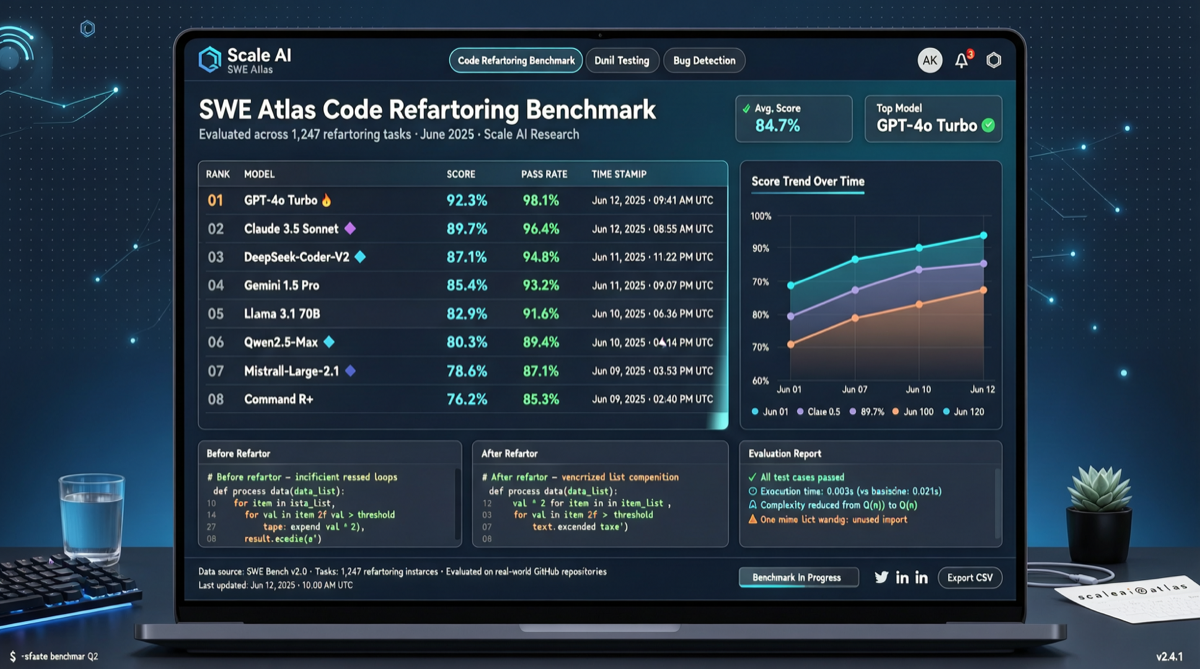
SWE-Benchの後に、ようやくソフトウェアエンジニアリングで一番泥臭いパート——リファクタリング——に注目するベンチマークが登場した。
Scale AIがSWE Atlas Refactoring Leaderboardを発表した。AI Agentのコードリファクタリング能力に特化した初のベンチマークだ。SWE-Benchの「バグを1つ修正する」タスクとは異なり、リファクタリングは既存のコードベースに対して構造的な変更を行い、SWE-Bench Proの2倍以上のコード量を产出する必要がある。
結果は予想通りでありつつも興味深い:Claude CodeとOpus 4.7の組み合わせが1位。だが2位は誰か、各モデルの差はどれくらいか、このベンチマークが実際に何を測定しているか——そこに本当の物語がある。
リファクタリングがバグ修正より難しい理由
バグ修正は「問題を見つけて、1行変えて、テストを実行する」。リファクタリングは「大量の古いコードを読み、設計意図を理解し、動作を壊さずに構造を組み直す」ことだ。
SWE Atlasの難しさ:
- コード量が多い:Agentはモジュール単位、場合によってはリポジトリ全体のリファクタリングタスクを処理する必要がある
- 動作の保持:リファクタリング後のコードは既存の全テストに合格する必要がある——これは絶対条件だ
- 产出量が2倍:SWE-Bench Proより2倍のコード量を要求されるということは、数行の修正ではなく構造的な変更が必要だということ
言い換えれば、これは「コードセンス」を測るベンチマークだ。悪いコードを良くできるか、同時に新しいバグを導入しないか。
ランキング結果
コミュニティで公開されている情報によると:
| 順位 | ソリューション | 備考 |
|---|---|---|
| 1 | Claude Code + Opus 4.7 | 現在最強のリファクタリング組み合わせ |
| 2+ | その他のコーディングAgent | 詳細スコアは公式発表待ち |
完全なリーダーボードは順次公開中。しかしClaude Codeが1位を取ったこと自体、議論する価値がある。
Opus 4.7はSWE-Benchですでにプログラミング能力を証明している(スコア82)が、日常の開発により近いリファクタリングのシナリオで1位を取ったということは、コード理解力と構造的思考力が競合モデルより確かに半歩上にあることを示している。
ただし、BridgeBenchのデータもOpus 4.7が「リファクタリング型プレイヤー」であることを示している——BridgeBenchのリファクタリングトラックでも领先しており、GPT-5.5はこのリーダーボードに登場すらしていない。GPT-5.5が弱いという意味ではなく、モデルによって得意分野が違うということだ。
このベンチマークが意味すること
SWE Atlasの登場は1つのトレンドを示している:Agent評価が「タスクを完了できるか」から「仕事をきれいにできるか」へ移行している。
SWE-Benchは「issueを修正できるか」を測る。SWE Atlasは「レガシーコードの山を読める形にできるか」を測る。後者はエンジニアが毎日やる仕事の70%に近い。
チームがAgentツールを選ぶ際、古いプロジェクトのメンテナンス、技術スタックの移行、コードのモダナイゼーションがユースケースなら、SWE Atlasの結果はSWE-Benchより参考になる。
まだ終わらない
このベンチマークは刚刚発表されたばかりで、完全なリーダーボードと方法論はまだ公開中だ。注目すべきは、Scale AIがテストケースとスコアリングの詳細を公開するかどうか——SWE-Benchのようにテストスイートをオープンソース化すれば、このベンチマークの信頼性は大幅に向上する。
次回のSWE Atlasアップデートでは、GPT-5.5がリファクタリングで追いつけるか、そして中国のコーディングAgent(GLM-5.1、Qwen3.6シリーズ)がどの程度のパフォーマンスを出すかの2点に注目する。
主要ソース:
- Scale AI公式発表
- コミュニティリーダーボードディスカッションスレッド