结论
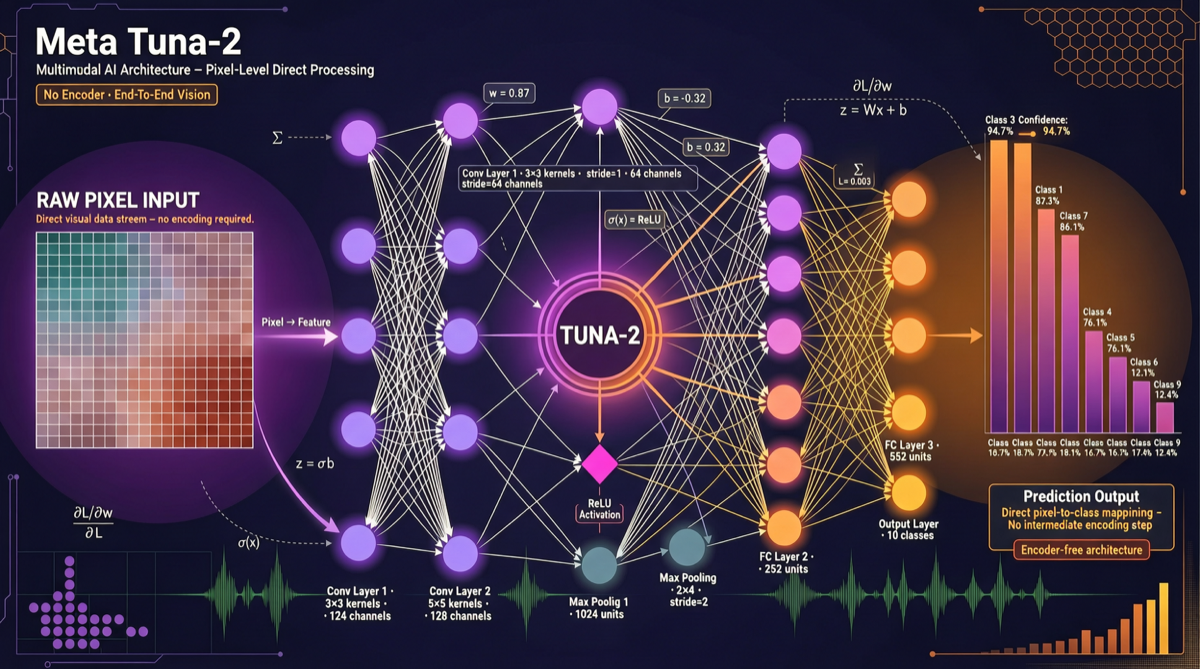
Meta 的 Tuna-2 走了一条激进的技术路线:完全抛弃视觉编码器(Vision Encoder)和 VAE,直接用像素嵌入(Pixel Embeddings)处理多模态任务。这在细粒度感知任务上超越了传统编码器方案,并且统一了理解和生成能力。对于需要高精度视觉理解的应用场景,Tuna-2 值得关注。
痛点:传统多模态模型的”编码器税”
当前主流多模态模型(GPT-4o、Claude、Gemini)的架构几乎都遵循同一模式:
输入图像 → Vision Encoder(提取特征)→ VAE(压缩表示)→ LLM(理解/生成)这条路线有两个固有缺陷:
- 信息损失:编码器和 VAE 的压缩过程必然丢失细粒度视觉信息
- 架构割裂:视觉理解和图像生成需要两套不同的处理流程
Tuna-2 的解决方案是:砍掉中间层,让模型直接处理像素。
Tuna-2 方案详解
核心架构
| 组件 | 传统方案 | Tuna-2 |
|---|---|---|
| 视觉编码 | CLIP/SigLIP 等编码器 | 无编码器 |
| 图像压缩 | VAE 潜空间 | 直接像素嵌入 |
| 理解+生成 | 分离架构 | 统一架构 |
| 细粒度感知 | 编码器瓶颈 | 像素级精度 |
关键技术点
-
像素嵌入替代编码器
- 图像直接切分为 patch embeddings
- 不需要预训练的视觉编码器
- 保留了原始像素级别的细粒度信息
-
统一的理解与生成
- 同一架构既做多模态理解,也做图像生成
- 不需要为不同任务切换模型
-
性能表现
- 在细粒度感知基准上 超越编码器方案
- MoE 架构保证推理效率
- 可扩展性强,参数规模灵活
与同期多模态方案的横向对比
| 模型 | 架构 | 理解 | 生成 | 开源 | 特色 |
|---|---|---|---|---|---|
| Tuna-2 (Meta) | 无编码器+像素嵌入 | ✅ | ✅ | ✅ | 细粒度感知领先 |
| LLaDA2.0-Uni | 扩散 LLM+MoE | ✅ | ✅ | ✅ | 8 步图像生成 |
| SenseNova U1 | 单体多模态 | ✅ | ✅ | ✅ | 统一架构 |
| Nemotron 3 Nano Omni | 多模态融合 | ✅ | ✅ | ✅ | 视频/音频/文本 |
| GPT-Image-2 | LLM token-by-token | ✅ | ✅ | ❌ | 商业闭源 |
为什么选择无编码器路线?
编码器的历史包袱
视觉编码器(如 CLIP)本质上是在做”信息有损压缩”——把几百万像素的图像压缩成几千维的向量。这个过程对分类任务够用,但对需要细粒度理解的任务(如:识别 UI 元素位置、读取表格中的小数字、区分相似物体)就不够了。
Tuna-2 的思路类似于 Llama.cpp 绕过云端 API 直接本地推理:去掉中间商,直达源数据。
什么时候该用 Tuna-2
| 场景 | 推荐度 | 理由 |
|---|---|---|
| UI 截图解析 | ⭐⭐⭐⭐⭐ | 像素级精度,位置识别准确 |
| 表格 OCR+理解 | ⭐⭐⭐⭐⭐ | 细粒度文字识别强 |
| 医疗影像分析 | ⭐⭐⭐⭐ | 需要像素级精度 |
| 通用对话+看图 | ⭐⭐⭐ | 通用任务编码器方案也够用 |
| 艺术创作 | ⭐⭐ | LLaDA2.0-Uni 的扩散生成可能更合适 |
上手指南
快速获取
- GitHub 仓库:搜索 Meta Tuna-2 官方仓库
- Hugging Face 模型:已上传开源权重
- 依赖:PyTorch + 对应 MoE 推理框架
- 硬件需求:取决于具体参数量,建议至少 24GB 显存
与现有工具链集成
# 典型的集成路径
Tuna-2 模型
↓ (通过 OpenAI 兼容 API)
OpenClaw / Hermes Agent / LangChain
↓
你的业务应用由于是多模态理解+生成统一模型,可以作为:
- Agent 的视觉感知模块
- 文档/表格理解引擎
- 图像生成后端
格局判断
Tuna-2 代表了多模态 AI 的一个分支方向:端到端像素处理。与 LLaDA2.0-Uni 的扩散路线、SenseNova U1 的单体架构形成三足鼎立。短期内,传统编码器方案仍是主流;但中长期看,如果像素嵌入路线能证明可扩展性,它可能成为下一代多模态基础架构。