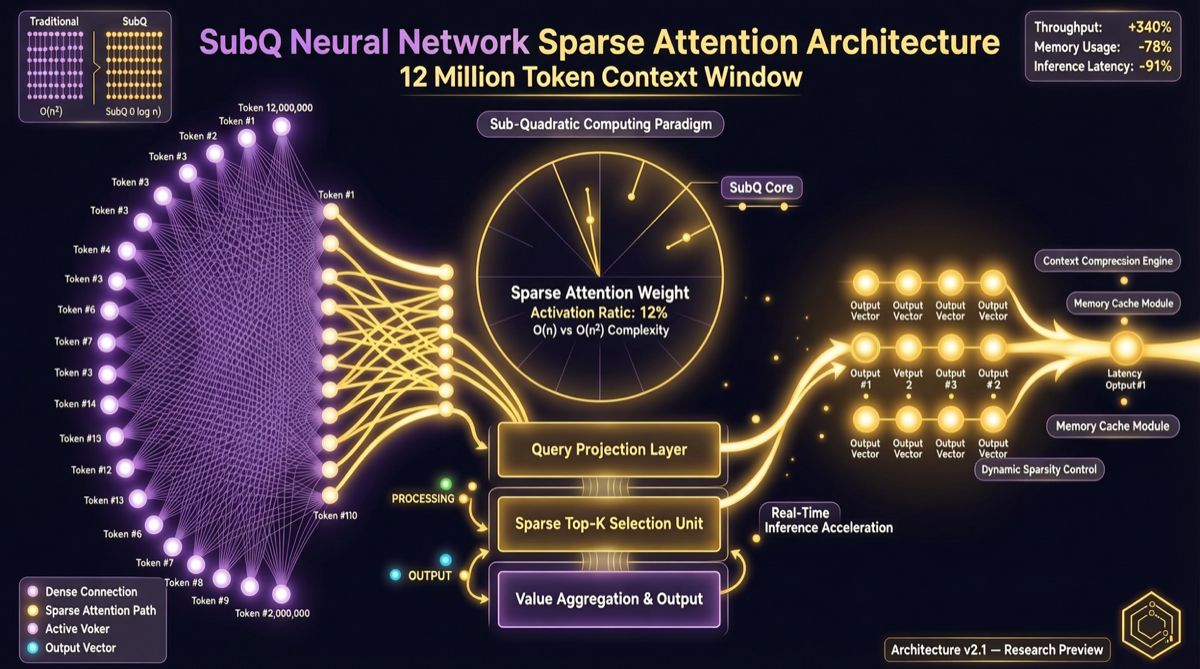
SubQ 不是"又一个更大的上下文窗口"——它是第一个完全基于稀疏注意力架构(SSA) 构建的前沿 LLM。1200 万 Token 上下文、比 FlashAttention 快 52 倍、成本不到 Claude Opus 的 5%——这些数字背后是一个更根本的变化:Transformer 的注意力机制不再是长上下文的唯一解。
三个震撼数字
| 指标 | 数据 | 对比基准 |
|---|---|---|
| 上下文窗口 | 1200 万 Token | 主流模型 128K-200 万的 6-94 倍 |
| 注意力速度 | 快 52 倍(100 万 Token 上) | 对比 FlashAttention |
| 推理成本 | 不到 5% | 对比 Claude Opus |
这条推文收获了 2.2 万点赞、2800 转发——社区的反应说明这不是普通的产品更新。
SSA 架构到底是什么
传统 Transformer 的注意力机制是 all-to-all(全对全):
传统注意力:
每个 Token 都要看所有其他 Token
计算复杂度: O(n²)
1200 万 Token → 144 万亿次运算 → 不可能
SSA(Subquadratic Sparse Attention)的思路:
稀疏注意力:
每个 Token 只看"相关"的 Token
计算复杂度: 亚二次方 O(n^k), k<2
1200 万 Token → 可计算 → 实用
关键区别:
| 维度 | 传统 Transformer | SSA(SubQ) |
|---|---|---|
| 注意力模式 | 全对全(dense) | 稀疏选择(sparse) |
| 计算复杂度 | O(n²) | 亚二次方 O(n^k), k<2 |
| 长上下文效率 | 迅速恶化 | 线性扩展 |
| 内存占用 | 随上下文平方增长 | 接近线性增长 |
为什么 1200 万 Token 有意义
不是"越长越好"的数字游戏——1200 万 Token 解锁了全新的应用场景:
- 整本小说分析:《战争与和平》约 56 万词,1200 万 Token 可以同时加载 20+ 本长篇小说
- 完整代码库:中型项目全部代码 + 文档 + 历史 commit 一次性加载
- 全量法律文书:整个案件卷宗作为上下文,不需要分块策略
- 基因组数据分析:DNA 序列直接作为输入
- 视频内容理解:视频帧序列的超长上下文建模
与现有长上下文方案的对比
| 方案 | 最大上下文 | 架构 | 成本 | 实际可用性 |
|---|---|---|---|---|
| SubQ | 1200 万 Token | SSA | 极低 | ✅ 原生支持 |
| Gemini 3.1 Ultra | 200 万 Token | Transformer | 中等 | ✅ 可用 |
| Claude Opus 4 | 20 万 Token | Transformer | 高 | ⚠️ 贵 |
| GPT-5.5 | 12.8 万 Token | Transformer | 高 | ⚠️ 贵 |
| DeepSeek V4 | 100 万 Token | MoE Transformer | 低 | ✅ 可用 |
SubQ 在上下文长度上领先一个数量级,同时成本更低。
但需要注意
1. 稀疏注意力的代价
- 不是所有 Token 之间的关系都被建模
- 对需要全局精确关联的任务可能有精度损失
- 稀疏模式的选择是关键超参数
2. 生态成熟度
- 新架构意味着工具链、微调框架都需要适配
- 社区资源远不如 Transformer 生态丰富
- 生产部署需要自行验证
3. 基准测试透明度
- 目前公布的主要是速度和成本数据
- 在标准 benchmark(MMLU、SWE-Bench 等)上的表现需要更多验证
- "不到 5% 成本"的对比条件需要进一步确认
格局判断
SubQ 的发布标志着 AI 模型架构领域的一个重要信号:Transformer 之后的下一代架构正在从论文走向现实。
过去两年,LLM 的竞争主要集中在"更大的模型 + 更多的数据"。SubQ 证明架构创新可能比规模扩张带来更大的回报。如果 SSA 架构在更多 benchmark 上验证了其能力,它可能成为长上下文场景的默认选择。
可以怎么用
| 场景 | 建议 |
|---|---|
| 超长文档分析 | 直接替换传统方案,1200 万上下文无需分块 |
| 代码库级理解 | 整仓加载,Agent 可以看到完整项目结构 |
| 成本敏感场景 | 不到 5% 的成本对大批量处理有吸引力 |
| 实验性项目 | 尝试 SSA 架构在新场景中的表现 |
| 生产环境 | 建议先在非关键场景验证,等待更多 benchmark 数据 |
下一步关注
- SubQ 在 SWE-Bench、MMLU 等标准 benchmark 上的表现
- 社区对 SSA 架构的微调和适配工具
- 其他模型厂商是否会跟进稀疏注意力路线
- SSA 在短上下文场景(<10 万 Token)上是否有优势