Google 在改 Gemini 的 API 结构。改动不大,但方向很明确。
以前 Gemini API 的交互模型是标准对话式的:user 发一条消息,model 回一条消息。一轮一轮来,角色泾渭分明。
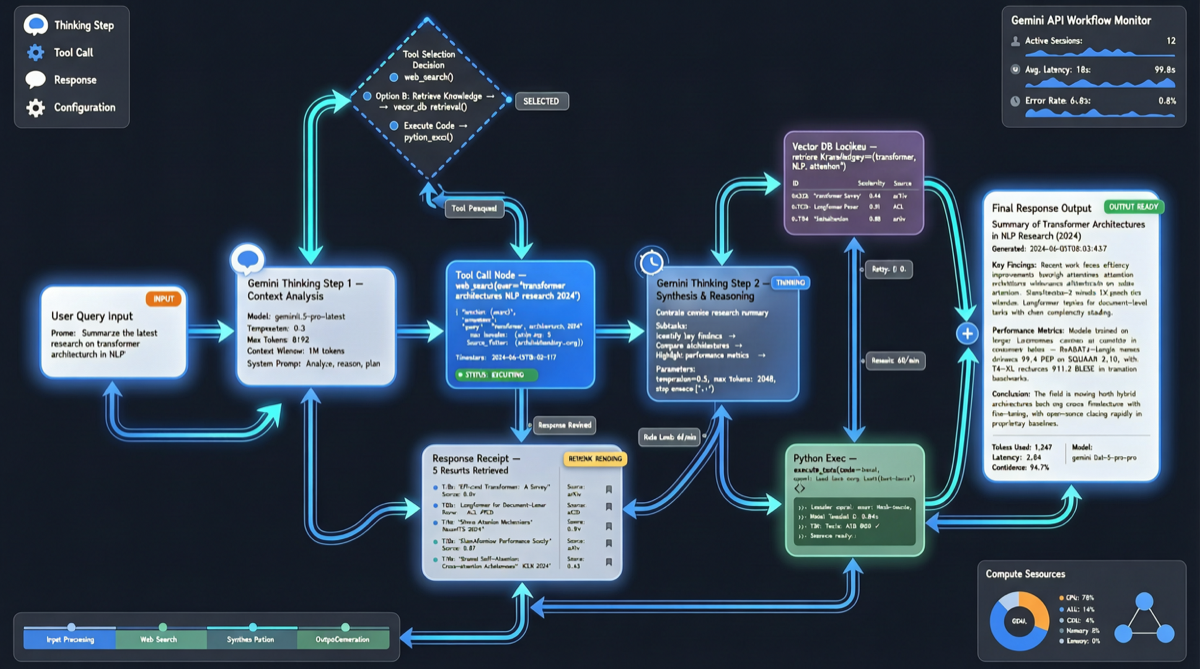
现在 Google 把这套模型拆了。新的 Gemini Interactions API 里,不再有严格的 user 和 model 角色区分。每一次思考、每一次工具调用、每一次输出,都被表示为独立的 step。
这意味着什么?
从"对话"到"工作流"
标准对话 API 适合问答。你问我答,干净利落。
但 Agent 场景不是这样的。一个 Agent 完成复杂任务时,内部的步骤是乱的:它可能先思考,然后调用工具 A,拿到结果后再思考,接着调用工具 B,中途发现需要用户补充信息,再暂停等用户输入。
旧的 user/model 角色模型在这种场景下很别扭。你不得不把 Agent 的内部思考伪装成 user 消息发给 API,或者把工具调用的结果包装成 model 响应。接口和实际行为不匹配。
新的 step 模型直接把这种复杂性暴露出来。每个动作都是第一公民,API 不再试图把它们塞进对话的壳子里。
具体怎么变
Google 的官方博客给了一个关键描述:
"Instead of strict 'user' and 'model' roles, every action (from thinking to tool calls) is now represented as its own step."
翻译过来就是:不再强制区分谁在说话,每一步就是每一步。
这意味着开发者可以:
- 看到 Agent 的完整思考链,而不是只拿到最终答案
- 在 Agent 执行过程中干预特定 step,而不是只能等一轮结束
- 把多步 Agent 的执行过程序列化、持久化、回放
这对需要审计和调试的 enterprise 场景来说很实用。
和竞品的对比
Anthropic 的 Claude API 已经有了类似的能力——它的 message API 支持 tool_use 和 tool_result 作为独立的消息类型。OpenAI 的 Responses API 也在向这个方向走。
Google 这次改动的特别之处在于,它不是在现有 API 上加 patch,而是重新设计了交互模型。这暗示 Google 正在为更复杂的多 Agent 协作场景做准备。
如果每个 step 都是独立可寻址的,那理论上多个 Agent 可以在同一个 Interaction 里交错执行各自的 step,而不会互相干扰。
什么时候能用
Google 说这是"evolving",意味着还在进行中。没有给出 GA 时间线。
但考虑到 Google Cloud Next 2026 上已经展示过类似的 agentic workflow 概念,这个 API 改动大概率会在近期推 GA。
我的看法
这是一个"开发者无感但对架构影响深远"的改动。普通用户不会注意到任何东西变化,但 build on top of Gemini 的人会发现 Agent 开发变得更顺手了。
值得观察的后续:Google 是否会围绕这个新的 step 模型推出配套的 Agent 编排工具,类似于 Anthropic 的 MCP 或者 Google 自己的 ADK。如果有的话,Gemini 生态的 Agent 开发门槛会明显降低。
主要来源: