Главный Вывод
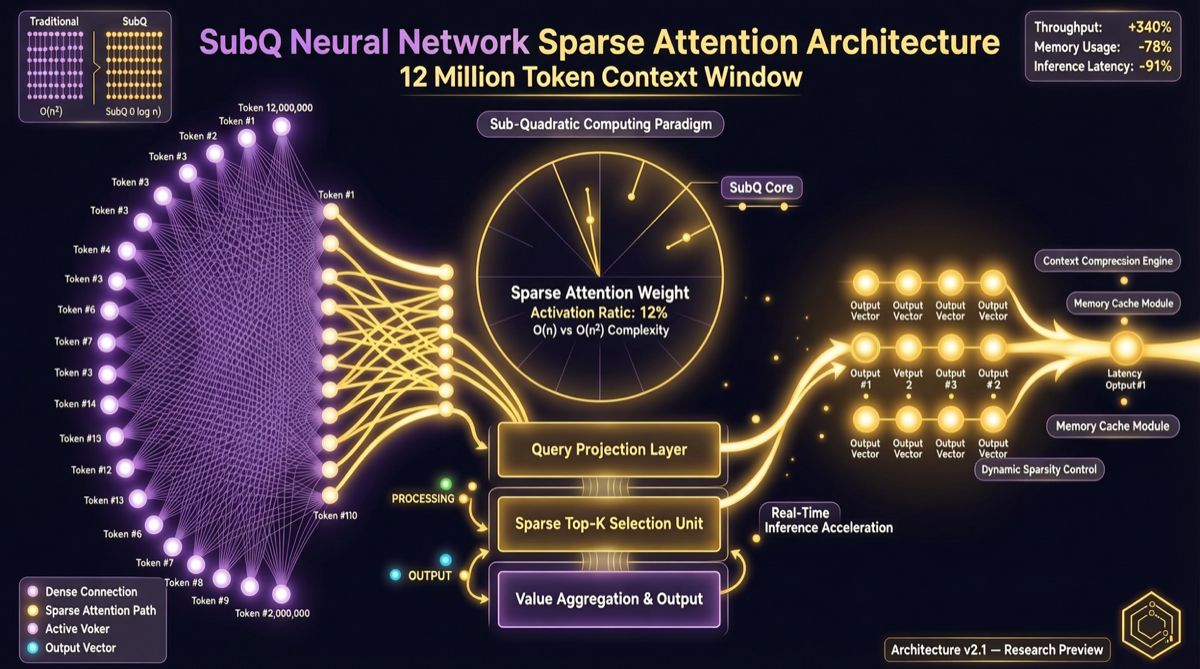
SubQ — это не «ещё одно большое контекстное окно». Это первая фронтальная LLM, полностью построенная на архитектуре Subquadratic Sparse Attention (SSA). 12 миллионов токенов контекста, в 52 раза быстрее FlashAttention, менее 5% стоимости Claude Opus — за этими числами стоит более фундаментальный сдвиг: внимание трансформеров больше не единственный ответ для длинного контекста.
Три Поражающих Числа
| Показатель | Данные | По Сравнению С |
|---|---|---|
| Контекстное Окно | 12 Миллионов Токенов | В 6-94 раз больше, чем у мейнстримных моделей на 128K-2M |
| Скорость Внимания | В 52 Раз Быстрее (при 1М токенах) | По сравнению с FlashAttention |
| Стоимость Вывода | Менее 5% | По сравнению с Claude Opus |
Этот твит получил 22 тысячи лайков и 2,8 тысячи ретвитов — реакция сообщества показывает, что это не обычное обновление продукта.
Что Такое Архитектура SSA
Традиционное внимание трансформеров — это all-to-all (полное ко полному):
Традиционное Внимание:
Каждый токен смотрит на все остальные токены
Вычислительная сложность: O(n²)
12М токенов → 144 триллиона операций → невозможно
Подход SSA (Subquadratic Sparse Attention):
Разреженное Внимание:
Каждый токен смотрит только на «релевантные» токены
Вычислительная сложность: Субквадратичная O(n^k), k<2
12М токенов → вычислимо → практично
Ключевые различия:
| Измерение | Традиционный Трансформер | SSA (SubQ) |
|---|---|---|
| Паттерн Внимания | Полное ко полному (dense) | Разреженный выбор |
| Вычислительная Сложность | O(n²) | Субквадратичная O(n^k), k<2 |
| Эффективность Длинного Контекста | Быстро ухудшается | Близкое к линейному масштабирование |
| Использование Памяти | Растёт квадратично с контекстом | Близкое к линейному росту |
Почему 12М Токенов Имеет Значение
Это не игра в числа «чем больше, тем лучше» — 12 миллионов токенов открывают совершенно новые сценарии использования:
- Анализ целых романов: «Война и мир» ~560 тысяч слов, 12М токенов могут одновременно загрузить 20+ полных романов
- Полные кодовые базы: Весь код + документация + история коммитов проекта среднего размера загружаются за раз
- Полные юридические дела: Всё дело как контекст, не нужна стратегия разделения
- Анализ геномных данных: Последовательности ДНК как прямой ввод
- Понимание видеоконтента: Ультрадлинное контекстное моделирование последовательностей видеокадров
Сравнение с Существующими Решениями Длинного Контекста
| Решение | Макс. Контекст | Архитектура | Стоимость | Практическая Применимость |
|---|---|---|---|---|
| SubQ | 12М Токенов | SSA | Очень Низкая | ✅ Нативная поддержка |
| Gemini 3.1 Ultra | 2М Токенов | Трансформер | Средняя | ✅ Применимо |
| Claude Opus 4 | 200K Токенов | Трансформер | Высокая | ⚠️ Дорого |
| GPT-5.5 | 128K Токенов | Трансформер | Высокая | ⚠️ Дорого |
| DeepSeek V4 | 1М Токенов | MoE Трансформер | Низкая | ✅ Применимо |
SubQ лидирует на порядок по длине контекста, оставаясь при этом дешевле.
Но Есть Ограничения
1. Цена Разреженного Внимания
- Не все связи между токенами моделируются
- Возможна потеря точности на задачах, требующих глобальных точных ассоциаций
- Выбор разреженного паттерна — критический гиперпараметр
2. Зрелость Экосистемы
- Новая архитектура означает, что цепочки инструментов и фреймворки тонкой настройки нуждаются в адаптации
- Ресурсы сообщества значительно беднее, чем экосистема трансформеров
- Продакшн-развёртывание требует самостоятельной валидации
3. Прозрачность Бенчмарков
- В настоящее время опубликованные данные сосредоточены в основном на скорости и стоимости
- Производительность на стандартных бенчмарках (MMLU, SWE-Bench и т.д.) требует дополнительной проверки
- Условия сравнения «менее 5% стоимости» нуждаются в дальнейшем подтверждении
Оценка Ландшафта
Релиз SubQ отмечает важный сигнал в области архитектуры ИИ-моделей: архитектуры нового поколения за пределами трансформеров переходят от статей к реальности.
За последние два года конкуренция LLM сосредоточилась на «больших моделях + больше данных». SubQ доказывает, что архитектурная инновация может принести большую отдачу, чем масштабирование. Если архитектура SSA подтвердит свои способности на большем количестве бенчмарков, она может стать выбором по умолчанию для сценариев с длинным контекстом.
Как Использовать
| Сценарий | Рекомендация |
|---|---|
| Анализ ультрадлинных документов | Прямая замена традиционных решений, 12М контекст устраняет необходимость разделения |
| Понимание на уровне кодовой базы | Загрузка целых репозиториев, агенты видят полную структуру проекта |
| Чувствительные к стоимости сценарии | Стоимость менее 5% привлекательна для крупносерийной обработки |
| Экспериментальные проекты | Попробовать производительность архитектуры SSA в новых сценариях |
| Продакшн-окружение | Рекомендуется сначала валидировать в некритичных сценариях, подождать больше данных бенчмарков |
Что Смотреть Далее
- Производительность SubQ на стандартных бенчмарках, таких как SWE-Bench, MMLU
- Инструменты сообщества для тонкой настройки и адаптации архитектуры SSA
- Последуют ли другие поставщики моделей по пути разреженного внимания
- Есть ли у SSA преимущества в сценариях короткого контекста (<100K токенов)