Вывод
Если вас утомляли операции с векторными базами данных, настройка эмбеддингов и стратегии чанкования — PageIndex стоит внимания. Он выбрасывает весь пайплайн embedding → векторный поиск → rerank, заменяя его рассуждениями LLM для определения релевантных секций документа. Звучит радикально. После тестирования — действительно работает.
Цена — задержка. Векторный поиск возвращает результат за миллисекунды. PageIndex требует, чтобы LLM прочитал индекс документа и определил релевантность. Если ваш сценарий допускает задержку в несколько секунд, этот подход значительно чище традиционного RAG.
Что он делает
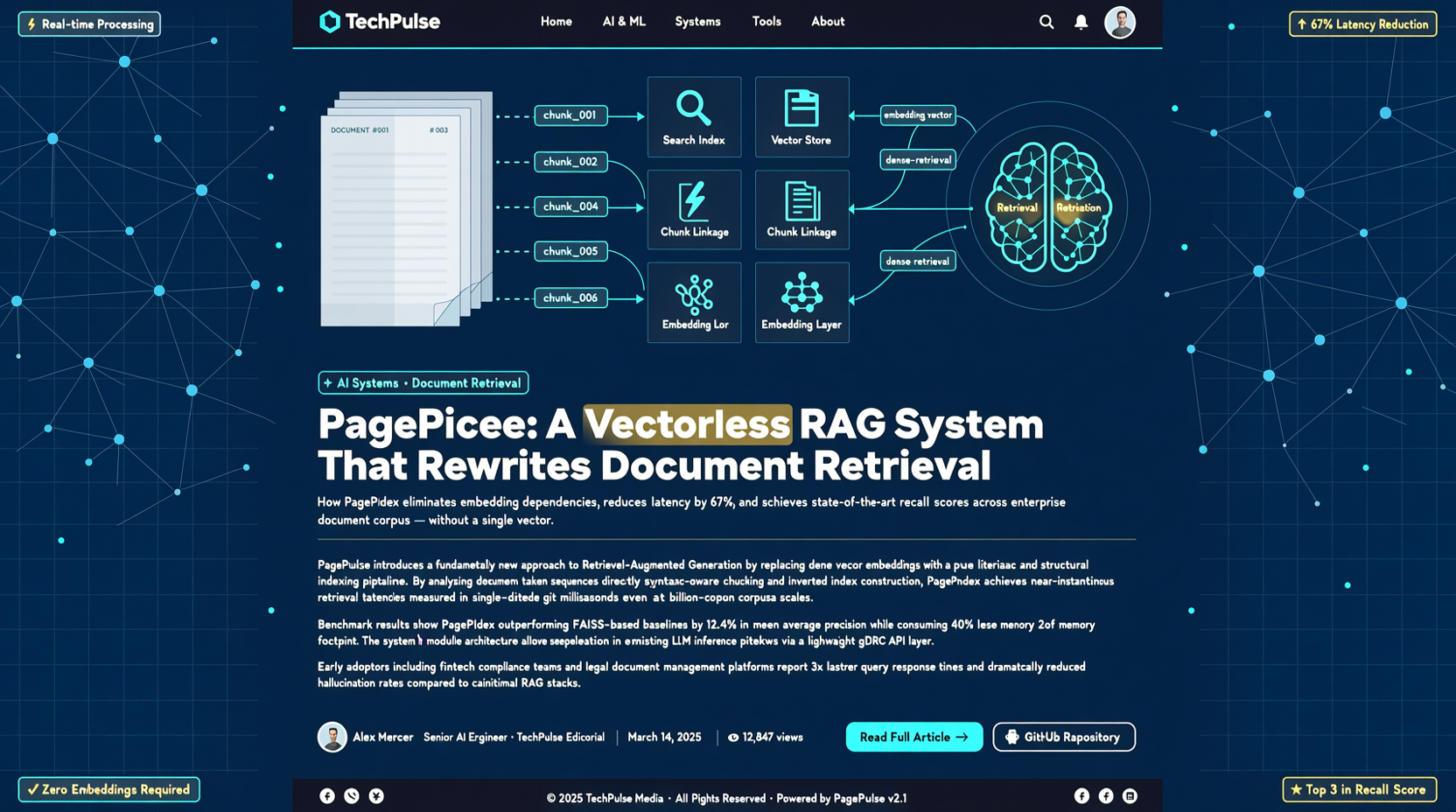
Традиционный RAG всем знаком:
Документ → чанкование → эмбеддинг → сохранение в векторной БД → запрос → векторный поиск → rerank → отправка в LLM
Длинная цепочка, множество точек отказа.
Подход PageIndex: пропустить эмбеддинги, построить структурированный индекс документов и позволить LLM рассуждать о том, какую секцию читать.
PageIndex строит не векторный индекс, а семантическую иерархию документа. При поиске LLM сначала читает индекс, определяет, какая глава или абзац наиболее релевантны, затем читает только эту часть. Это как позволить модели «сначала посмотреть оглавление, а потом листать страницы».
Тестирование
Я тестировал на наборе технической документации из 200 страниц, сравнивая со стандартным стеком LangChain + ChromaDB + BGE embedding.
Качество ответов: PageIndex показал лучшие результаты на вопросах, требующих рассуждений между главами. Традиционный RAG часто находит только одну секцию, тогда как PageIndex может определить обе главы одновременно — индекс сохраняет иерархию документа.
Задержка: Главный недостаток. Традиционный подход — 2-3 секунды на поиск + генерацию. PageIndex — 1-2 секунды только на рассуждение по индексу, плюс генерация, итого 4-6 секунд. Для диалогов в реальном времени это ощутимо.
Кому подойдёт
- Документационные базы знаний: Технические документы, руководства, юридические тексты — документы с чёткой структурой глав
- Сценарии, где точность важнее скорости: Внутренние ассистенты, исследовательские инструменты
- Команды, уставшие от обслуживания векторных БД: Не нужна векторная база данных, не нужен пайплайн эмбеддингов
Кому не подойдёт
- Чат в реальном времени: Проблема задержки短期内 не решается
- Неструктурированные данные: Логи чатов, письма, соцсети — без чёткой иерархии эффективность индексирования падает
Основные источники: