結論から
ベクトルデータベースの運用、embeddingチューニング、チャンク戦略に頭を悩ませたことがあるなら、PageIndexは值得一見だ。embedding → ベクトル検索 → rerank というパイプラインを丸ごと捨て、LLMの推論で関連ドキュメントセクションを特定する。ラディカルに聞こえるかもしれないが、実際に動かしてみて——確かに使える。
代償はレイテンシー。ベクトル検索はミリ秒で返ってくる。PageIndexはLLMがドキュメントインデックスを読んで関連性を推論する必要がある。数秒の遅延を許容できるユースケースなら、このアプローチは従来のRAGよりずっとクリーンだ。
何をやっているのか
従来のRAGの套路は皆知っている:
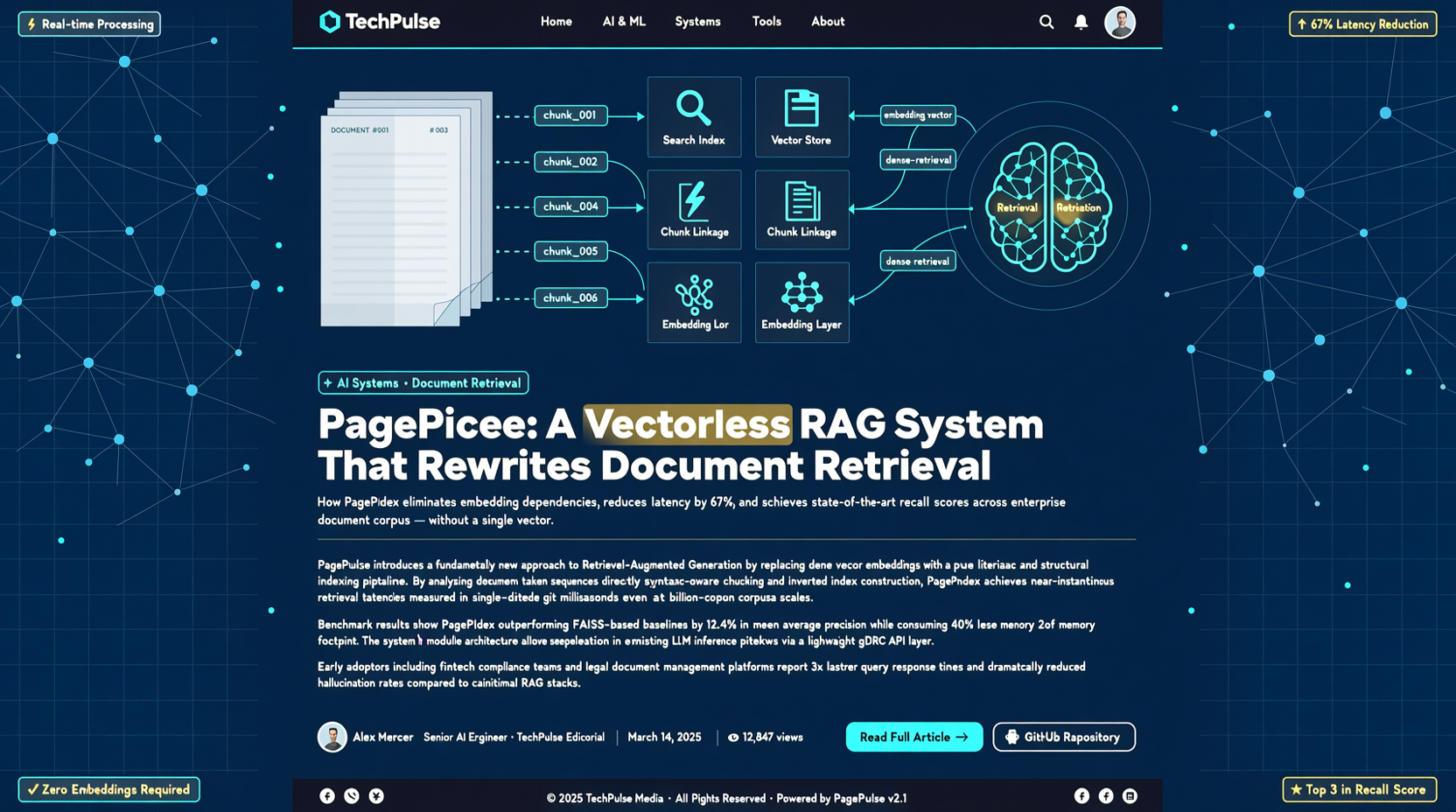
ドキュメント → チャンク分割 → embedding → ベクターDB保存 → ユーザークエリ → ベクトル検索 → rerank → LLMに投入
チェーンが長く、失敗ポイントも多い。
PageIndexのアプローチは違う:embeddingを飛ばして、ドキュメントの構造化インデックスを構築し、LLMにどのセクションを読むべきか推論させる。
PageIndexはベクトルインデックスではなく、ドキュメントのセマンティック階層を構築する。検索時、LLMはまずインデックスを読み、どのチャプターやパラグラフが最も関連性が高いかを判断し、その部分だけを読む。モデルに「目次を確認してからページをめくらせる」ようなものだ。
実測
200ページの技術ドキュメントセットでテスト。LangChain + ChromaDB + BGE embeddingの標準構成と比較した。
回答品質:PageIndexはチャプター横断的な推論問題で優れたパフォーマンスを発揮した。従来のRAGは一つのセクションしか取得できないことが多いが、PageIndexは両方のチャプターを同時に特定できる。インデックスがドキュメントの階層構造を保持しているためだ。
レイテンシー:最大のペインポイント。従来アプローチは検索+生成で2〜3秒。PageIndexはインデックス推論だけで1〜2秒、生成を含めて4〜6秒。リアルタイム会話には体感差がある。
向いている人
- ドキュメント型ナレッジベース:技術文書、製品マニュアル、法条項——明確なチャプター構造を持つドキュメントはPageIndexの強みを活かせる
- 精度>レイテンシーのシーン:内部ナレッジアシスタント、研究ツール
- ベクターDB運用に疲れたチーム:ベクターDB不要、embeddingパイプライン不要
向いていない人
- リアルタイムチャット:レイテンシー問題は短期的に解決困難
- 非構造化データ:チャットログ、メール、ソーシャル投稿——明確な階層構造がないとインデックス効果が落ちる
主要ソース: