GoogleがGeminiのAPI構造を変更している。変更は大きくないが、方向性は明確だ。
以前のGemini APIのインタラクションモデルは標準的な会話形式だった:userがメッセージを送り、modelが返信する。ラウンドごとに役割がはっきり分かれていた。
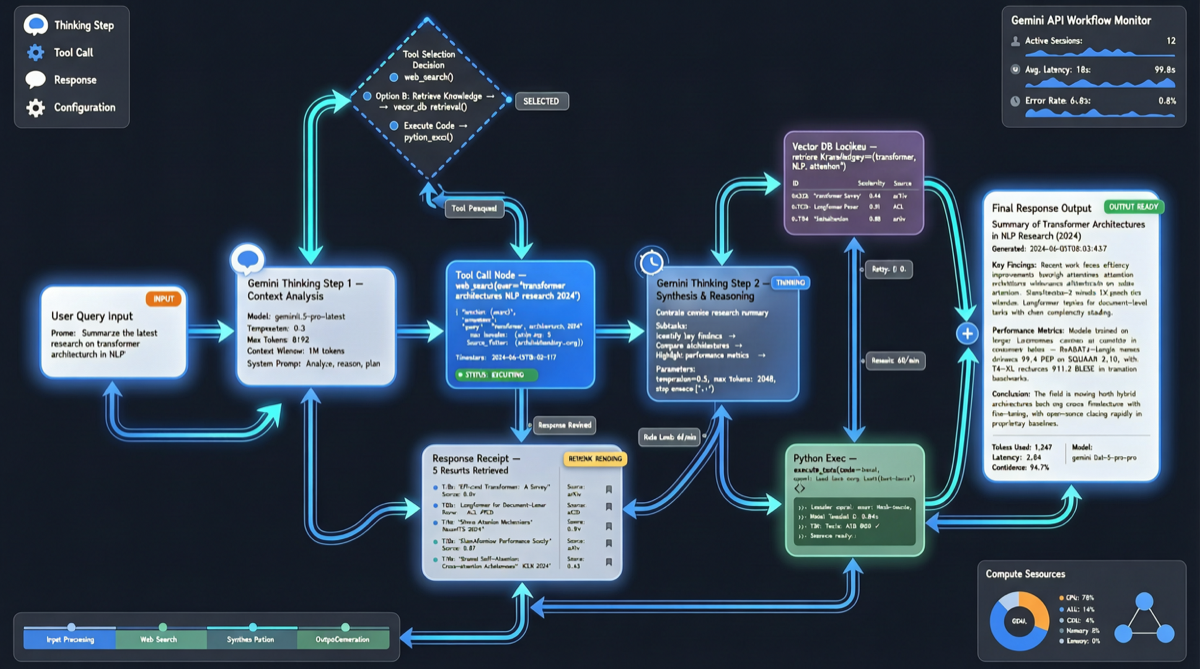
現在、Googleはそのモデルを解体した。新しいGemini Interactions APIでは、userとmodelの厳密な役割区別はもうない。各思考、各ツール呼び出し、各出力が独立したstepとして表現される。
これは何を意味するのか?
「会話」から「ワークフロー」へ
標準会話APIはQ&Aに適している。あなたが問い、私が答える。シンプルで清潔。
だがエージェントシナリオは違う。エージェントが複雑なタスクを完了するとき、内部のステップは混沌としている:まず考え、ツールAを呼び出し、結果を得てもう一度考え、ツールBを呼び出し、途中でユーザーの入力が必要だと気づき、一時停止して待つ。
古いuser/model役割モデルはこのシナリオでぎこちない。エージェントの内部思考をuserメッセージとしてAPIに偽装するか、ツール呼び出しの結果をmodelレスポンスとしてパッケージする必要があった。インターフェースと実際の振る舞いが一致していない。
新しいstepモデルはこの複雑さをそのまま公開する。各アクションがファーストクラス市民。APIはもうそれらを会話の殻に詰め込もうとしない。
具体的に何が変わるのか
Googleの公式ブログが重要な説明をした:
「厳密な'user'と'model'の役割の代わりに、すべてのアクション(思考からツール呼び出しまで)が独自のstepとして表現される。」
つまり開発者は:
- エージェントの完全な思考チェーンを最終回答だけでなく見られる
- エージェント実行中に特定のstepに介入できる、ラウンド終了まで待たなくていい
- マルチステップエージェントの実行プロセスをシリアライズ、永続化、リプレイできる
監査とデバッグが必要なエンタープライズシナリオで非常に実用的だ。
競合との比較
AnthropicのClaude APIはすでに同様の機能を持つ — message APIはtool_useとtool_resultを独立したメッセージタイプとしてサポートする。OpenAIのResponses APIもこの方向に向かっている。
Googleの今回の変更の特別之处在于:既存のAPIにパッチを当てたのではなく、インタラクションモデルを再設計したことだ。これはGoogleがより複雑なマルチエージェントコラボレーションシナリオを準備していることを示唆する。
各stepが独立してアドレサブルなら、理論的に複数のエージェントが同じInteraction内でそれぞれのstepを交差実行でき、互いに干渉しない。
いつ使えるようになるか
Googleはこれを「evolving」と表現している — まだ進行中だということ。GAのタイムラインは示されていない。
ただし、Google Cloud Next 2026で既に類似のエージェントワークフロー概念がデモンストレーションされていることを考慮すると、このAPI変更は間もなくGAになる可能性が高い。
所感
これは「開発者は感じないがアーキテクチャに影響深远な」変更だ。一般ユーザーは何の変化にも気づかないが、Geminiの上に構築する人はエージェント開発がはるかにスムーズになることに気づくだろう。
注目に値する后续:Googleがこの新しいstepモデルを中心に、AnthropicのMCPやGoogle自身のADKに似たエージェントオーケストレーションツールをリリースするかどうか。もしあれば、Geminiエコシステムのエージェント開発敷居は明らかに下がる。
主な情報源: