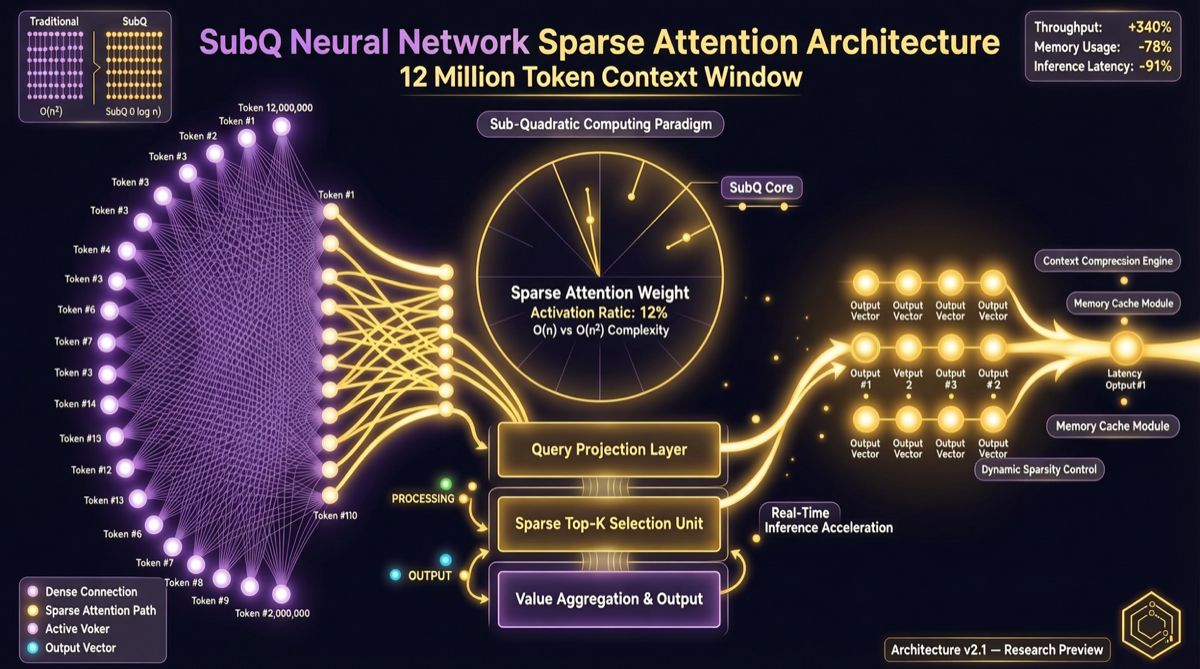
結論から
SubQは「もう一つ大きいコンテキストウィンドウ」ではない——SSA(Subquadratic Sparse Attention)アーキテクチャで完全に構築された初めてのフロンティアLLMだ。1200万Tokenコンテキスト、FlashAttentionより52倍高速、Claude Opusの5%未満のコスト——これらの数字の背後にはより根本的な変化がある:Transformerの注意機構はもはや長コンテキストの唯一の解ではない。
3つの衝撃的数字
| 指標 | データ | 比較基準 |
|---|---|---|
| コンテキストウィンドウ | 1200万Token | 主流モデル128K-200万の6〜94倍 |
| 注意力速度 | 52倍高速(100万Tokenで) | FlashAttentionと比較 |
| 推論コスト | 5%未満 | Claude Opusと比較 |
このツイートは2.2万いいね、2800リツイートを獲得——コミュニティの反応はこれが普通の製品アップデートではないことを示している。
SSAアーキテクチャとは何か
従来のTransformerの注意機構は all-to-all(全対全):
従来の注意力:
すべてのTokenが他のすべてのTokenを見る
計算複雑度: O(n²)
1200万Token → 144兆回の演算 → 不可能
SSA(Subquadratic Sparse Attention)のアプローチ:
疎な注意力:
各Tokenは「関連する」Tokenのみを見る
計算複雑度: 亜二次方 O(n^k), k<2
1200万Token → 計算可能 → 実用的
主な違い:
| 次元 | 従来のTransformer | SSA(SubQ) |
|---|---|---|
| 注意力パターン | 全対全(dense) | 疎な選択(sparse) |
| 計算複雑度 | O(n²) | 亜二次方 O(n^k), k<2 |
| 長コンテキスト効率 | 急速に悪化 | 線形スケーリングに近い |
| メモリ使用量 | コンテキストの二乗で増加 | 線形に近い増加 |
なぜ1200万Tokenが意味を持つのか
「長ければ長いほど良い」数字遊びではない——1200万Tokenは全く新しいユースケースを解放する:
- 小説全体の分析: 『戦争と平和』は約56万語、1200万Tokenで長編小説20冊以上を同時にロード可能
- 完全なコードベース: 中規模プロジェクトの全コード+ドキュメント+コミット履歴を一括ロード
- 法律文書の全量: 事件の全書類をコンテキストとして、チャンキング戦略は不要
- ゲノムデータ分析: DNA配列を直接入力
- ビデオコンテンツ理解: ビデオフレームシーケンスの超長コンテキストモデリング
既存の長コンテキストソリューションとの比較
| ソリューション | 最大コンテキスト | アーキテクチャ | コスト | 実用性 |
|---|---|---|---|---|
