Key Findings
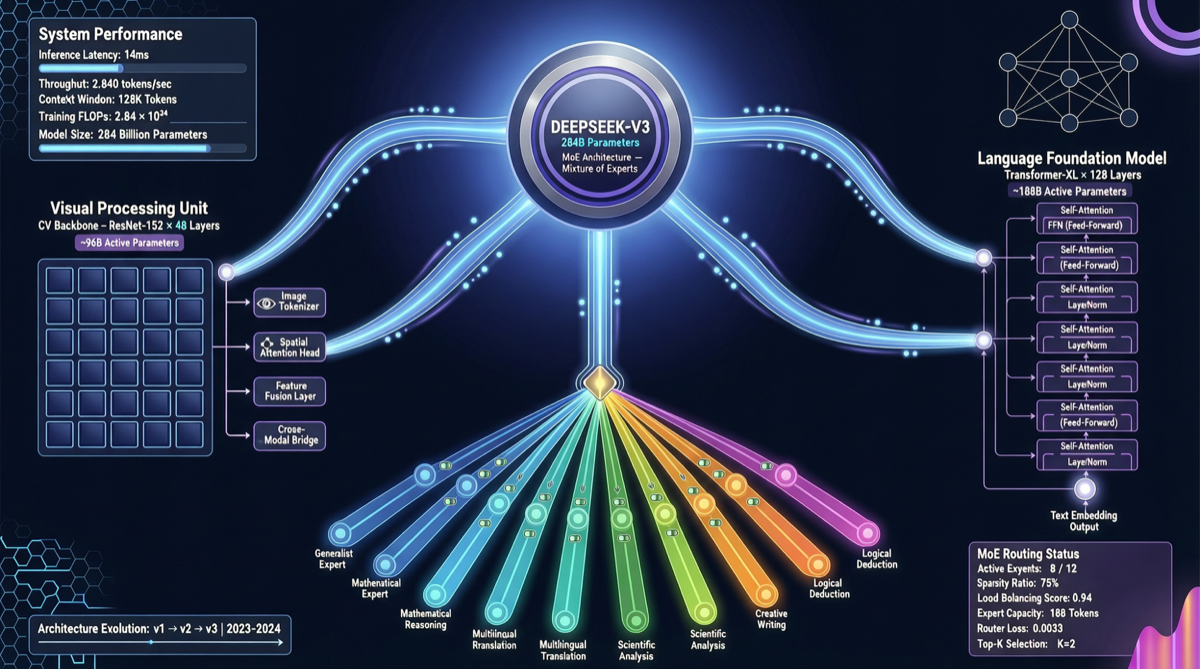
At the end of April, DeepSeek released the multimodal large language model paper “Thinking with Visual Primitives,” revealing the technical details of its unified vision-language architecture. Built upon the DeepSeek-V4-Flash MoE foundation (284B total parameters, 13B activated) and equipped with a proprietary DeepSeek-ViT visual encoder, it marks a significant shift for domestic multimodal models from “stitched approaches” toward “native architectures.”
Technical Architecture Breakdown
| Component | Specifications | Key Design |
|---|---|---|
| Language Foundation | DeepSeek-V4-Flash | 284B total parameters / 13B activated, MoE architecture |
| Visual Encoder | DeepSeek-ViT | 14×14 patch division, 3×3 spatial compression before feeding into the LLM |
| Modality Fusion | Native token alignment | Visual features directly mapped to language tokens, eliminating the need for cross-modal projection layers |
| Reasoning Mode | Supports thinking | Chain-of-thought reasoning enabled for visual tasks as well |
Key Innovations in the Visual Encoder
DeepSeek-ViT adopts a 14×14 patch division strategy, similar to traditional ViTs, but adds a 3×3 spatial compression step after the output. This design significantly reduces the number of visual tokens, alleviating computational bottlenecks during long-sequence inference—which is particularly crucial when processing high-resolution images.
Comparison with mainstream approaches:
| Approach | Visual Encoding Strategy | Token Compression Ratio | Inference Latency |
|---|---|---|---|
| DeepSeek-ViT | 14×14 patch + 3×3 spatial compression | High | Low |
| Qwen2-VL | Dynamic resolution | Medium | Medium |
| LLaVA-OneVision | Fixed patch | Low | High |
| InternVL | Multi-scale features | Medium | Medium |
What Do “Visual Primitives” Mean?
The “Visual Primitives” in the paper’s title refers to the model’s approach of breaking down visual information into basic visual units (primitives) for reasoning, rather than simply encoding images into fixed vectors. This design allows the model to perform fine-grained operations on visual features during inference, similar to how humans first identify basic elements (edges, shapes, colors) when observing an image before combining them into high-level semantic understanding.
Why It Matters
1. A Pioneer in Multimodal MoE
While most open-source multimodal models adopt dense architectures, DeepSeek is the first to successfully apply the MoE architecture to multimodal scenarios. With 284B total parameters but only 13B activated, it means that while maintaining powerful visual comprehension capabilities, inference costs are kept within an acceptable range.
2. A Signal of an Open-Source Strategy
The publication of this paper indicates that DeepSeek is continuing its consistent open-source strategy. If the model weights are subsequently released, it will become one of the largest open-source multimodal MoE models by parameter count to date, directly competing for the market niche occupied by Qwen2-VL and InternVL.
3. Connection to the V4 Release Timeline
The DeepSeek V4 text model was released in late April but received a lukewarm market response. The release of this multimodal paper suggests that DeepSeek’s product matrix is expanding from a single text model to multimodal capabilities—potentially a strategy for differentiated competition.
Actionable Recommendations
- Researchers: Focus on the methodology section of the paper, particularly the design of visual token compression and MoE routing in multimodal scenarios
- Developers: Once the weights are released, compare its performance against Qwen2-VL on the same benchmarks
- Enterprise Users: It is advisable to wait at this stage and consider integrating it into production workflows only after community evaluations mature
If DeepSeek’s technical route this time—MoE + native visual encoding + open source—can be materialized into usable model weights, it will drop a bombshell in the competition among domestic multimodal models.