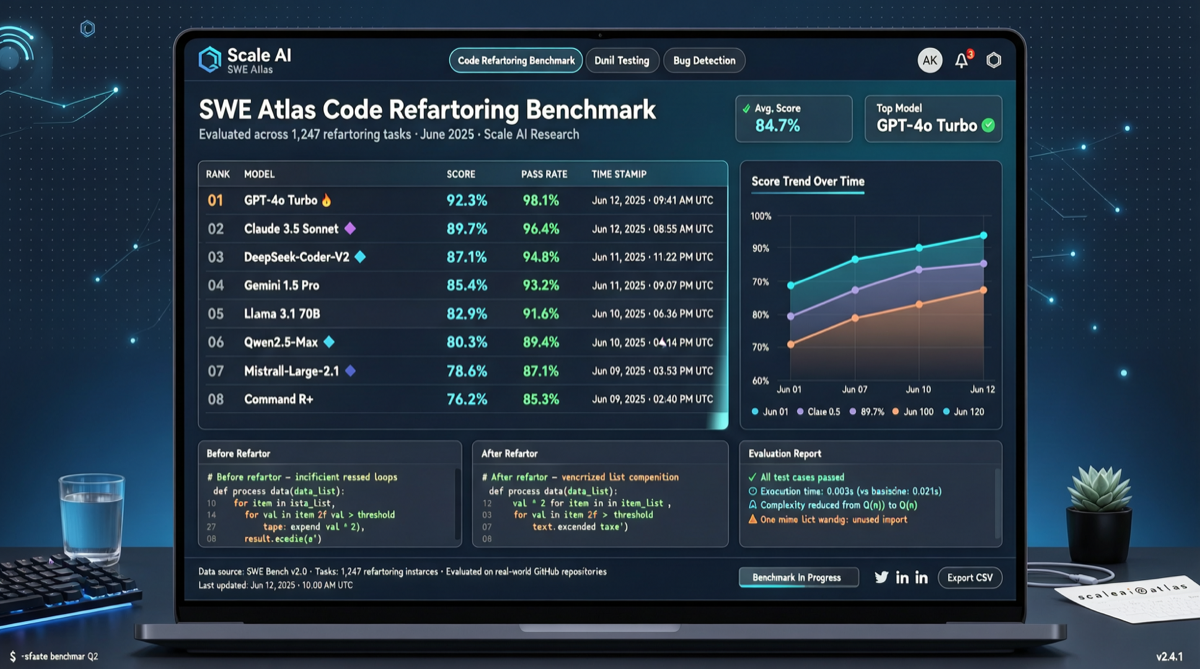
SWE-Bench 之后,Agent 评测终于有人开始盯"重构"这个脏活了。
Scale AI 刚发布了 SWE Atlas Refactoring Leaderboard——这是第一个专门评估 AI Agent 代码重构能力的新基准。跟 SWE-Bench 那种"修一个 bug"的任务不一样,重构要求 Agent 对已有代码做结构性改造,产出的代码量是 SWE-Bench Pro 的两倍以上。
结果不意外也不无聊:Claude Code 搭配 Opus 4.7 排第一。但第二名是谁、各家差距多大、这个基准到底测的是什么,才是值得看的部分。
重构比修 bug 难在哪
修 bug 是"找到问题、改一行、跑测试"。重构是"读懂一大坨旧代码,理解设计意图,然后在不破坏行为的前提下重新组织结构"。
SWE Atlas 的难点在于:
- 代码量大:Agent 需要处理整个模块甚至整个仓库级别的重构任务
- 保持行为不变:重构后的代码必须通过原有全部测试,这是硬约束
- 产出量翻倍:比 SWE-Bench Pro 要求多写一倍的代码,意味着不只是改几行,而是结构性改动
换句话说,这是一个测"代码品味"的基准。你能不能把烂代码改好,同时不引入新 bug。
榜单结果
根据社区披露的信息:
| 排名 | 方案 | 说明 |
|---|---|---|
| 1 | Claude Code + Opus 4.7 | 当前重构能力最强组合 |
| 2+ | 其他编码 Agent | 具体分数待官方完整发布 |
官方完整榜单还在陆续放出中。但 Claude Code 拿第一这件事本身值得多说两句。
Opus 4.7 在 SWE-Bench 上已经证明过自己的编程能力(82 分),但在重构这个更贴近日常开发的场景里拿第一,说明它的代码理解力和结构化思维能力确实比其他模型高半个身位。
不过,BridgeBench 上的数据也显示 Opus 4.7 是"重构型选手"——有人测试过它在 BridgeBench 重构赛道上同样领先,而 GPT-5.5 在这个榜单上甚至没出现。这不代表 GPT-5.5 弱,只是说不同模型确实有不同的发力点。
这个基准的意义
SWE Atlas 的出现说明了一个趋势:Agent 评测正在从"能不能完成任务"走向"能不能把活干漂亮"。
SWE-Bench 测的是"能不能修好一个 issue"。SWE Atlas 测的是"能不能把一坨 legacy code 改成你能看懂的样子"。后者更接近工程师日常 70% 的工作内容。
对于团队选 Agent 工具来说,如果你的场景是维护老项目、迁移技术栈、或者做代码现代化,SWE Atlas 的结果比 SWE-Bench 更有参考价值。
还没完
这个基准刚发布,完整榜单和方法论还在释放中。值得关注的是 Scale AI 会不会公开测试用例和评分细节——如果像 SWE-Bench 那样开源测试集,这个基准的公信力会大幅上升。
下一次 SWE Atlas 更新,我主要看两件事:GPT-5.5 能不能在重构赛道追上来,以及国产编码 Agent(GLM-5.1、Qwen3.6 系列)在这个基准上的表现如何。
主要来源:
- Scale AI 官方推文
- 社区榜单讨论线程