| SubQ | 1200万Token | SSA | 極めて低い | ✅ ネイティブサポート |
| Gemini 3.1 Ultra | 200万Token | Transformer | 中程度 | ✅ 利用可能 |
| Claude Opus 4 | 20万Token | Transformer | 高い | ⚠️ 高価 |
| GPT-5.5 | 12.8万Token | Transformer | 高い | ⚠️ 高価 |
| DeepSeek V4 | 100万Token | MoE Transformer | 低い | ✅ 利用可能 |
SubQはコンテキスト長さで1桁リードしながら、コストはより低い。
ただし注意点あり
1. 疎な注意力の代償
- すべてのToken間の関係がモデル化されているわけではない
- グローバルな正確な関連性を必要とするタスクでは精度損失の可能性
- 疎なパターンの選択が重要なハイパーパラメータ
2. エコシステムの成熟度
- 新アーキテクチャはツールチェーン、ファインチューニングフレームワークの適応が必要
- コミュニティリソースはTransformerエコシステムに比べてはるかに乏しい
- 本番デプロイには自行検証が必要
3. ベンチマークの透明性
- 現在公表されているのは主に速度とコストデータ
- 標準ベンチマーク(MMLU、SWE-Benchなど)でのパフォーマンスはさらなる検証が必要
- 「5%未満コスト」の比較条件はさらなる確認が必要
情勢判断
SubQのリリースはAIモデルアーキテクチャ分野における重要なシグナルだ:Transformerの次世代アーキテクチャが論文から現実へ移行しつつある。
過去2年間、LLMの競争は「より大きなモデル+より多くのデータ」に集中していた。SubQはアーキテクチャ革新が規模拡張よりも大きなリターンをもたらす可能性を証明した。もしSSAアーキテクチャがより多くのベンチマークでその能力を検証すれば、長コンテキストシナリオのデフォルトチョイスになるかもしれない。
活用方法
| シナリオ | 推奨 |
|---|---|
| 超長文書分析 | 従来のソリューションを直接置換、1200万コンテキストでチャンキング不要 |
| コードベースレベルの理解 | リポジトリ全体をロード、エージェントが完全なプロジェクト構造を把握 |
| コスト敏感シナリオ | 5%未満のコストは大量バッチ処理に魅力的 |
| 実験的プロジェクト | 新シナリオでのSSAアーキテクチャのパフォーマンスを試す |
| 本番環境 | 重要でないシナリオでまず検証し、より多くのベンチマークデータを待つことを推奨 |
次に注目すべき点
- SWE-Bench、MMLUなどの標準ベンチマークでのSubQのパフォーマンス
- SSAアーキテクチャのファインチューニングと適応のコミュニティツール
- 他のモデルベンダーが疎な注意力ルートに追随するかどうか
- 短コンテキストシナリオ(<10万Token)でSSAに優位性があるかどうか