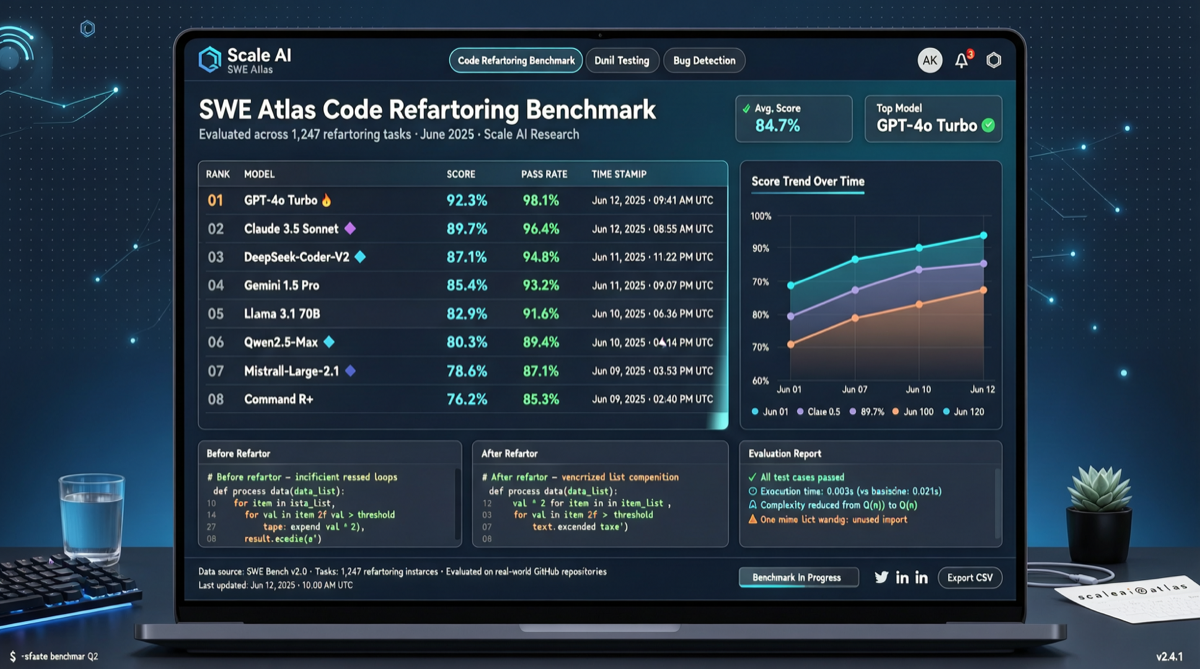
После SWE-Bench наконец-то появился бенчмарк, который обратил внимание на самую грязную часть разработки ПО — рефакторинг.
Scale AI только что выпустила SWE Atlas Refactoring Leaderboard — первый бенчмарк, специально разработанный для оценки способностей AI-агентов к рефакторингу кода. В отличие от задач SWE-Bench «исправь один баг», рефакторинг требует от агентов внесения структурных изменений в существующие кодовые базы, генерируя более чем вдвое больший объём кода по сравнению с SWE-Bench Pro.
Результат не удивительный, но и не скучный: Claude Code в связке с Opus 4.7 занимает первое место. Но кто на втором, насколько велик разрыв между моделями и что именно измеряет этот бенчмарк — вот где настоящая история.
Почему рефакторинг сложнее исправления багов
Исправление бага — это «найти проблему, изменить одну строку, запустить тесты». Рефакторинг — это «прочитать гору старого кода, понять замысел дизайна, а затем реструктурировать, не ломая поведение».
Что делает SWE Atlas сложным:
- Объём кода: агентам нужно обрабатывать рефакторинг на уровне модулей или даже всего репозитория
- Сохранение поведения: отрефакторенный код должен пройти все существующие тесты — это жёсткое ограничение
- Удвоенный объём вывода: в два раза больше кода, чем SWE-Bench Pro, означает, что речь не о правке нескольких строк, а о структурных изменениях
Иными словами, это бенчмарк «вкуса к коду». Можешь ли ты сделать плохой код хорошим, не добавив новых багов?
Результаты рейтинга
По данным, раскрытым сообществом:
| Место | Решение | Примечание |
|---|---|---|
| 1 | Claude Code + Opus 4.7 | На текущий момент сильнейшая комбинация для рефакторинга |
| 2+ | Другие кодинговые агенты | Полные баллы ожидаются от официального релиза |
Полный лидерборд всё ещё публикуется. Но то, что Claude Code занял первое место, само по себе заслуживает обсуждения.
Opus 4.7 уже доказал свои способности к программированию на SWE-Bench (82 балла), но первое место в рефакторинге — сценарии, гораздо ближе к повседневной разработке — говорит о том, что его понимание кода и структурное мышление действительно на полступени выше конкурирующих моделей.
При этом данные BridgeBench также показывают, что Opus 4.7 — «игрок рефакторинга» — тесты показывают, что он лидирует и на рефакторинговом треке BridgeBench, в то время как GPT-5.5 даже не появляется в этом лидерборде. Это не значит, что GPT-5.5 слабый; просто у разных моделей разные сильные стороны.
Что означает этот бенчмарк
Появление SWE Atlas сигнализирует о тренде: оценка агентов смещается от «может ли он выполнить задачу» к «может ли он сделать работу хорошо».
SWE-Bench измеряет «может ли он исправить issue». SWE Atlas измеряет «может ли он превратить кучу легаси-кода во что-то читаемое». Второе ближе к 70% того, что инженеры делают каждый день.
Для команд, выбирающих инструменты-агенты, если ваш сценарий — поддержка старых проектов, миграция технологического стека или модернизация кода — результаты SWE Atlas более релевантны, чем SWE-Bench.
Ещё не всё
Этот бенчмарк только запущен, и полный лидерборд и методология всё ещё публикуются. За чем стоит следить: опубликует ли Scale AI тестовые кейсы и детали скоринга — если она откроет тестовый набор, как это сделал SWE-Bench, доверие к бенчмарку значительно вырастет.
При следующем обновлении SWE Atlas я буду следить за двумя вещами: догонит ли GPT-5.5 в рефакторинге и как китайские кодинговые агенты (GLM-5.1, серия Qwen3.6) выступят на этом бенчмарке.
Источники:
- Официальный анонс Scale AI
- Обсуждения лидерборда в сообществе